
%ignore_a_1%DeepMind最新推出的Gemini Robotics项目,首次实现了让机器人在行动前具备“思考”能力的双模型协同系统。这一技术突破有望打破当前机器人仅能完成特定任务的瓶颈,推动其向更通用化方向发展。
尽管生成式AI已在文本、图像、音频和视频内容创作中广泛应用,如今这项技术正被延伸至机器人动作指令的生成领域。DeepMind研究团队强调,生成式AI对机器人学具有深远意义,因为它能够赋予机器人前所未有的通用性与适应能力。
目前大多数机器人面临的核心挑战是高度专业化。每台机器人通常需要针对某一具体任务进行大量训练,在面对新任务时往往难以胜任。对此,谷歌DeepMind机器人部门主管Carolina Parada表示:“现有的机器人系统大多高度定制,部署过程复杂且耗时,常常花费数月时间才能上线一个只能做单一工作的机器人单元。”
为解决这一问题,DeepMind提出了基于生成式AI的新一代机器人架构。这类系统具备更强的泛化能力,能够在未知环境中自主适应,无需重新编程即可应对多样化任务。其实现方式依赖于两个协同工作的模型:一个负责规划决策,另一个专注于动作执行。
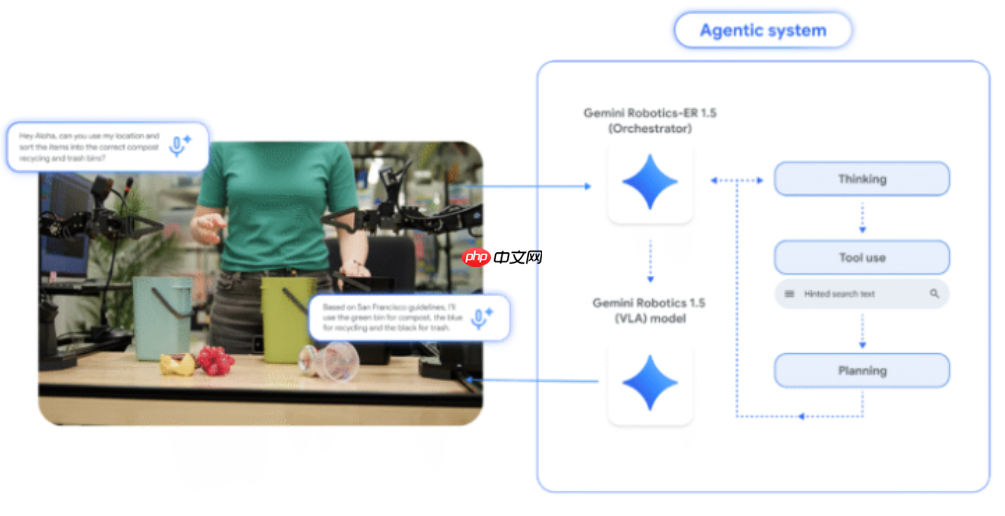
这两个新型模型分别为Gemini Robotics1.5与Gemini Robotics-ER1.5。其中,前者是一种视觉-语言-动作(VLA)模型,能够结合视觉感知和语言理解来生成具体的机器人操作指令;后者中的“ER”代表具身推理(Embodied Reasoning),是一个专精于推理的视觉-语言模型,接收环境图像和自然语言输入后,输出完成复杂任务所需的逻辑步骤。
 Imagine By Magic Studio
Imagine By Magic Studio
AI图片生成器,用文字制作图片
 79 查看详情
79 查看详情 
尤为关键的是,Gemini Robotics-ER1.5是首个实现模拟推理的机器人AI系统,其推理机制类似于先进聊天机器人的思维链过程。虽然“思考”一词在生成式AI语境下可能存在争议,但DeepMind用此描述其高级决策能力。该模型在多项学术及内部基准测试中表现卓越,证明其能准确判断如何与物理世界交互。然而,它并不直接控制机器人运动,而是将生成的策略传递给执行模型。
以衣物分类任务为例:当机器人需要将混洗衣物按颜色分拣为白色和彩色两类时,Gemini Robotics-ER1.5会首先接收任务指令并分析场景图像。它还可调用外部工具如谷歌搜索获取相关信息,随后生成一系列自然语言形式的操作指南,指导机器人完成整个流程。
这种双模型设计的关键创新在于将“决策”与“执行”分离。具身推理模型专注于任务理解和路径规划,制定详尽的行动计划;而动作执行模型则精准地将这些抽象指令转化为机械臂的实际动作。通过这种分工协作模式,机器人不仅拥有了类人般的规划能力,同时也保持了工业级的操作精度与稳定性。
以上就是谷歌 DeepMind 推出双 AI 机器人系统的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/774471.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 






















