
大模型排行榜哪家强?还看LLM竞技场~
截至此刻,已有共计90名LLM加入战斗,用户总投票数超过了77万。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜
 图片
图片
然而,在网友们吃瓜调侃新模型冲榜、老模型丧失尊严的同时,
人家竞技场背后的组织LMSYS,已经悄悄完成了成果转化:从实战中诞生的最有说服力的基准测试——Arena-Hard。
 图片
图片
而Arena-Hard所展现出的四项优势,也正是当前的LLM基准测试最需要的:
-可分离性(87.4%)明显优于mt-bench(22.6%);
-与Chatbot Arena的排名最相近,达到89.1%;
-运行速度快,价格便宜(25美元)
-频繁更新实时数据
中译中一下就是,首先这个大模型的考试要有区分度,不能让学渣也考到90分;
其次,考试的题目应该更贴合实际,并且打分的时候要严格对齐人类偏好;
最后一定不能泄题,所以测试数据要经常更新,保证考试的公平;
——后两项要求对于LLM竞技场来说,简直像是量身定做。
我们来看一下新基准测试的效果:
 图片
图片
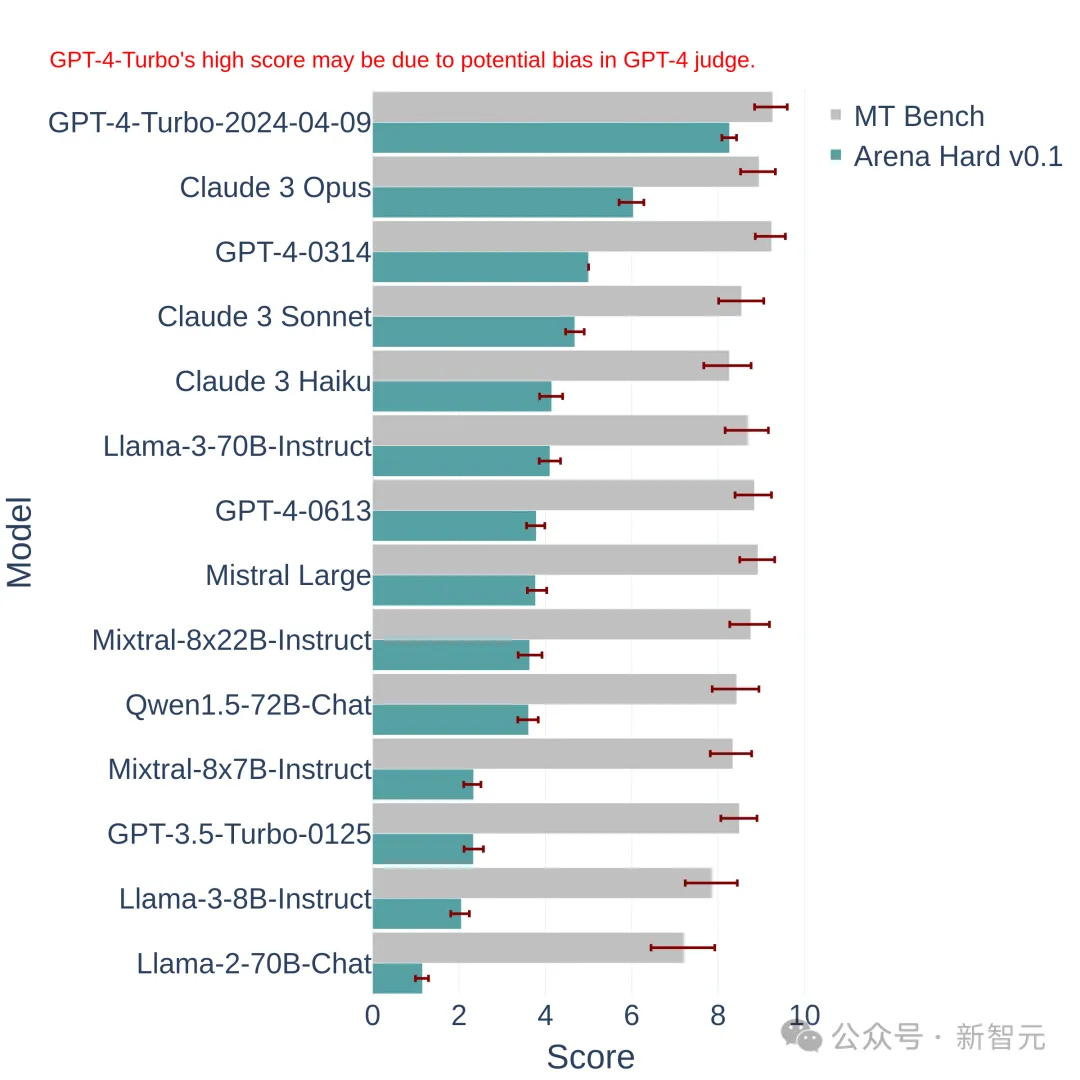
