最近,谷歌 DeepMind 突然开始炫起了机器人。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜


 新CG儿
新CG儿
数字视觉分享平台 | AE模板_视频素材
 412 查看详情
412 查看详情 
这个机器人可以轻松听从人类指令、进行视觉导览,用常识推理在三维空间中寻找路径。
它使用的是最近谷歌发布的大模型 Gemini 1.5 Pro。在使用传统 AI 模型时,机器人常因上下文长度限制而难以回忆起环境细节,但 Gemini 1.5 Pro 的百万级 token 上下文长度为机器人提供了强大的环境记忆能力。
在真实的办公室场景中,工程师引导机器人游览特定区域,并标出了需要回忆的关键地点,例如「刘易斯的办公桌」或「临时办公桌区域」。转完一圈后,别人要问起来,机器人就能根据这些记忆带他去这些地点了。 即使你说不出具体要去的地点,只是表达一下目的,机器人也能带你找到对应的位置。这是大模型的推理能力在机器人身上的具体表现。
即使你说不出具体要去的地点,只是表达一下目的,机器人也能带你找到对应的位置。这是大模型的推理能力在机器人身上的具体表现。  这一切离不开一个叫 Mobility VLA 的导航策略。
论文标题:Mobility VLA: Multimodal Instruction Navigation with Long-Context VLMs and Topological Graphs
论文链接:https://arxiv.org/pdf/2407.07775v1
DeepMind 表示,这项工作代表了人机交互的下一步。未来,用户可以简单地用智能手机拍摄他们的环境游览经历。在看过视频后,他们的个人机器人助手就能理解并在环境中导航。
Mobility VLA:利用长上下文 VLM 和拓扑图进行多模态指令导航
随着 AI 技术的不断发展,机器人导航已经取得了长足进步。早期的工作依赖于用户在预先绘制的环境中指定物理坐标。物体目标导航(ObjNav)和视觉语言导航(VLN)是机器人可用性的一大飞跃,因为它们允许用户使用开放词汇语言来定义导航目标,如「去沙发那里」。
为了让机器人在我们的日常生活中真正有用并无处不在,谷歌 DeepMind 的研究者提出将 ObjNav 和 VLN 的自然语言空间提升到多模态空间,这意味着机器人可以同时接受自然语言和 / 或图像指令,从而实现另一次飞跃。例如,一个不熟悉某栋建筑的人可以一边拿着塑料箱子一边问:「我应该把这个还到哪里去?」,机器人会根据语言和视觉上下文引导用户把箱子还到架子上。他们将这类导航任务称为多模态指示导航(MIN)。
MIN 是一项广泛的任务,包括环境探索和指令引导导航。不过,在许多情况下,人们可以通过充分利用示范游览视频来绕过探索。示范游览有几个好处:
易于收集:用户可以遥控机器人,或者在环境中行走时用智能手机录制视频。此外,还有一些探索算法可用于创建导览。
它符合用户的习惯做法:当用户得到一个新的家用机器人时,自然会带着机器人在家里转转,他们可以在参观过程中口头介绍感兴趣的地点。
