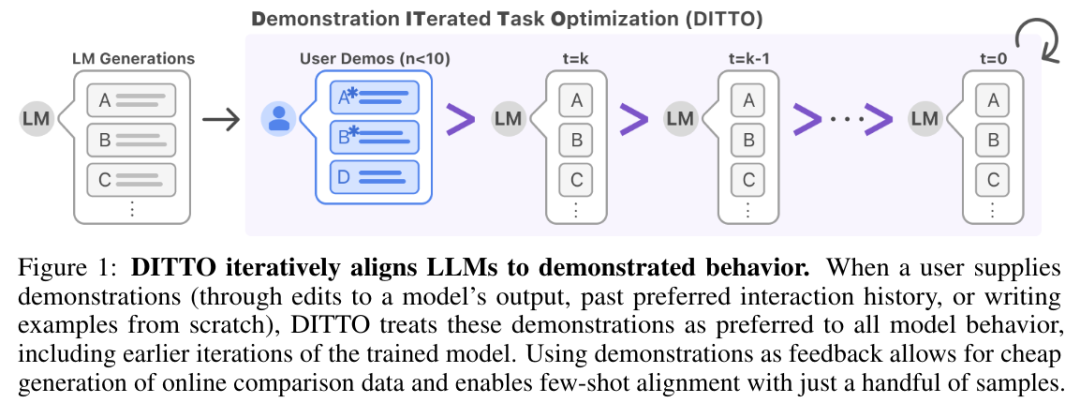
养育孩子时,古往今来人们都会谈到一种重要方法:以身作则。也就是让自己成为孩子模仿学习的范例,而不是单纯地告诉他们应该怎么做。在训练大语言模型(LLM)时,我们或许也能采用这样的方法 —— 向模型进行演示。
近日,斯坦福大学杨笛一团队提出了一种新框架 DITTO,可通过少量演示(用户提供的期望行为示例)来将 LLM 与特定设置对齐。这些示例可以从用户现有的交互日志获取,也能通过直接编辑 LLM 的输出得到。这样就可以让模型针对不同的用户和任务高效地理解并对齐用户偏好。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

论文标题:Show, Don’t Tell: Aligning Language Models with Demonstrated Feedback
论文地址:https://arxiv.org/pdf/2406.00888
DITTO 可基于少量演示(少于 10)自动创建一个包含大量偏好比较数据的数据集(这个过程被称为 scaffold),其具体做法是默认这一点:相比于原始 LLM 及早期迭代版本的输出,用户更偏好演示。然后,将演示与模型输出组成数据对,得到增强数据集。之后便可以使用 DPO 等对齐算法来更新语言模型。
此外,该团队还发现,DITTO 可被视为一种在线模仿学习算法,其中从 LLM 采样的数据会被用于区分专家行为。从这一角度出发,该团队证明 DITTO 可通过外推实现超越专家的表现。
为了对齐 LLM,此前的各类方法往往需要使用成千上万对比较数据,而 DITTO 仅需使用少量演示就能修改模型的行为。这种低成本的快速适应之所以能实现,主要得益于该团队的核心见解:可通过演示轻松获取在线比较数据。
