
该内容为基于PaddleNLP和Paddle框架的OCEMOTION中文情感分类任务实现。先切分数据集为训练、测试、评估集,转换标签格式;定义数据集类处理数据,经 Jieba 切词、映射词id等处理;构建含嵌入层、LSTM编码器等的模型,配置优化器等训练模型,最终对测试集预测,输出情感分类结果。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

情感分类
情感分类简单的正负,但是细分就太多了太多了。。。
sadnesshappinessdisgustlikeangersurprisefear
结果如下:
Data: 【旅游】美食:滇南地区建水的蕈芽、石屏的豆腐、蒙自的过桥米线。滇东北地区菜豆花、连渣搞、酸辣鸡等。滇西地区的大理沙锅鱼、酸辣鱼。丽江粑粑、八大碗。弥渡的卷蹄、风吹肝、腾冲的大救驾,各种凉拌野菜、松尖等。关注【游遍云南】公众微信,让您畅游云南,游遍云南公众微信号:y4000119001 Label: happinessData: 想哭, Label: sadnessData: 自己打的赌,赌的很大,不知道自己到底战绩怎样 Label: disgustData: 4…这都不是偶然的事情,这是他明白这个事实真相,对生死看得很淡薄,知道要认真努力修行,所以死了之后,自己可以作主,自己可以选择到哪一道去。如果在临终时,一慌一乱,你对身体很留恋,对家亲眷属很留恋,那你往往就到三途去了! Label: happinessData: 干了这碗香菜我们是好朋友 Label: disgustData: 韩国沉船遇难者’不愿分离’。一男生一女生害怕被水冲开分离紧捆绑在一起。[蜡烛][蜡烛][蜡烛] Label: happinessData: 那一年,cang井空还是处女,冠希还没有相机,李刚还没有儿子,菊花只是一种花,企鹅不是qq,2b我只知道是铅笔,买方便面还有调料,杯具只是用来刷牙,楼房是用来住的,黄瓜香蕉只是用来吃的,教授还不是叫兽,太阳还不叫日,领导不会写日记,鸭梨还没有这么大,肚子大了也知道是谁的我们还相信真情 Label: sadnessData: 小孩子会说谎,大孩子也会说谎,不过,美名其曰为“借口”,不努力,是因为没了目标,没了动力,习惯了堕落。。。 Label: sadnessData: 特困户的春天[拜拜] Label: sadnessData: 找院长写推荐信之前把自我介绍想过很多遍,结果院长大人没有赴约;从早到晚在实验室忙碌只为了按时完成实验,结果教授将实验计划改变;纠结了好久今天终于鼓起勇气再加一次某人的微信,结果我貌似在黑名单里面……总以为解决了自己就解决了一切,但是没想到,事情总是有想不懂到的一面。 Label: disgust
OCEMOTION:是包含7个分类的细粒度情感性分析数据集,如下所示:
0 你知道多伦多附近有什么吗?哈哈有破布耶…真的书上写的你听哦…你家那块破布是世界上最大的破布,哈哈,骗你的啦它是说尼加拉瓜瀑布是世界上最大的瀑布啦…哈哈哈”爸爸,她的头发耶!我们大扫除椅子都要翻上来我看到木头缝里有头发…一定是xx以前夹到的,你说是不是?[生病] sadness1 平安夜,圣诞节,都过了,我很难过,和妈妈吵了两天,以死相逼才终止战争,现在还处于冷战中。sadness2 我只是自私了一点,做自己想做的事情! sadness3 让感动的不仅仅是雨过天晴,还有泪水流下来的迷人眼神。happiness4 好日子 happiness
(注:id 句子 标签)
In [ ]
评测方案
参赛选手仅可使用单模型,先求出每个任务的macro f1,然后在三个任务上取平均值,具体计算公式如下:
##计算公式:
名称 说明 TP(True Positive) 真阳性:预测为正,实际也为正 FP(False Positive) 假阳性:预测为正,实际为负 FN(False Negative) 假阴性:预测与负、实际为正 TN(True Negative) 真阴性:预测为负、实际也为负 P(Precision) 精确率 P = TP/(TP+FP) R(Recall) 召回率 R = TP/(TP+FN) F(f1-score) F-值 F = 2PR/(P+R) macro f1 需要先计算出每一个类别的准召及其f1 score,然后通过求均值得到在整个样本上的f1 score。
https://tianchi.aliyun.com/competition/entrance/531841/information
OCEMOTION–中文情感分类
此次跟着陈硕老师走,先跑一圈
情感分析是自然语言处理领域一个老生常谈的任务。句子情感分析目的是为了判别说者的情感倾向,比如在某些话题上给出的的态度明确的观点,或者反映的情绪状态等。情感分析有着广泛应用,比如电商评论分析、舆情分析等。

label_map={"sadness":'0', "happiness":'1',"disgust":'2',"like":'3',"anger":'4',"surprise":'5',"fear":'6'}