在某些情况下,出于安全和保护隐私的目的,限制机器人在预先设定的区域内活动是可取的。为此,作者在本文中介绍并研究了这一类任务,即「多模态指示游览导航(MINT)」,它利用示范游览,重点是满足用户的多模态指示。
最近,大型视觉语言模型(VLMs)在解决 MINT 问题上显示出巨大潜力,这得益于它们在语言、图像理解以及常识推理方面令人印象深刻的能力,这些都是实现 MINT 的关键要素。然而,单靠 VLM 难以解决 MINT 问题,原因如下:
由于上下文长度的限制,许多 VLM 的输入图像数量非常有限,这严重限制了大型环境中环境理解的保真度。
解决 MINT 问题需要计算机器人的行动。请求此类机器人动作的查询通常与 VLM(预)训练的内容不一致。因此,机器人的零样本性能往往不能令人满意。
为了解决 MINT 问题,DeepMind 提出了 Mobility VLA,这是一种分层式视觉 – 语言 – 行动(VLA)导航策略。它结合了长上下文 VLM 的环境理解和常识推理能力,以及基于拓扑图的稳健 low-level 导航策略。
具体来说,high-level VLM 使用示范游览视频和多模态用户指令来找到游览视频中的目标帧。接下来,一个经典的 low-level 策略使用目标帧和拓扑图(从游览帧中离线构建)在每个时间步生成机器人动作(航点,waypoint)。长上下文 VLM 的使用解决了环境理解的保真度问题,拓扑图则弥补了 VLM 的训练分布与解决 MINT 所需的机器人行动之间的差距。
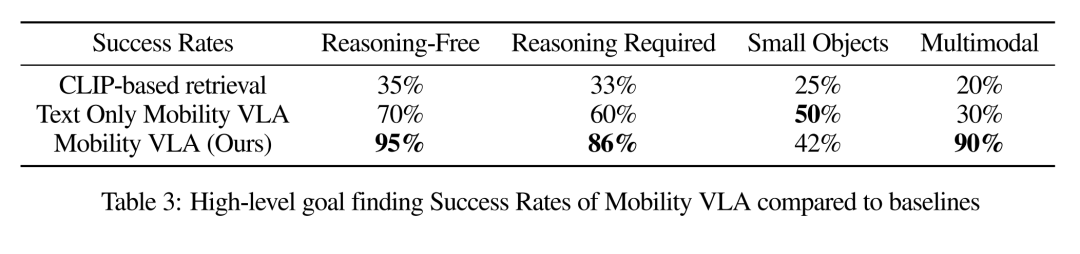
作者在现实世界(836 平方米)的办公室和类似家庭的环境中对移动 VLA 进行了评估。在之前难以实现的涉及复杂推理(例如「我想把东西存放在公众视线之外,我该去哪里?」)和多模态用户指令的 MINT 任务上,Mobility VLA 达到了 86% 和 90% 的成功率(分别比基线方法高出 26% 和 60%)。
作者还展示了用户与机器人互动的便捷性的巨大进步,用户可以在家庭环境中使用智能手机进行带解说的视频漫游,然后询问「我的杯垫放在哪里了?」
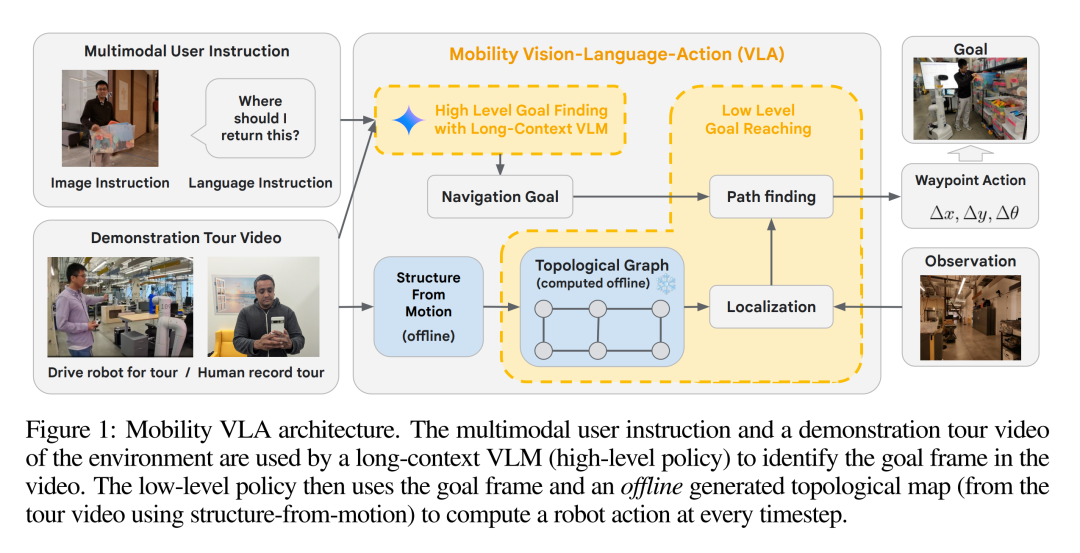
Mobilit VLA 是一种分层导航策略(如图 1 所示),包括在线和离线两个部分。
在离线阶段,根据示范游览(N,F)生成拓扑图 G。在在线阶段,high-level 策略通过示范游览和多模态用户指令(d,I)找到导航目标帧索引 g,该索引是一个整数,对应于游览的特定帧。下一步,low-level 策略利用拓扑图、当前摄像头观测数据(O)和 g,在每个时间步产生一个航点动作(a),供机器人执行。
其中,h 和 l 分别代表 high-level 和 low-level 策略。
Mobility VLA 利用环境示范游览来解决 MINT 问题。这种游览可以由人类用户通过远程操作进行,也可以在环境中行走时用智能手机录制视频。