语言模型可被视为一个策略 π(y|x),这会得到 prompt x 和完成结果 y 的一个分布。RLHF 的目标是训练 LLM 以最大化一个奖励函数 r (x, y),其评估的是 prompt – 完成结果对 (x, y) 的质量。通常来说,还会添加一个 KL 散度,以防止更新后的模型偏离基础语言模型(π_ref)太远。总体而言,RLHF 方法优化的目标为:
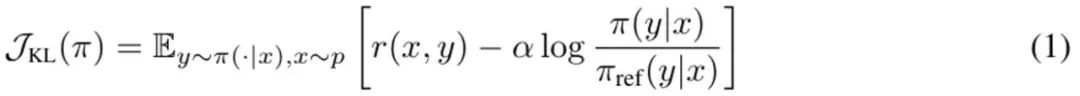
这是最大化在 prompt 分布 p 上的预期奖励,而 p 则受 α 调节的 KL 约束的影响。通常而言,优化这一目标使用的是形式为 {(x, y^w, y^l )} 的比较数据集,其中「获胜」的完成结果 y^w 优于「失败」的完成结果 y^l,记为 y^w ⪰ y^l。
另外,这里把小型专家演示数据集记为 D_E,并假设这些演示是由专家策略 π_E 生成的,其能最大化预测奖励。DITTO 能直接使用语言模型输出和专家演示来生成比较数据。也就是说,不同于合成数据的生成范式,DITTO 无需在给定任务上已经表现很好的模型。
DITTO 的关键见解在于语言模型本身,再加上专家演示,可以得到用于对齐的比较数据集,这样就无需收集大量成对的偏好数据了。这会得到一个类似对比的目标,其中专家演示是正例。
生成比较。假定我们从专家策略采样了一个完成结果 y^E ∼ π_E (・|x) 。那么可以认为,从其它策略 π 采样的样本对应的奖励都低于或等于从 π_E 采样的样本的奖励。基于这一观察,该团队构建了比较数据 (x, y^E, y^π ),其中 y^E ⪰ y^π。尽管这样的比较数据源自策略而不是各个样本,但之前已有研究证明了这种方法的有效性。