In [ ]
# 下载paddlenlp!pip install --upgrade paddlenlp==2.0.0b4
数据集
OCEMOTION–数据集介绍
0 你知道多伦多附近有什么吗?哈哈有破布耶…真的书上写的你听哦…你家那块破布是世界上最大的破布,哈哈,骗你的啦它是说尼加拉瓜瀑布是世界上最大的瀑布啦…哈哈哈”爸爸,她的头发耶!我们大扫除椅子都要翻上来我看到木头缝里有头发…一定是xx以前夹到的,你说是不是?[生病] sadness1 平安夜,圣诞节,都过了,我很难过,和妈妈吵了两天,以死相逼才终止战争,现在还处于冷战中。sadness2 我只是自私了一点,做自己想做的事情! sadness3 让感动的不仅仅是雨过天晴,还有泪水流下来的迷人眼神。happiness4 好日子 happiness
自定义数据集OCEMOTION–中文情感分类 https://aistudio.baidu.com/aistudio/projectdetail/1416938
PaddleNLP和Paddle框架是什么关系?

Paddle框架是基础底座,提供深度学习任务全流程API。PaddleNLP基于Paddle框架开发,适用于NLP任务。
PaddleNLP中数据处理、数据集、组网单元等API未来会沉淀到框架paddle.text中。
代码中继承 class TSVDataset(paddle.io.Dataset)
使用飞桨完成深度学习任务的通用流程
数据集和数据处理
paddle.io.Dataset
paddle.io.DataLoader
paddlenlp.data
组网和网络配置
paddle.nn.Embedding
paddlenlp.seq2vec paddle.nn.Linear
paddle.tanh
paddle.nn.CrossEntropyLoss
paddle.metric.Accuracy
paddle.optimizer
model.prepare
网络训练和评估
model.fit
model.evaluate
 mybatis语法和介绍 中文WORD版
mybatis语法和介绍 中文WORD版
本文档主要讲述的是mybatis语法和介绍;MyBatis 是一个可以自定义SQL、存储过程和高级映射的持久层框架。MyBatis 摒除了大部分的JDBC代码、手工设置参数和结果集重获。MyBatis 只使用简单的XML 和注解来配置和映射基本数据类型、Map 接口和POJO 到数据库记录。相对Hibernate和Apache OJB等“一站式”ORM解决方案而言,Mybatis 是一种“半自动化”的ORM实现。感兴趣的朋友可
 2 查看详情
2 查看详情 
预测 model.predict
注意:建议在GPU下运行。
In [ ]
# 解压数据%cd ~!unzip data/data66630/NLP中文预训练模型泛化能力挑战赛.zip -d dataset
/home/aistudioArchive: data/data66630/NLP中文预训练模型泛化能力挑战赛.zip inflating: dataset/OCEMOTION_a.csv inflating: dataset/OCEMOTION_train1128.csv inflating: dataset/OCNLI_a.csv inflating: dataset/OCNLI_train1128.csv inflating: dataset/TNEWS_a.csv inflating: dataset/TNEWS_train1128.csv
In [ ]
import paddleimport paddlenlpprint(paddle.__version__, paddlenlp.__version__)
2.0.0 2.0.0b4
1.3 数据集切分
In [ ]
import osfrom sklearn.model_selection import train_test_splitimport pandas as pdimport numpy as np
In [ ]
def break_data(target, rate=0.2): origin_dataset = pd.read_csv("dataset/OCEMOTION_train1128.csv", delimiter="t", header=None) # 加入参数 train_data, test_data = train_test_split(origin_dataset, test_size=rate) train_data,eval_data=train_test_split(train_data, test_size=rate) train_filename = os.path.join(target, 'train.txt') test_filename = os.path.join(target, 'test.txt') eval_filename = os.path.join(target, 'eval.txt') train_data.to_csv(train_filename, index=False, sep="t", header=None) test_data.to_csv(test_filename, index=False, sep="t", header=None) eval_data.to_csv(eval_filename, index=False, sep="t", header=None)if __name__ == '__main__': break_data(target='dataset', rate=0.2)