上图中将Arena Hard v0.1,与之前的SOTA基准测试MT Bench进行了比较。
我们可以发现,Arena Hard v0.1与MT Bench相比,具有更强的可分离性(从22.6%飙升到了87.4%),并且置信区间也更窄。
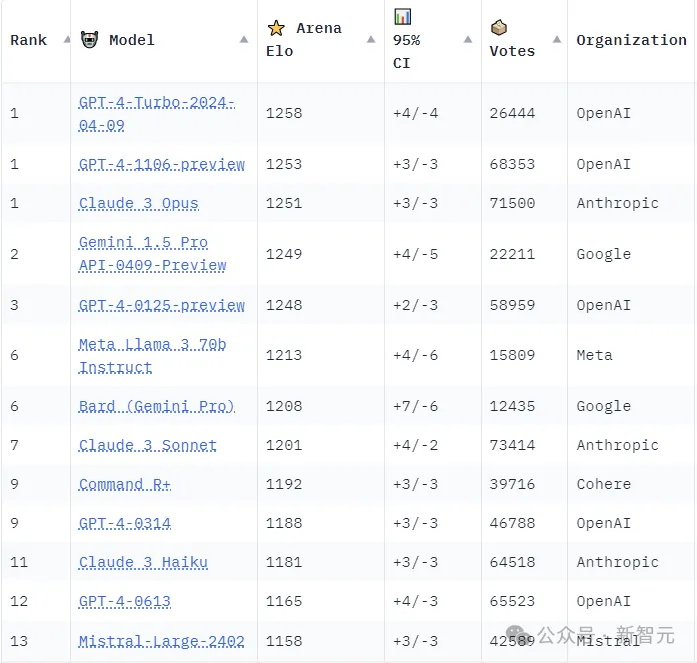
另外,看下这个排名,与下面最新的LLM竞技场排行榜是基本一致的:
 图片
图片
这说明Arena Hard的评测非常接近人类的偏好(89.1%)。
——Arena Hard也算是开辟了众包的新玩法:
网友获得了免费的体验,官方平台获得了最有影响力的排行榜,以及新鲜的、高质量的数据——没有人受伤的世界完成了。

给大模型出题
下面看下如何构建这个基准测试。
简单来说,就是怎么从竞技场的20万个用户提示(问题)中,挑出来一些比较好的。
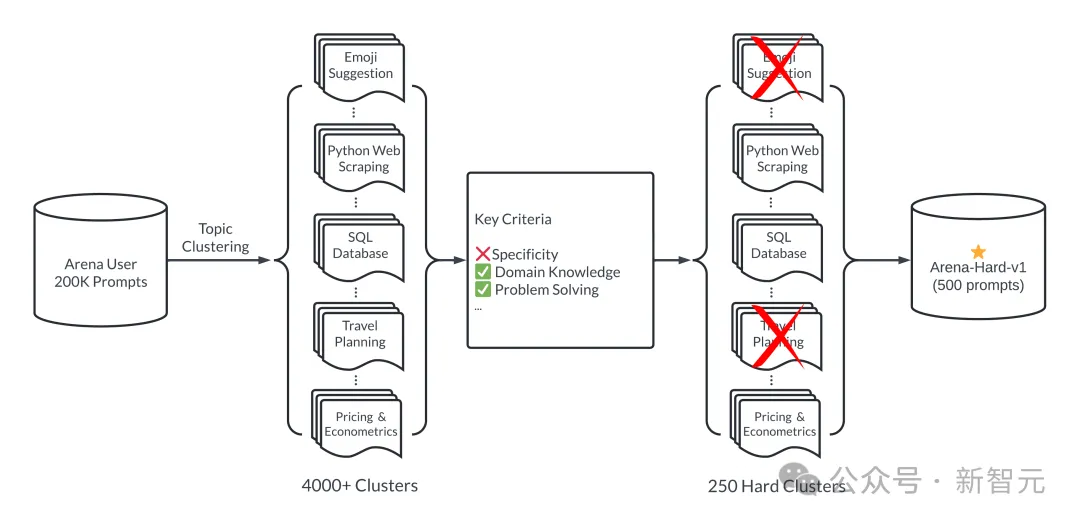
这个「好」体现在两方面:多样性和复杂性。下图展示了Arena-Hard的工作流:
 图片
图片
总结一波:首先对所有提示进行分类(这里分了4000多个主题),然后人为制定一些标准,对每个提示进行打分,同一类别的提示算平均分。