对 DITTO 来说,一个很自然的做法就是使用这个数据集以及一个现成可用的 RLHF 算法来优化 (1) 式。这样做能在提升专家响应的概率同时降低当前模型样本的概率,这不同于标准微调方法 —— 只会做前者。关键在于,通过使用来自 π 的样本,可使用少量演示就构建出无边界的偏好数据集。但是,该团队发现,通过考虑学习过程的时间方面,还能做到更好。
从比较到排名。仅使用来自专家和单个策略 π 的比较数据,可能不足以获得优良性能。这样做只会降低特定 π 的可能性,导致过拟合问题 —— 这也困扰着少数据情况下的 SFT。该团队提出还可以考虑 RLHF 期间随时间而学习到的所有策略所生成的数据,这类似于强化学习中的 replay(重放)。
令第一轮迭代时的初始策略为 π_0。通过采样该策略可得到一个数据集 D_0。然后可以基于此生成一个用于 RLHF 的比较数据集,可记为 D_E ⪰ D_0。使用这些导出的比较数据,可以对 π_0 进行更新而得到 π_1。根据定义,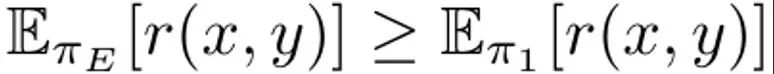 也成立。之后,继续使用 π_1 生成比较数据,并且 D_E ⪰ D_1。继续这一过程,不断使用之前的所有策略生成越来越多样化的比较数据。该团队将这些比较数据称为「重放比较数据(replay comparisons)」。
尽管这种方法理论上说得通,但如果 D_E 较小,却可能出现过拟合。但是,如果假设每一轮迭代后策略都会获得提升,则也可在训练期间考虑策略之间的比较。不同于与专家的比较,我们并不能保证每一轮迭代之后策略都更好,但该团队发现模型每次迭代后总体依然是提升的,这可能是是因为奖励建模和 (1) 式都是凸的。这样便可以依照以下的排名来采样比较数据:
也成立。之后,继续使用 π_1 生成比较数据,并且 D_E ⪰ D_1。继续这一过程,不断使用之前的所有策略生成越来越多样化的比较数据。该团队将这些比较数据称为「重放比较数据(replay comparisons)」。
尽管这种方法理论上说得通,但如果 D_E 较小,却可能出现过拟合。但是,如果假设每一轮迭代后策略都会获得提升,则也可在训练期间考虑策略之间的比较。不同于与专家的比较,我们并不能保证每一轮迭代之后策略都更好,但该团队发现模型每次迭代后总体依然是提升的,这可能是是因为奖励建模和 (1) 式都是凸的。这样便可以依照以下的排名来采样比较数据:
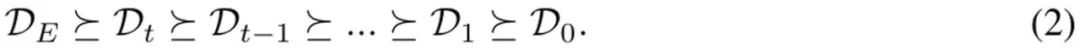
通过添加这些「模型间」和「重放」比较数据,得到的效果是早期样本(比如 D_1 中的样本)的似然会比后期的(如 D_t 中的)压得更低,从而使隐含的奖励图景变得平滑。在实践实现中,该团队的做法是除了使用与专家的比较数据,也聚合了一些这些模型间比较数据。
一个实践算法。在实践中,DITTO 算法是一个迭代过程,其由三个简单的组件构成,如算法 1 所示。

首先,在专家演示集上运行监督式微调,执行数量有限的梯度步骤。将这设为初始策略 π_0. 第二步,采样比较数据:在训练过程中,对于 D_E 中的 N 个演示中的每一个,通过从 π_t 采样 M 个完成结果而构建一个新的数据集 D_t,然后根据策略 (2) 式将它们添加到排名中。当从 (2) 式采样比较数据时,每一批 B 都由 70% 的「在线」比较数据 D_E ⪰ D_t、20% 的「重放」比较数据 D_E ⪰ D_{i
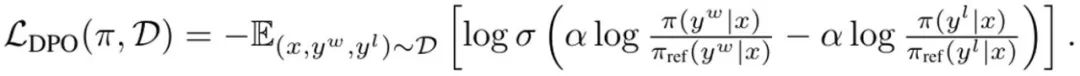
 爱派AiPy
爱派AiPy
融合LLM与Python生态的开源AI智能体
 1 查看详情
1 查看详情 