In [ ]
%cd ~/dataset/
/home/aistudio/dataset
In [ ]
label_map={"sadness":'0', "happiness":'1',"disgust":'2',"like":'3',"anger":'4',"surprise":'5',"fear":'6'}
In [ ]
import pandas as pddef modify_data(target='.'): for name in ['train','test','eval']: source_file=os.path.join(target, name + '.txt') target_file=os.path.join(target, name + '.csv') data=pd.read_csv(source_file, delimiter="t", header=None) new_data=data[[1,2]] new_data.replace(label_map, inplace=True) new_data.to_csv(target_file, index=False, sep="t", header=None) new_data=None data=Noneif __name__ == '__main__': modify_data()
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/pandas/core/frame.py:3798: SettingWithCopyWarning: A value is trying to be set on a copy of a slice from a DataFrameSee the caveats in the documentation: http://pandas.pydata.org/pandas-docs/stable/indexing.html#indexing-view-versus-copy method=method)
In [ ]
!head train.csv
以前的一位同事和女朋友在一起了很多年,马上就结婚了!今天看到他上传的结婚照,新娘竟然不是她,而是公司的另一同事......现在的情感到底都是闹那样???5那种感觉真美好如果你也对我那样就好了♥3在元旦放假的前一天我们进行考试,远旦放假回来的头一天我们又要考试...每天考考考,做为高三的学生我们容易嘛。『明天的考试只能尽力了』0其实不幸福,只是一比较就幸福了1觉得自己太聪明也就会变傻噜。1我非常讨厌加工作q但是不知道怎么拒绝,毕竟已经拒绝了微信4非诚勿扰告诉我们:身为一个中国女性,无论你再怎么学历牛x、工作拼命、容颜姣好,到了年龄嫁不出去,就不得不穿的像驻马店洗浴中心的工作人员一样,站成一排会见各种奇葩,然后在三分钟的速食相亲之后假装找到真爱。。。2为了塞spn的con还有早餐会删掉了一堆喜欢的剧集存档......波吉亚家族嘤嘤嘤嘤嘤......【看起了蓝光碟【够。0希望每天1要是我没记错的话,我qian包里好像多了两百[挖鼻]5
In [ ]
!head test.csv
【旅游】美食:滇南地区建水的蕈芽、石屏的豆腐、蒙自的过桥米线。滇东北地区菜豆花、连渣搞、酸辣鸡等。滇西地区的大理沙锅鱼、酸辣鱼。丽江粑粑、八大碗。弥渡的卷蹄、风吹肝、腾冲的大救驾,各种凉拌野菜、松尖等。关注【游遍云南】公众微信,让您畅游云南,游遍云南公众微信号:y40001190011想哭,0自己打的赌,赌的很大,不知道自己到底战绩怎样04...这都不是偶然的事情,这是他明白这个事实真相,对生死看得很淡薄,知道要认真努力修行,所以死了之后,自己可以作主,自己可以选择到哪一道去。如果在临终时,一慌一乱,你对身体很留恋,对家亲眷属很留恋,那你往往就到三途去了!6干了这碗香菜我们是好朋友1韩国沉船遇难者'不愿分离'。一男生一女生害怕被水冲开分离紧捆绑在一起。[蜡烛][蜡烛][蜡烛]1那一年,cang井空还是处女,冠希还没有相机,李刚还没有儿子,菊花只是一种花,企鹅不是qq,2b我只知道是铅笔,买方便面还有调料,杯具只是用来刷牙,楼房是用来住的,黄瓜香蕉只是用来吃的,教授还不是叫兽,太阳还不叫日,领导不会写日记,鸭梨还没有这么大,肚子大了也知道是谁的我们还相信真情1小孩子会说谎,大孩子也会说谎,不过,美名其曰为“借口”,不努力,是因为没了目标,没了动力,习惯了堕落。。。3特困户的春天[拜拜]1找院长写推荐信之前把自我介绍想过很多遍,结果院长大人没有赴约;从早到晚在实验室忙碌只为了按时完成实验,结果教授将实验计划改变;纠结了好久今天终于鼓起勇气再加一次某人的微信,结果我貌似在黑名单里面......总以为解决了自己就解决了一切,但是没想到,事情总是有想不懂到的一面。2
