在centos上使用pytorch进行深度学习任务时,数据存储是一个重要的环节。以下是一些关键点和步骤,帮助你有效地在centos系统上存储和管理数据。
数据存储的基本方法
使用文件系统:PyTorch推荐将数据存储在文件系统中,可以通过创建特定的文件夹结构来组织数据。例如,对于图像数据,可以按类别创建子文件夹,并将图像文件存储在其中。使用数据库:对于需要更高效数据检索和管理的场景,可以使用SQLite等轻量级数据库来存储数据。PyTorch提供了torch.utils.data.Dataset类,可以方便地与数据库进行交互。
数据加载和预处理
使用DataLoader:PyTorch的DataLoader类可以帮助你批量加载数据,并进行预处理。通过设置pin_memory=True,可以优化数据从CPU传输到GPU的速度,特别是在使用GPU进行训练时。
示例代码
以下是一个简单的示例,展示如何在PyTorch中创建自定义数据集并使用DataLoader加载数据:
import torchfrom torch.utils.data import Dataset, DataLoaderfrom torchvision import transformsfrom PIL import Imageimport os# 定义自定义数据集类class MyDataset(Dataset): def __init__(self, txt_path): self.imgs = [] with open(txt_path, 'r') as f: for line in f: words = line.strip().split() self.imgs.append((words[0], words[1])) def __getitem__(self, index): img_path, label = self.imgs[index] img = Image.open(img_path).convert('RGB') return img, int(label) def __len__(self): return len(self.imgs)# 创建数据集实例dataset = MyDataset(txt_path='path/to/label.txt')# 使用DataLoader加载数据dataloader = DataLoader(dataset, batch_size=64, shuffle=True, num_workers=4, pin_memory=True)# 遍历DataLoaderfor images, labels in dataloader: images = images.to('cuda' if torch.cuda.is_available() else 'cpu') labels = labels.to('cuda' if torch.cuda.is_available() else 'cpu') # 进行训练或推理
注意事项
数据安全性:确保数据存储在安全的位置,避免数据泄露或被未授权访问。数据备份:定期备份重要数据,以防数据丢失。
通过以上步骤和示例代码,你可以在CentOS上有效地存储和管理PyTorch数据,从而提高深度学习任务的效率和可靠性。
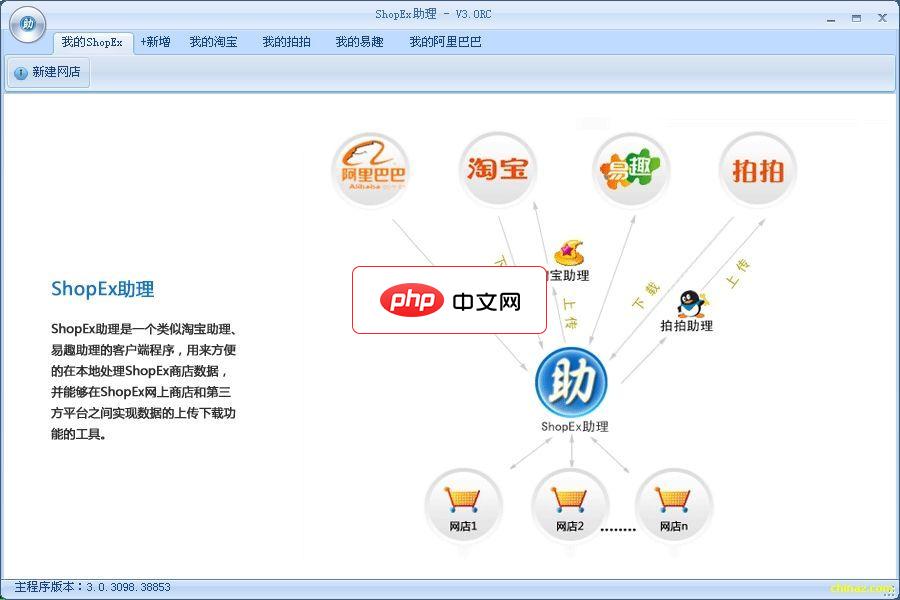 ShopEx助理
ShopEx助理
一个类似淘宝助理、ebay助理的客户端程序,用来方便的在本地处理商店数据,并能够在本地商店、网上商店和第三方平台之间实现数据上传下载功能的工具。功能说明如下:1.连接本地商店:您可以使用ShopEx助理连接一个本地安装的商店系统,这样就可以使用助理对本地商店的商品数据进行编辑等操作,并且数据也将存放在本地商店数据库中。默认是选择“本地未安装商店”,本地还未安
 0 查看详情
0 查看详情 
以上就是PyTorch在CentOS上的数据存储的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/788202.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