其中 σ 是来自 Bradley-Terry 偏好模型的 logistic 函数。在每次更新期间,来自 SFT 策略的参考模型都不会更新,以避免偏离初始化过远。
DITTO 可通过在线模仿学习角度推导出来,其中组合使用专家演示和在线数据来同时学习奖励函数和策略。具体来说,策略玩家会最大化预期奖励 ? (π, r),而奖励玩家则会最小化在在线数据集 D^π 上的损失 min_r L (D^π , r) 更具体而言,该团队的做法是使用 (1) 式中的策略目标和标准的奖励建模损失来实例化该优化问题:
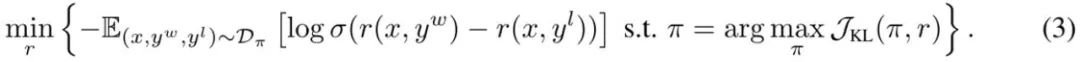
推导 DITTO,简化 (3) 式的第一步是解决其内部策略最大化问题。幸运的是,该团队基于之前的研究发现策略目标 ?_KL 有一个闭式解,其形式为,其中 Z (x) 用于归一化分布的配分函数。值得注意的是,这会在策略和奖励函数之间建立一种双射关系,这可以被用于消除内部优化。通过重新排列这个解,可将奖励函数写成: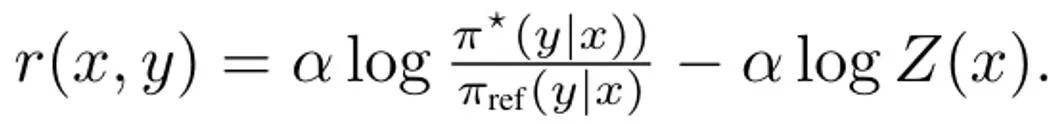 此外,之前有研究表明这种重新参数化可以表示任意奖励函数。于是,通过代入到 (3) 式,可以将变量 r 变成 π,从而得到 DITTO 目标:
此外,之前有研究表明这种重新参数化可以表示任意奖励函数。于是,通过代入到 (3) 式,可以将变量 r 变成 π,从而得到 DITTO 目标: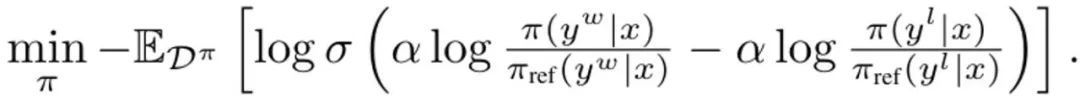 请注意,类似于 DPO,这里是隐式地估计奖励函数。而不同于 DPO 的地方是 DITTO 依赖一个在线的偏好数据集 D^π。