In [ ]
!head eval.csv
我告诉自己,要独立,要坚强,要勇敢,要活的漂亮,要让自己永远善良。1人的自信无缘就是来自二种情况一是有钱二是有本事你们说是吗?????????????218.粗一我们是一个学校同宿舍你是我上铺哟老是欺负我!!!是同胞啊嘿嘿内涵你懂。是品味不错的妹子还是大富逼!!总是给我礼物小惊喜啊啥的比如好吃的还有轻松熊本子还有美国带回来的杂志,射射你噜。看样子大学你是要粗国念噜别忘了我啊有空寄明信片啊好吃的好玩的给我不谢!!有缘再见咯高中加油!!3这说什么好呢?学校终于给放假啦!!开心死我了!!哈哈1愿沐儿天天开心~1如果你给不了幸福她,就请你不要伤害她,这样对彼此的伤害会更大。0前排的电车单车都倒地,纠结很久还是决定一辆辆扶起。一电车突然亮灯,一男生走过来,我赶紧解释不是我弄的!男生我知道。心里有点好奇,这哥们太善解人意了,抬头一看那男生,原来刚才走在后面的人不就是他么。倒车的时候,路太窄,我不小心又撞到后面的车,那哥们看了我一眼,继续心疼他的车...0我说那样的话真该死。0害怕失败,容易恐惧,逃避竞争。0当发现一些不该发现的事的时候,她就会下楼,说,还是睡觉吧。5
In [ ]
train_data=pd.read_csv("train.csv", delimiter="t", header=None) print("train_data length: ",train_data.size)test_data=pd.read_csv("test.csv", delimiter="t", header=None) print("test_data length: ",test_data.size)eval_data=pd.read_csv("eval.csv", delimiter="t", header=None) print("eval_data length: ",eval_data.size)df1=train_data[1].value_counts()print(df1)
train_data length: 45196test_data length: 14126eval_data length: 113000 78871 57762 27503 26424 26405 5446 359Name: 1, dtype: int64
In [ ]
%cd ~/dataset/
/home/aistudio/dataset
In [1]
print(label_map)
自定义数据集
映射式(map-style)数据集需要继承paddle.io.Dataset
__getitem__: 根据给定索引获取数据集中指定样本,在 paddle.io.DataLoader 中需要使用此函数通过下标获取样本。
__len__: 返回数据集样本个数, paddle.io.BatchSampler 中需要样本个数生成下标序列。
In [ ]
class SelfDefinedDataset(paddle.io.Dataset): def __init__(self, data): super(SelfDefinedDataset, self).__init__() self.data = data def __getitem__(self, idx): return self.data[idx] def __len__(self): return len(self.data) def get_labels(self): return ['0','1','2','3','4','5','6']def txt_to_list(file_name): res_list = [] for line in open(file_name): res_list.append(line.strip().split('t')) return res_listtrainlst = txt_to_list('train.csv')devlst = txt_to_list('eval.csv')testlst = txt_to_list('test.csv')# 通过get_datasets()函数,将list数据转换为dataset。# get_datasets()可接收[list]参数,或[str]参数,根据自定义数据集的写法自由选择。# train_ds, dev_ds, test_ds = ppnlp.datasets.ChnSentiCorp.get_datasets(['train', 'dev', 'test'])train_ds, dev_ds, test_ds = SelfDefinedDataset.get_datasets([trainlst, devlst, testlst])