然后,Mobility VLA 会离线构建拓扑图 G = (V,E),其中每个顶点 v_i∈V 都对应演示游览视频 (F, N) 中的帧 f_i。作者使用 COLMAP(一种现成的运动结构管道)来确定每帧的近似 6 自由度相机姿态,并将其存储在顶点中。接下来,如果目标顶点位于源顶点的「前方」(与源顶点的姿态相差小于 90 度),且距离在 2 米以内,则会在 G 中添加一条有向边。
与传统的导航 pipeline(例如绘制环境地图、识别可穿越区域,然后构建 PRM)相比,拓扑图方法要简单得多,因为它能根据游览轨迹捕捉环境的一般连通性。
基于长上下文多模态 VLM 的 High-Level 目标寻找
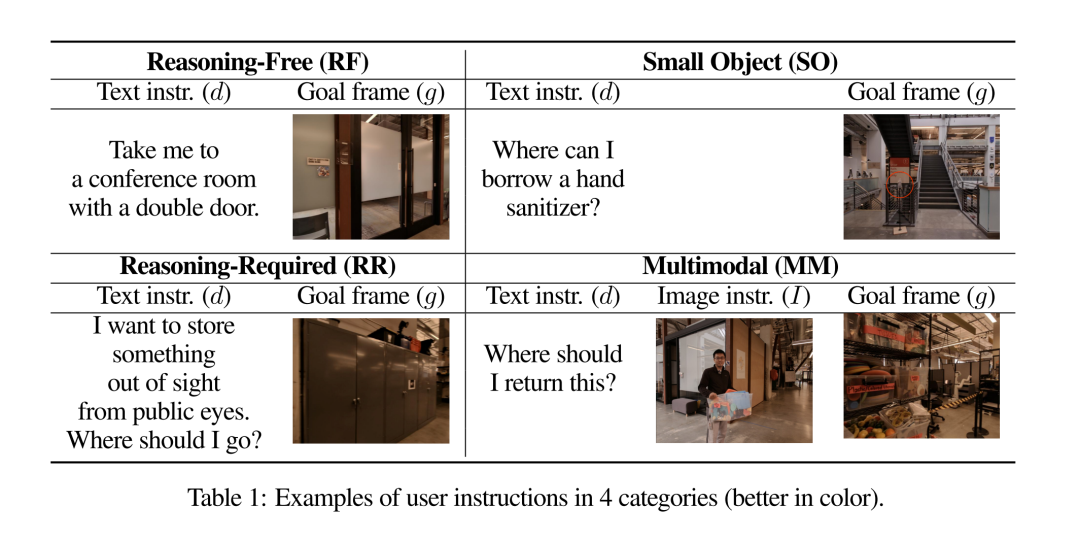
在在线执行过程中,high-level 策略利用 VLM 的常识推理能力,从示范游览中确定一个导航目标,以满足各种多模态、口语化且往往含糊不清的用户指令。为此,研究者准备了一个由文字和图像交错组成的提示 P (F,N,d,I)。下面是多模态用户指令的一个具体例子,对应的是表 1 中的一个问题 ——「Where should I return this?」。
这一切离不开一个叫 Mobility VLA 的导航策略。
论文标题:Mobility VLA: Multimodal Instruction Navigation with Long-Context VLMs and Topological Graphs
论文链接:https://arxiv.org/pdf/2407.07775v1
DeepMind 表示,这项工作代表了人机交互的下一步。未来,用户可以简单地用智能手机拍摄他们的环境游览经历。在看过视频后,他们的个人机器人助手就能理解并在环境中导航。
Mobility VLA:利用长上下文 VLM 和拓扑图进行多模态指令导航
随着 AI 技术的不断发展,机器人导航已经取得了长足进步。早期的工作依赖于用户在预先绘制的环境中指定物理坐标。物体目标导航(ObjNav)和视觉语言导航(VLN)是机器人可用性的一大飞跃,因为它们允许用户使用开放词汇语言来定义导航目标,如「去沙发那里」。
为了让机器人在我们的日常生活中真正有用并无处不在,谷歌 DeepMind 的研究者提出将 ObjNav 和 VLN 的自然语言空间提升到多模态空间,这意味着机器人可以同时接受自然语言和 / 或图像指令,从而实现另一次飞跃。例如,一个不熟悉某栋建筑的人可以一边拿着塑料箱子一边问:「我应该把这个还到哪里去?」,机器人会根据语言和视觉上下文引导用户把箱子还到架子上。他们将这类导航任务称为多模态指示导航(MIN)。
MIN 是一项广泛的任务,包括环境探索和指令引导导航。不过,在许多情况下,人们可以通过充分利用示范游览视频来绕过探索。示范游览有几个好处:
易于收集:用户可以遥控机器人,或者在环境中行走时用智能手机录制视频。此外,还有一些探索算法可用于创建导览。
它符合用户的习惯做法:当用户得到一个新的家用机器人时,自然会带着机器人在家里转转,他们可以在参观过程中口头介绍感兴趣的地点。
在某些情况下,出于安全和保护隐私的目的,限制机器人在预先设定的区域内活动是可取的。为此,作者在本文中介绍并研究了这一类任务,即「多模态指示游览导航(MINT)」,它利用示范游览,重点是满足用户的多模态指示。