DITTO 表现更好的一个原因是:通过生成比较数据,其使用的数据量远多于 SFT。另一个原因是在某些情况下,在线模仿学习方法的表现会超过演示者,而 SFT 只能模仿演示。
该团队也进行了实证研究,证明了 DITTO 的有效性。实验的具体设置请参阅原论文,我们这里仅关注实验结果。
请注意,类似于 DPO,这里是隐式地估计奖励函数。而不同于 DPO 的地方是 DITTO 依赖一个在线的偏好数据集 D^π。
DITTO 表现更好的一个原因是:通过生成比较数据,其使用的数据量远多于 SFT。另一个原因是在某些情况下,在线模仿学习方法的表现会超过演示者,而 SFT 只能模仿演示。
该团队也进行了实证研究,证明了 DITTO 的有效性。实验的具体设置请参阅原论文,我们这里仅关注实验结果。
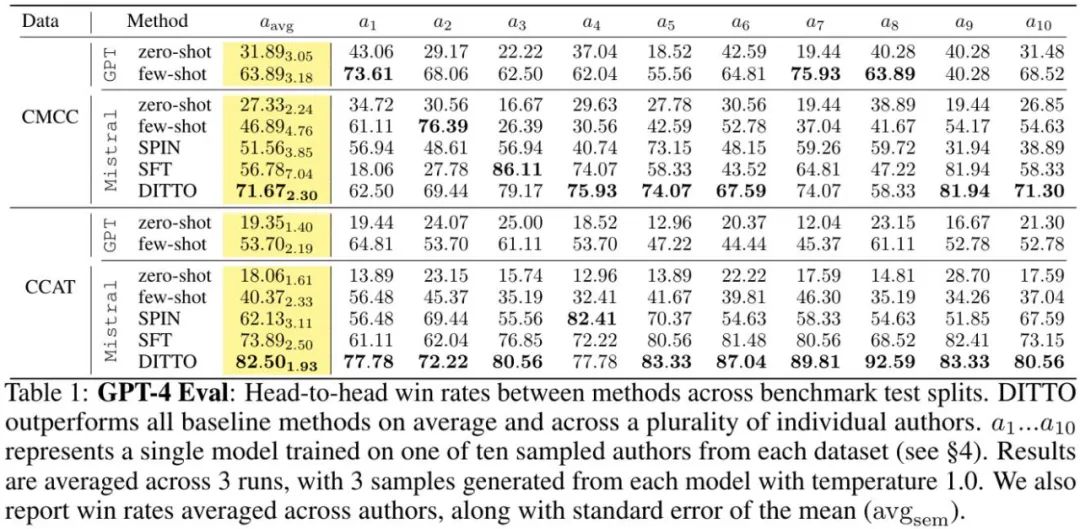
平均而言,DITTO 胜过其它所有方法:在 CMCC 上平均胜率为 71.67%,在 CCAT50 上平均胜率为 82.50%;总体平均胜率为 77.09%。在 CCAT50 上,对于所有作者,DITTO 仅在其中一个上没有取得全面优胜。在 CMCC 上,对于所有作者,DITTO 全面胜过其中一半基准,之后是 few-shot prompting 赢得 3 成。尽管 SFT 的表现很不错,但 DITTO 相较于其的平均胜率提升了 11.7%。
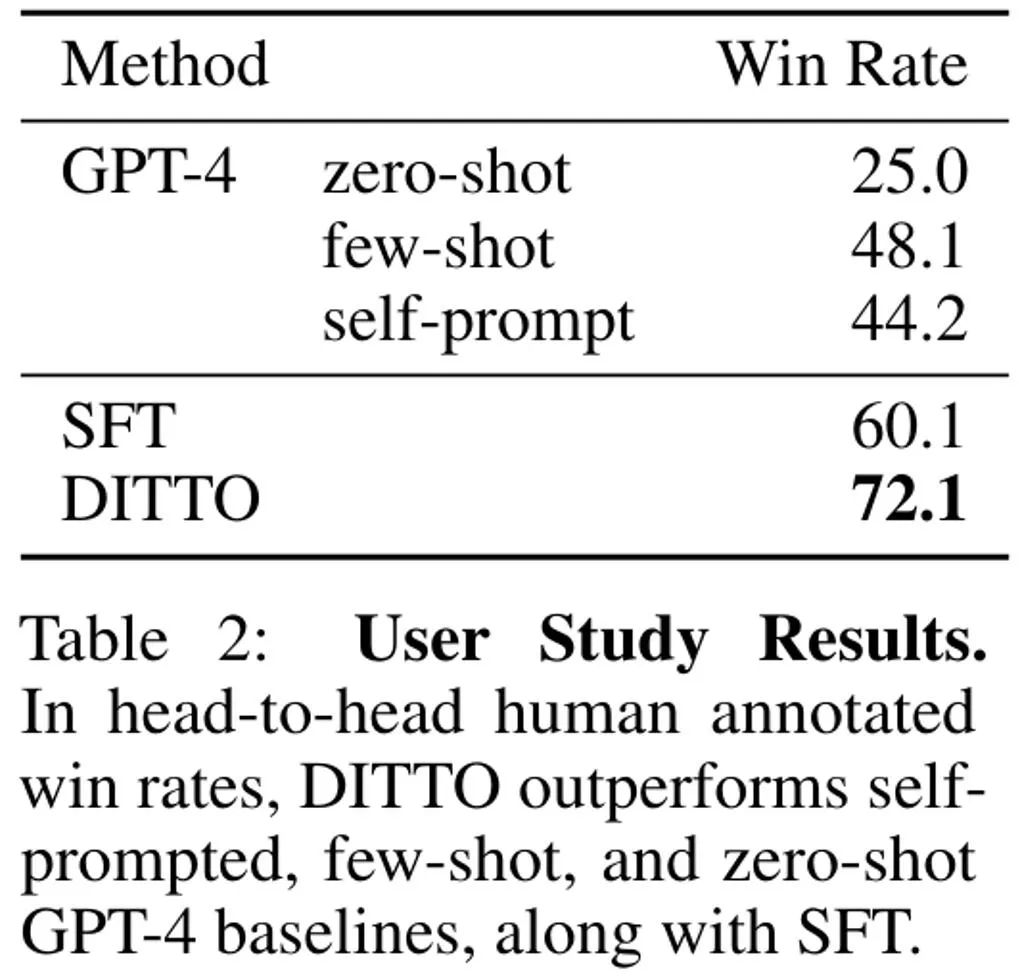
总体而言,用户研究的结果与在静态基准上的结果一致。DITTO 在对齐演示的偏好方面优于对比方法,如表 2 所示:其中 DITTO (72.1% 胜率) > SFT (60.1%) > few-shot (48.1%) > self-prompt (44.2%) > zero-shot (25.0%)。