In [ ]
label_list = train_ds.get_labels()print(label_list)for i in range(10): print (train_ds[i])
['0', '1', '2', '3', '4', '5', '6']['以前的一位同事和女朋友在一起了很多年,马上就结婚了!今天看到他上传的结婚照,新娘竟然不是她,而是公司的另一同事......现在的情感到底都是闹那样???', '5']['那种感觉真美好如果你也对我那样就好了♥', '3']['在元旦放假的前一天我们进行考试,远旦放假回来的头一天我们又要考试...每天考考考,做为高三的学生我们容易嘛。『明天的考试只能尽力了』', '0']['其实不幸福,只是一比较就幸福了', '1']['觉得自己太聪明也就会变傻噜。', '1']['我非常讨厌加工作q但是不知道怎么拒绝,毕竟已经拒绝了微信', '4']['非诚勿扰告诉我们:身为一个中国女性,无论你再怎么学历牛x、工作拼命、容颜姣好,到了年龄嫁不出去,就不得不穿的像驻马店洗浴中心的工作人员一样,站成一排会见各种奇葩,然后在三分钟的速食相亲之后假装找到真爱。。。', '2']['为了塞spn的con还有早餐会删掉了一堆喜欢的剧集存档......波吉亚家族嘤嘤嘤嘤嘤......【看起了蓝光碟【够。', '0']['希望每天', '1']['要是我没记错的话,我qian包里好像多了两百[挖鼻]', '5']
数据处理
为了将原始数据处理成模型可以读入的格式,本项目将对数据作以下处理:
首先使用jieba切词,之后将jieba切完后的单词映射词表中单词id。
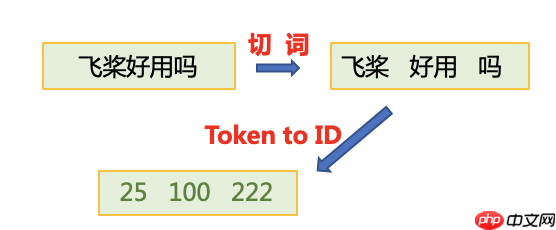
使用paddle.io.DataLoader接口多线程异步加载数据。
其中用到了PaddleNLP中关于数据处理的API。PaddleNLP提供了许多关于NLP任务中构建有效的数据pipeline的常用API
paddlenlp.data.Stack堆叠N个具有相同shape的输入数据来构建一个batch,它的输入必须具有相同的shape,输出便是这些输入的堆叠组成的batch数据。paddlenlp.data.Pad堆叠N个输入数据来构建一个batch,每个输入数据将会被padding到N个输入数据中最大的长度paddlenlp.data.Tuple将多个组batch的函数包装在一起
更多数据处理操作详见: https://github.com/PaddlePaddle/PaddleNLP/blob/develop/docs/data.md
In [ ]
# 下载词汇表文件word_dict.txt,用于构造词-id映射关系。from utils import load_vocab, convert_example# !wget https://paddlenlp.bj.bcebos.com/data/senta_word_dict.txt# 加载词表vocab = load_vocab('./senta_word_dict.txt')for k, v in vocab.items(): print(k, v) break
[PAD] 0
In [ ]
import numpy as npfrom functools import partialimport paddle.nn as nnimport paddle.nn.functional as Fimport paddlenlp as ppnlpfrom paddlenlp.data import Pad, Stack, Tuplefrom paddlenlp.datasets import MapDatasetWrapperfrom utils import load_vocab, convert_example
构造dataloder
下面的create_data_loader函数用于创建运行和预测时所需要的DataLoader对象。
paddle.io.DataLoader返回一个迭代器,该迭代器根据batch_sampler指定的顺序迭代返回dataset数据。异步加载数据。
batch_sampler:DataLoader通过 batch_sampler 产生的mini-batch索引列表来 dataset 中索引样本并组成mini-batch
collate_fn:指定如何将样本列表组合为mini-batch数据。传给它参数需要是一个callable对象,需要实现对组建的batch的处理逻辑,并返回每个batch的数据。在这里传入的是prepare_input函数,对产生的数据进行pad操作,并返回实际长度等。
In [ ]