最近,大型视觉语言模型(VLMs)在解决 MINT 问题上显示出巨大潜力,这得益于它们在语言、图像理解以及常识推理方面令人印象深刻的能力,这些都是实现 MINT 的关键要素。然而,单靠 VLM 难以解决 MINT 问题,原因如下:
由于上下文长度的限制,许多 VLM 的输入图像数量非常有限,这严重限制了大型环境中环境理解的保真度。
解决 MINT 问题需要计算机器人的行动。请求此类机器人动作的查询通常与 VLM(预)训练的内容不一致。因此,机器人的零样本性能往往不能令人满意。
为了解决 MINT 问题,DeepMind 提出了 Mobility VLA,这是一种分层式视觉 – 语言 – 行动(VLA)导航策略。它结合了长上下文 VLM 的环境理解和常识推理能力,以及基于拓扑图的稳健 low-level 导航策略。
具体来说,high-level VLM 使用示范游览视频和多模态用户指令来找到游览视频中的目标帧。接下来,一个经典的 low-level 策略使用目标帧和拓扑图(从游览帧中离线构建)在每个时间步生成机器人动作(航点,waypoint)。长上下文 VLM 的使用解决了环境理解的保真度问题,拓扑图则弥补了 VLM 的训练分布与解决 MINT 所需的机器人行动之间的差距。
作者在现实世界(836 平方米)的办公室和类似家庭的环境中对移动 VLA 进行了评估。在之前难以实现的涉及复杂推理(例如「我想把东西存放在公众视线之外,我该去哪里?」)和多模态用户指令的 MINT 任务上,Mobility VLA 达到了 86% 和 90% 的成功率(分别比基线方法高出 26% 和 60%)。
作者还展示了用户与机器人互动的便捷性的巨大进步,用户可以在家庭环境中使用智能手机进行带解说的视频漫游,然后询问「我的杯垫放在哪里了?」
Mobilit VLA 是一种分层导航策略(如图 1 所示),包括在线和离线两个部分。
在离线阶段,根据示范游览(N,F)生成拓扑图 G。在在线阶段,high-level 策略通过示范游览和多模态用户指令(d,I)找到导航目标帧索引 g,该索引是一个整数,对应于游览的特定帧。下一步,low-level 策略利用拓扑图、当前摄像头观测数据(O)和 g,在每个时间步产生一个航点动作(a),供机器人执行。
其中,h 和 l 分别代表 high-level 和 low-level 策略。
Mobility VLA 利用环境示范游览来解决 MINT 问题。这种游览可以由人类用户通过远程操作进行,也可以在环境中行走时用智能手机录制视频。
然后,Mobility VLA 会离线构建拓扑图 G = (V,E),其中每个顶点 v_i∈V 都对应演示游览视频 (F, N) 中的帧 f_i。作者使用 COLMAP(一种现成的运动结构管道)来确定每帧的近似 6 自由度相机姿态,并将其存储在顶点中。接下来,如果目标顶点位于源顶点的「前方」(与源顶点的姿态相差小于 90 度),且距离在 2 米以内,则会在 G 中添加一条有向边。