在使用 DITTO 之前,用户必须考虑一些前提条件,从他们有多少演示到必须从语言模型采样多少负例。该团队探索了这些决定的影响,并重点关注了 CMCC,因为其覆盖的任务超过 CCAT。此外,他们还分析了演示与成对反馈的样本效率。
如图 2(左)所示,增加 DITTO 的迭代次数通常可以提升性能。
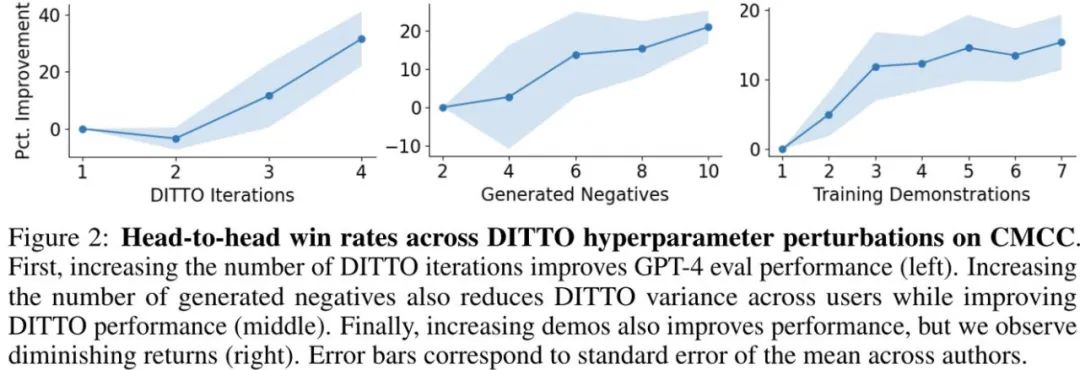
可以看到,当迭代次数从 1 次提升到 4 次,GPT-4 评估的胜率会有 31.5% 的提升。这样的提升是非单调的 —— 在第 2 次迭代时,性能稍有降低(-3.4%)。这是因为早期的迭代可能会得到噪声更大的样本,从而降低性能。另一方面,如图 2(中)所示,增加负例数量会使 DITTO 性能单调提升。此外,随着采样的负例增多,DITTO 性能的方差会下降。
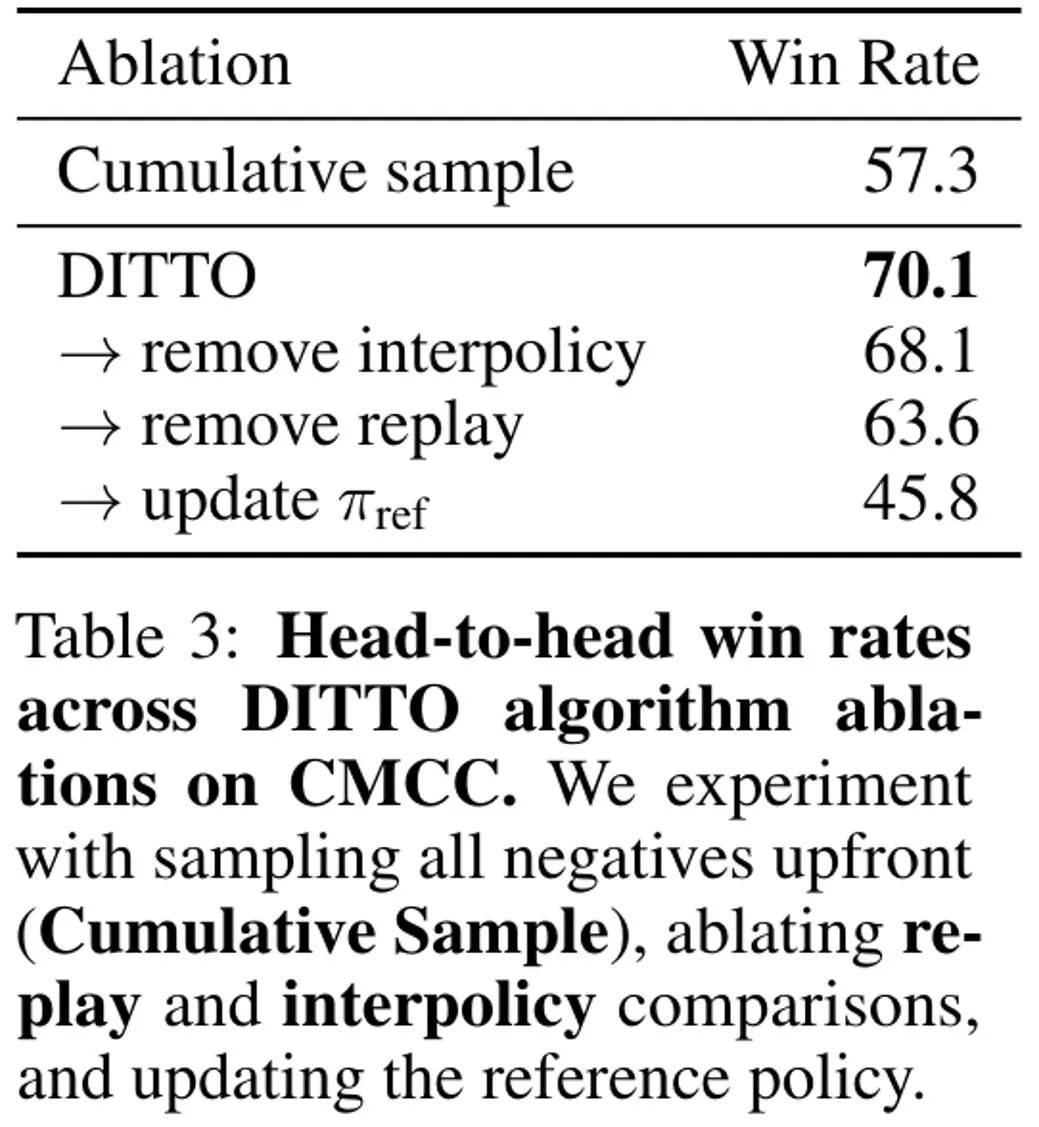
另外,如表 3 所示,对 DITTO 的消融研究发现,去掉其任何组件都会导致性能下降。
比如如果放弃在线方式的迭代式采样,相比于使用 DITTO,胜率会从 70.1% 降至 57.3%。而如果在在线过程中持续更新 π_ref,则会导致性能大幅下降:从 70.1% 降至 45.8%。该团队猜想其原因是:更新 π_ref 可能会导致过拟合。最后,我们也能从表 3 中看到重放和策略间比较数据的重要性。
DITTO 的一大关键优势是其样本效率。该团队对此进行了评估,结果见图 2(右);同样,这里报告的是归一化后的胜率。
首先可以看到,DITTO 的胜率一开始会快速提升。在演示数量从 1 变成 3 时,每次增加都会让归一化性能大幅提升(0% → 5% → 11.9%)。
但是,当演示数量进一步增加时,收益增幅降低了(从 4 增至 7 时为 11.9% → 15.39%),这说明随着演示数量增加,DITTO 的性能会饱和。