# Reads data and generates mini-batches.def create_dataloader(dataset, trans_function=None, mode='train', batch_size=1, pad_token_id=0, batchify_fn=None): if trans_function: dataset = dataset.apply(trans_function, lazy=True) # return_list 数据是否以list形式返回 # collate_fn 指定如何将样本列表组合为mini-batch数据。传给它参数需要是一个callable对象,需要实现对组建的batch的处理逻辑,并返回每个batch的数据。在这里传入的是`prepare_input`函数,对产生的数据进行pad操作,并返回实际长度等。 dataloader = paddle.io.DataLoader( dataset, return_list=True, batch_size=batch_size, collate_fn=batchify_fn) return dataloader# python中的偏函数partial,把一个函数的某些参数固定住(也就是设置默认值),返回一个新的函数,调用这个新函数会更简单。trans_function = partial( convert_example, vocab=vocab, unk_token_id=vocab.get('[UNK]', 1), is_test=False)# 将读入的数据batch化处理,便于模型batch化运算。# batch中的每个句子将会padding到这个batch中的文本最大长度batch_max_seq_len。# 当文本长度大于batch_max_seq时,将会截断到batch_max_seq_len;当文本长度小于batch_max_seq时,将会padding补齐到batch_max_seq_len.batchify_fn = lambda samples, fn=Tuple( Pad(axis=0, pad_val=vocab['[PAD]']), # input_ids Stack(dtype="int64"), # seq len Stack(dtype="int64") # label): [data for data in fn(samples)]train_loader = create_dataloader( train_ds, trans_function=trans_function, batch_size=128, mode='train', batchify_fn=batchify_fn)dev_loader = create_dataloader( dev_ds, trans_function=trans_function, batch_size=128, mode='validation', batchify_fn=batchify_fn)test_loader = create_dataloader( test_ds, trans_function=trans_function, batch_size=128, mode='test', batchify_fn=batchify_fn)
模型搭建
使用LSTMencoder搭建一个BiLSTM模型用于进行句子建模,得到句子的向量表示。
然后接一个线性变换层,完成二分类任务。
paddle.nn.Embedding组建word-embedding层ppnlp.seq2vec.LSTMEncoder组建句子建模层paddle.nn.Linear构造二分类器
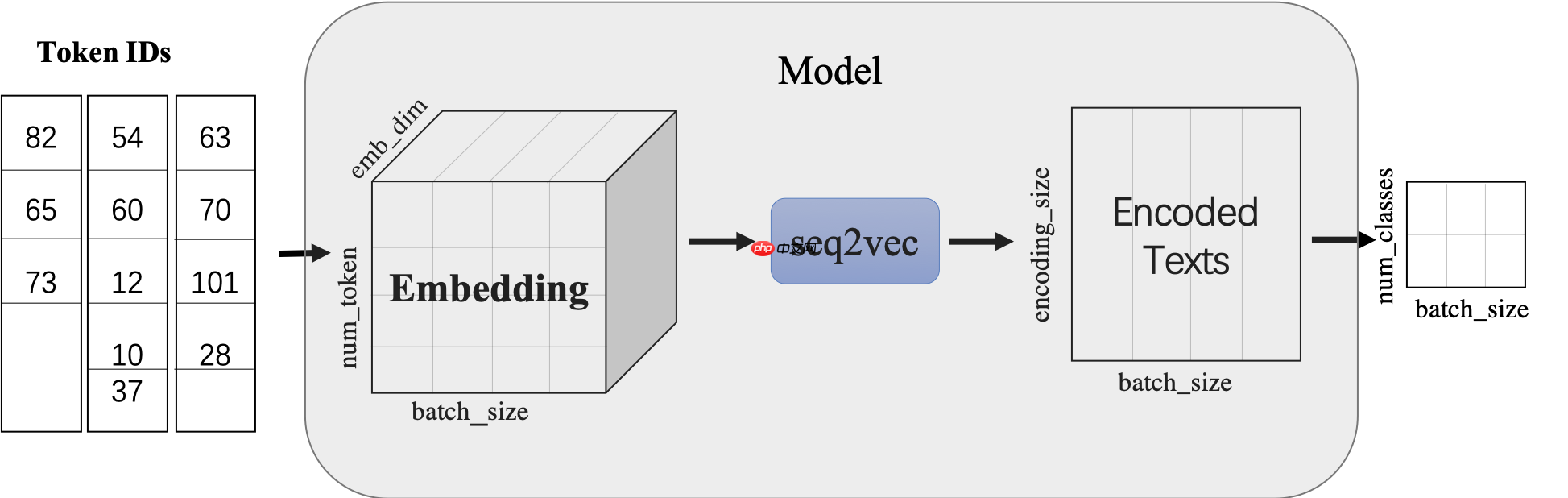
图1:seq2vec示意图
除LSTM外,seq2vec还提供了许多语义表征方法,详细可参考:seq2vec介绍In [ ]
class LSTMModel(nn.Layer): def __init__(self, vocab_size, num_classes, emb_dim=128, padding_idx=0, lstm_hidden_size=198, direction='forward', lstm_layers=1, dropout_rate=0, pooling_type=None, fc_hidden_size=96): super().