与传统的导航 pipeline(例如绘制环境地图、识别可穿越区域,然后构建 PRM)相比,拓扑图方法要简单得多,因为它能根据游览轨迹捕捉环境的一般连通性。
基于长上下文多模态 VLM 的 High-Level 目标寻找
在在线执行过程中,high-level 策略利用 VLM 的常识推理能力,从示范游览中确定一个导航目标,以满足各种多模态、口语化且往往含糊不清的用户指令。为此,研究者准备了一个由文字和图像交错组成的提示 P (F,N,d,I)。下面是多模态用户指令的一个具体例子,对应的是表 1 中的一个问题 ——「Where should I return this?」。
You are a robot operating in a building and your task is to respond to the user command about going to a specific location by finding the closest frame in the tour video to navigate to . These frames are from the tour of the building last year . [ Frame 1 Image f1] Frame 1. [ Frame narrative n1] ... [ Frame k Image fk ] Frame k . [ Frame narrative nk ] This image is what you see now . You may or may not see the user in this image . [ Image Instruction I] The user says : Where should I return this ? How would you respond ? Can you find the closest frame ?
一旦 high-level 策略确定了目标帧索引 g,low-level 策略(算法 1)就会接手,并在每个时间步产生一个航点动作(公式 1)。
在每个时间步中,作者使用实时分层视觉定位系统,利用当前相机观测值 O 估算机器人的姿态 T 和最近的起始顶点 v_s∈G (第 5 行)。该定位系统通过全局描述符在 G 中找到 k 个最近的候选帧,然后通过 PnP 计算 T。接下来,通过 Dijkstra 算法(第 9 行)确定 v_s 与目标顶点 v_g(与 g 对应的顶点)之间拓扑图上的最短路径 S。最后,low-level 策略会返回一个航点动作,即 S 中下一个顶点 v_1 相对于 T 的 ∆x、∆y、∆θ(第 10 行)。
为了展示 Mobility VLA 的性能并进一步了解关键设计,作者设计了实验来回答以下研究问题:
问题 1:在现实世界中,Mobility VLA 在 MINT 中是否表现出色?
问题 2:Mobility VLA 是否会因为使用长上下文 VLM 而优于替代方案的性能?
问题 3:拓扑图是否必要?VLM 能否直接产生行动?