另外,该团队猜想,不止演示数量会影响 DITTO 的性能,演示质量也会,但这还留待未来研究。
DITTO 的一个核心假设是样本效率源自于演示。理论上讲,如果用户心中有一套完美的演示集合,通过标注许多成对的偏好数据也能实现类似的效果。
该团队做了一个近似实验,使用从指令遵从 Mistral 7B 采样的输出,让一位提供了用户研究的演示的作者也标注了 500 对偏好数据。
总之,他们构建了一个成对的偏好数据集 D_pref = {(x, y^i , y^j )},其中 y^i ≻ y^j。然后他们计算了采样自两个模型的 20 对结果的胜率情况 —— 其一是使用 DITTO 在 4 个演示上训练的,其二是仅使用 DPO 在 {0…500} 偏好数据对训练的。
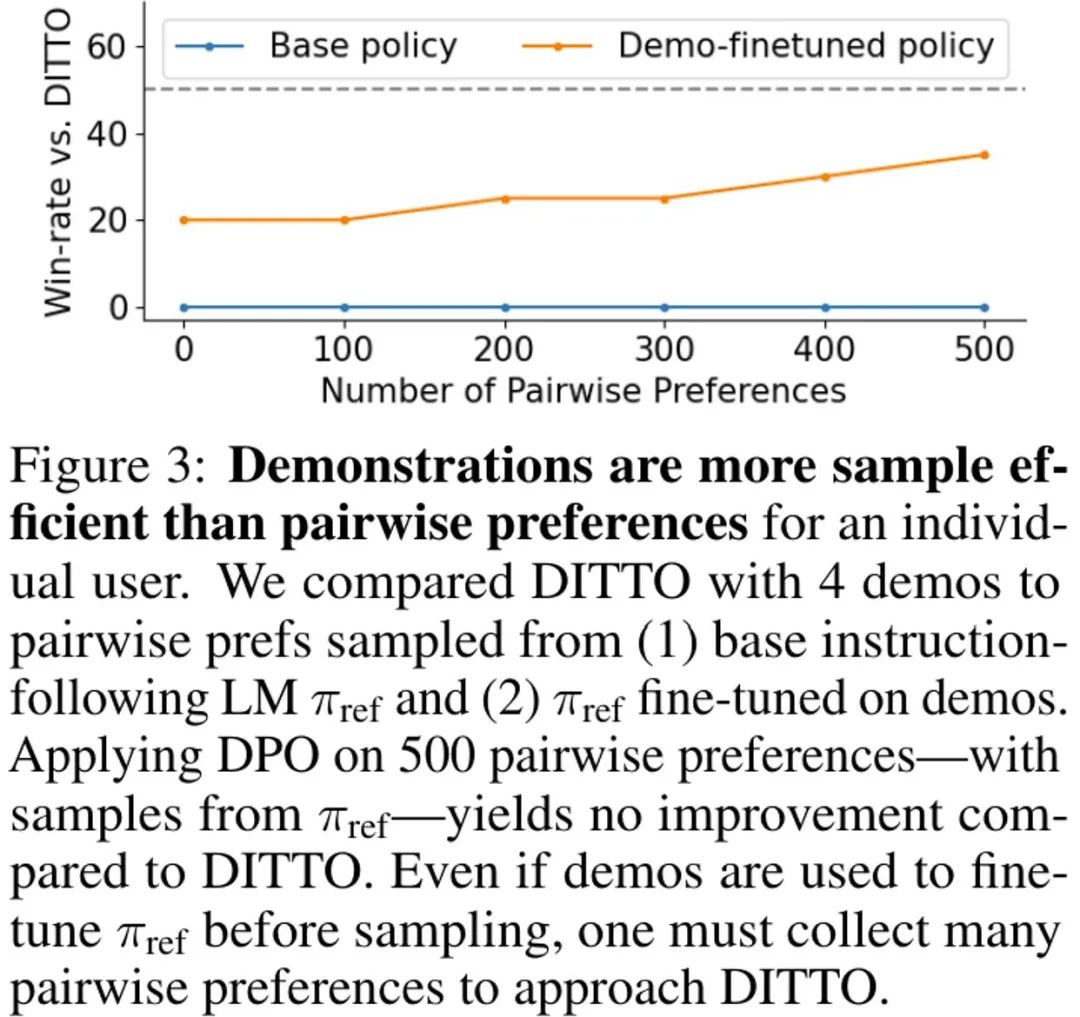
当仅从 π_ref 采样成对偏好数据时,可以观察到生成的数据对位于演示的分布外 —— 成对的偏好不涉及用户演示的行为(图 3 中 Base policy 的结果,蓝色)。即使当他们使用用户演示对 π_ref 进行微调时,仍然需要超过 500 对偏好数据才能比肩 DITTO 的性能(图 3 中 Demo-finetuned policy 的结果,橙色)。
以上就是只需几个演示就能对齐大模型,杨笛一团队提出的DITTO竟如此高效的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/791455.html

 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 

