__init__() # 首先将输入word id 查表后映射成 word embedding self.embedder = nn.Embedding( num_embeddings=vocab_size, embedding_dim=emb_dim, padding_idx=padding_idx) # 将word embedding经过LSTMEncoder变换到文本语义表征空间中 self.lstm_encoder = ppnlp.seq2vec.LSTMEncoder( emb_dim, lstm_hidden_size, num_layers=lstm_layers, direction=direction, dropout=dropout_rate, pooling_type=pooling_type) # LSTMEncoder.get_output_dim()方法可以获取经过encoder之后的文本表示hidden_size self.fc = nn.Linear(self.lstm_encoder.get_output_dim(), fc_hidden_size) # 最后的分类器 self.output_layer = nn.Linear(fc_hidden_size, num_classes) def forward(self, text, seq_len): # text shape: (batch_size, num_tokens) # print('input :', text.shape) # Shape: (batch_size, num_tokens, embedding_dim) embedded_text = self.embedder(text) # print('after word-embeding:', embedded_text.shape) # Shape: (batch_size, num_tokens, num_directions*lstm_hidden_size) # num_directions = 2 if direction is 'bidirectional' else 1 text_repr = self.lstm_encoder(embedded_text, sequence_length=seq_len) # print('after lstm:', text_repr.shape) # Shape: (batch_size, fc_hidden_size) fc_out = paddle.tanh(self.fc(text_repr)) # print('after Linear classifier:', fc_out.shape) # Shape: (batch_size, num_classes) logits = self.output_layer(fc_out) # print('output:', logits.shape) # probs 分类概率值 probs = F.softmax(logits, axis=-1) # print('output probability:', probs.shape) return probsmodel= LSTMModel( len(vocab), len(label_list), direction='bidirectional', padding_idx=vocab['[PAD]'])model = paddle.Model(model)
模型配置和训练
In [ ]
optimizer = paddle.optimizer.Adam( parameters=model.parameters(), learning_rate=5e-5)loss = paddle.nn.CrossEntropyLoss()metric = paddle.metric.Accuracy()model.prepare(optimizer, loss, metric)
In [ ]
# 设置visualdl路径log_dir = './visualdl'callback = paddle.callbacks.VisualDL(log_dir=log_dir)
In [53]
model.fit(train_loader, dev_loader, epochs=20, save_dir='./checkpoints', save_freq=5, callbacks=callback)
In [54]
results = model.evaluate(dev_loader)print("Finally test acc: %.5f" % results['acc'])
Eval begin...The loss value printed in the log is the current batch, and the metric is the average value of previous step.step 10/45 - loss: 1.6787 - acc: 0.4602 - 56ms/stepstep 20/45 - loss: 1.6627 - acc: 0.4582 - 46ms/stepstep 30/45 - loss: 1.7386 - acc: 0.4547 - 43ms/stepstep 40/45 - loss: 1.7037 - acc: 0.4514 - 41ms/stepstep 45/45 - loss: 1.7308 - acc: 0.4526 - 37ms/stepEval samples: 5650Finally test acc: 0.45257
In [59]