Mobility VLA 在现实环境中有着稳健的端到端表现
1、端到端成功率高。表 2 显示,在大多数用户指令类别中,Mobility VLA 的端到端导航成功率都很高,包括以前不可行的「推理 – 要求」和「多模态」指令。
2、稳健的 low-level 目标达成。表 2 还显示了 Mobility VLA 的 low-level 目标达成策略在现实世界中的稳健性(100% 成功率)。其中的示范游览记录是在实验前几个月录制的,当时许多物体、家具和照明条件都不同。
1、Mobility VLA 优于替代方案。表 3 显示,Mobility VLA 的 high-level 目标查找成功率明显高于对比方法。鉴于 low-level 成功率为 100%,这一 high-level 目标查找成功率代表了端到端成功率。
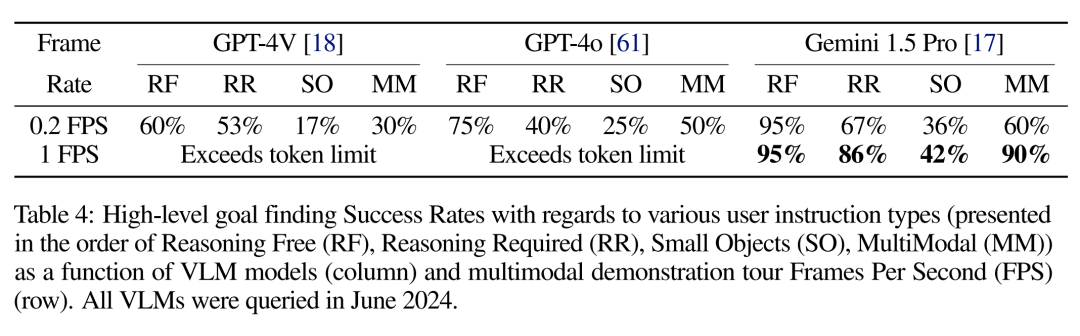
2、使用长上下文 VLM 处理高帧率游览视频是成功的关键。向非长上下文 VLM 输入大型环境的完整示范游览是一项挑战,因为每幅图像都需要数百个 token 的预算。减少输入 token 数量的一个解决方案是降低游览视频帧频,但代价是中间帧丢失。表 4 显示,随着游览帧频的降低,high-level 目标查找成功率也在降低。这并不奇怪,因为帧率较低的游览视频有时会丢失导航目标帧。此外,在比较最先进的 VLM 时,只有 Gemini 1.5 Pro 的成功率令人满意,这要归功于其长达 100 万个 token 的上下文长度。
表 5 显示了 Mobility VLA 在模拟中的端到端性能与提示 VLM 直接输出航点操作的比较。0% 的端到端成功率表明,Gemini 1.5 Pro 在没有拓扑图的情况下无法实现机器人的零样本导航。根据实验,作者发现无论当前摄像头的观测结果如何,Gemini 几乎总是输出「向前移动」的航点动作。此外,当前的 Gemini 1.5 API 需要在每次推理调用时上传全部 948 幅游览图像,导致机器人每移动 1 米就需要花费 26 秒的运行时间,成本之高令人望而却步。另一方面,Mobility VLA 的 high-level VLM 会花费 10-30 秒找到目标索引,然后机器人会使用 low-level 拓扑图导航到目标,从而形成一个高度稳健和高效(每步 0.19 秒)的系统来解决 MINT 问题。
以上就是Gemini 1.5 Pro装进机器人,参观一遍公司就能礼宾、带路的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/792228.html



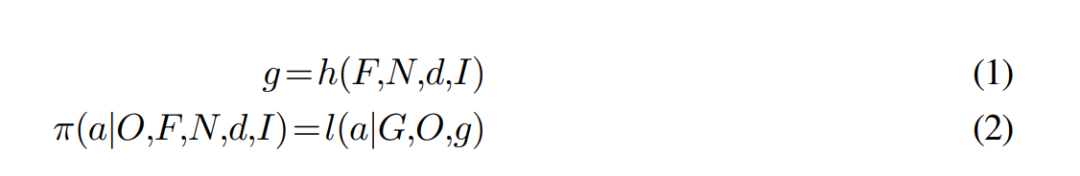



 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 

























