
audiox:一款革命性的多模态音频生成模型
AudioX是由香港科技大学和月之暗面团队联合开发的先进统一扩散变压器模型,能够根据多种输入内容生成高质量音频和音乐。它支持文本、视频、图像、音乐和音频等多种输入模态,并通过创新的多模态掩码训练策略,显著提升了跨模态表示能力。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜
核心功能:
AudioX 的强大功能体现在以下几个方面:
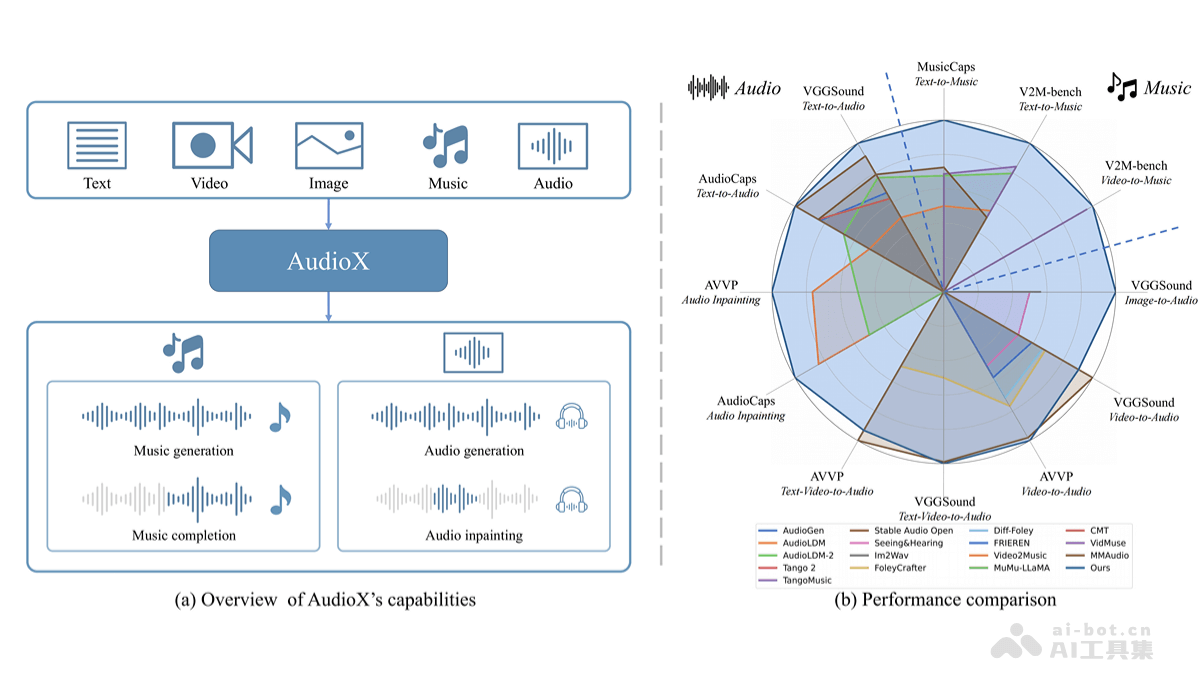
多模态输入: 支持文本转音频、视频转音频、图像转音频、音乐生成以及音频修复和音乐补全等功能。例如,输入“雨声”,AudioX 可生成逼真的雨声效果;输入一段无声视频,AudioX 可根据画面内容自动添加相应的音效。
高质量音频输出: 基于扩散模型技术,AudioX 生成的高保真音频细节丰富,音质逼真。
精准的自然语言控制: 用户可通过自然语言精确控制音频生成过程,例如指定音效类型、音乐风格、乐器等。
强大的跨模态学习: AudioX 能有效整合不同模态的输入信息,例如同时输入文本和图像,生成更贴切的音频输出。
卓越的泛化能力: 在AudioCaps、VGGSound、MusicCaps、V2M-bench等多个数据集和任务上表现出色,展现了其强大的适应性和泛化能力。
零样本生成能力: 即使未针对特定模态进行专门训练,AudioX 仍能生成高质量音频,体现了其强大的通用性。
 Imagine By Magic Studio
Imagine By Magic Studio
AI图片生成器,用文字制作图片
 79 查看详情
79 查看详情 
技术原理概述:
AudioX 的技术核心在于扩散模型和多模态掩码训练策略:
扩散模型: 通过逐步添加和去除噪声来生成音频,实现高质量音频的重建。
多模态掩码训练: 随机掩盖部分输入模态,迫使模型从不完整信息中学习,从而增强模型的鲁棒性和跨模态理解能力。
AudioX 还使用了多种专用编码器处理不同模态的输入,并将特征融合到统一的潜空间中,最终生成目标音频。
项目信息:
项目官网: https://www.php.cn/link/571e646d4ea4d46a8fde33d07167efe5Github 仓库: https://www.php.cn/link/5a730579ebe031843c2cda200a47bb67arXiv 技术论文: https://www.php.cn/link/abb207957b0abc1d85a7e32ab1c4359c
应用前景:
AudioX 在视频配乐、动画音效制作、音乐创作辅助、语言学习等领域具有广阔的应用前景。
总而言之,AudioX 作为一款先进的多模态音频生成模型,其强大的功能和广泛的应用前景,使其成为音频生成领域的一项重要突破。
以上就是AudioX— 港科大联合月之暗面推出的扩散变换器模型,任意内容生成音频的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/774012.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 






