label_map={0:"sadness", 1:"happiness",2:"disgust",3:"like",4:"anger" ,5:"surprise",6:"fear"}results = model.predict(test_loader, batch_size=128)[0]predictions = []for batch_probs in results: # 映射分类label idx = np.argmax(batch_probs, axis=-1) idx = idx.tolist() labels = [label_map[i] for i in idx] predictions.extend(labels)# 看看预测数据前5个样例分类结果for idx, data in enumerate(test_ds.data[:10]): print('Data: {} t Label: {}'.format(data[0], predictions[idx]))
Predict begin...step 56/56 [==============================] - ETA: 4s - 85ms/ste - ETA: 4s - 88ms/ste - ETA: 3s - 72ms/ste - ETA: 3s - 64ms/ste - ETA: 2s - 60ms/ste - ETA: 2s - 56ms/ste - ETA: 2s - 54ms/ste - ETA: 2s - 52ms/ste - ETA: 1s - 51ms/ste - ETA: 1s - 50ms/ste - ETA: 1s - 49ms/ste - ETA: 1s - 48ms/ste - ETA: 1s - 47ms/ste - ETA: 1s - 46ms/ste - ETA: 1s - 46ms/ste - ETA: 1s - 46ms/ste - ETA: 0s - 45ms/ste - ETA: 0s - 45ms/ste - ETA: 0s - 45ms/ste - ETA: 0s - 45ms/ste - ETA: 0s - 45ms/ste - ETA: 0s - 44ms/ste - ETA: 0s - 44ms/ste - ETA: 0s - 44ms/ste - ETA: 0s - 44ms/ste - ETA: 0s - 43ms/ste - ETA: 0s - 41ms/ste - 40ms/step Predict samples: 7063Data: 【旅游】美食:滇南地区建水的蕈芽、石屏的豆腐、蒙自的过桥米线。滇东北地区菜豆花、连渣搞、酸辣鸡等。滇西地区的大理沙锅鱼、酸辣鱼。丽江粑粑、八大碗。弥渡的卷蹄、风吹肝、腾冲的大救驾,各种凉拌野菜、松尖等。关注【游遍云南】公众微信,让您畅游云南,游遍云南公众微信号:y4000119001 Label: happinessData: 想哭, Label: sadnessData: 自己打的赌,赌的很大,不知道自己到底战绩怎样 Label: disgustData: 4...这都不是偶然的事情,这是他明白这个事实真相,对生死看得很淡薄,知道要认真努力修行,所以死了之后,自己可以作主,自己可以选择到哪一道去。如果在临终时,一慌一乱,你对身体很留恋,对家亲眷属很留恋,那你往往就到三途去了! Label: happinessData: 干了这碗香菜我们是好朋友 Label: disgustData: 韩国沉船遇难者'不愿分离'。一男生一女生害怕被水冲开分离紧捆绑在一起。[蜡烛][蜡烛][蜡烛] Label: happinessData: 那一年,cang井空还是处女,冠希还没有相机,李刚还没有儿子,菊花只是一种花,企鹅不是qq,2b我只知道是铅笔,买方便面还有调料,杯具只是用来刷牙,楼房是用来住的,黄瓜香蕉只是用来吃的,教授还不是叫兽,太阳还不叫日,领导不会写日记,鸭梨还没有这么大,肚子大了也知道是谁的我们还相信真情 Label: sadnessData: 小孩子会说谎,大孩子也会说谎,不过,美名其曰为“借口”,不努力,是因为没了目标,没了动力,习惯了堕落。。。 Label: sadnessData: 特困户的春天[拜拜] Label: sadnessData: 找院长写推荐信之前把自我介绍想过很多遍,结果院长大人没有赴约;从早到晚在实验室忙碌只为了按时完成实验,结果教授将实验计划改变;纠结了好久今天终于鼓起勇气再加一次某人的微信,结果我貌似在黑名单里面......总以为解决了自己就解决了一切,但是没想到,事情总是有想不懂到的一面。 Label: disgust
代码解释In [ ]
以上就是自定义数据集OCEMOTION–中文情感分类的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/768226.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 





