得分高的类别可以认为复杂性(或者质量)高——也就是Arena-Hard中「Hard」的含义。
选取前250个得分最高的类别(250保证了多样性),每个类别随机抽2位幸运提示,组成最终的基准测试集(500 prompts)。
下面详细展开:
多样性
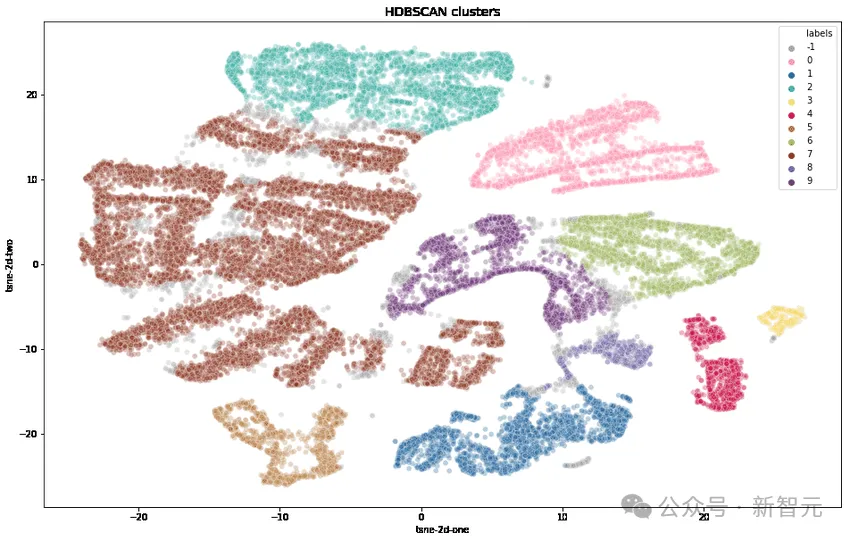
研究人员首先使用OpenAI的text-embedding-3-small转换每个提示,使用UMAP减少维度,并使用基于分层的聚类算法(HDBSCAN)来识别聚类,然后使用GPT-4-turbo进行汇总。
复杂性
通过下表的七个关键标准来选择高质量的用户查询:
 图片
图片
1.提示是否要求提供特定的输出?
2.是否涵盖一个或多个特定领域?
3.是否具有多个级别的推理、组件或变量?
4.是否直接让AI展示解决问题的能力?
 INFINITE ALBUM
INFINITE ALBUM
面向游戏玩家的生成式AI音乐
 144 查看详情
144 查看详情 
5.是否涉及一定程度的创造力?
6.是否要求响应的技术准确性?
7.是否与实际应用相关?
对于每个提示,使用LLM(GPT-3.5-Turbo、GPT-4-Turbo)标注其满足了多少个标准(打分0到7),然后,计算每组提示(聚类)的平均分数。
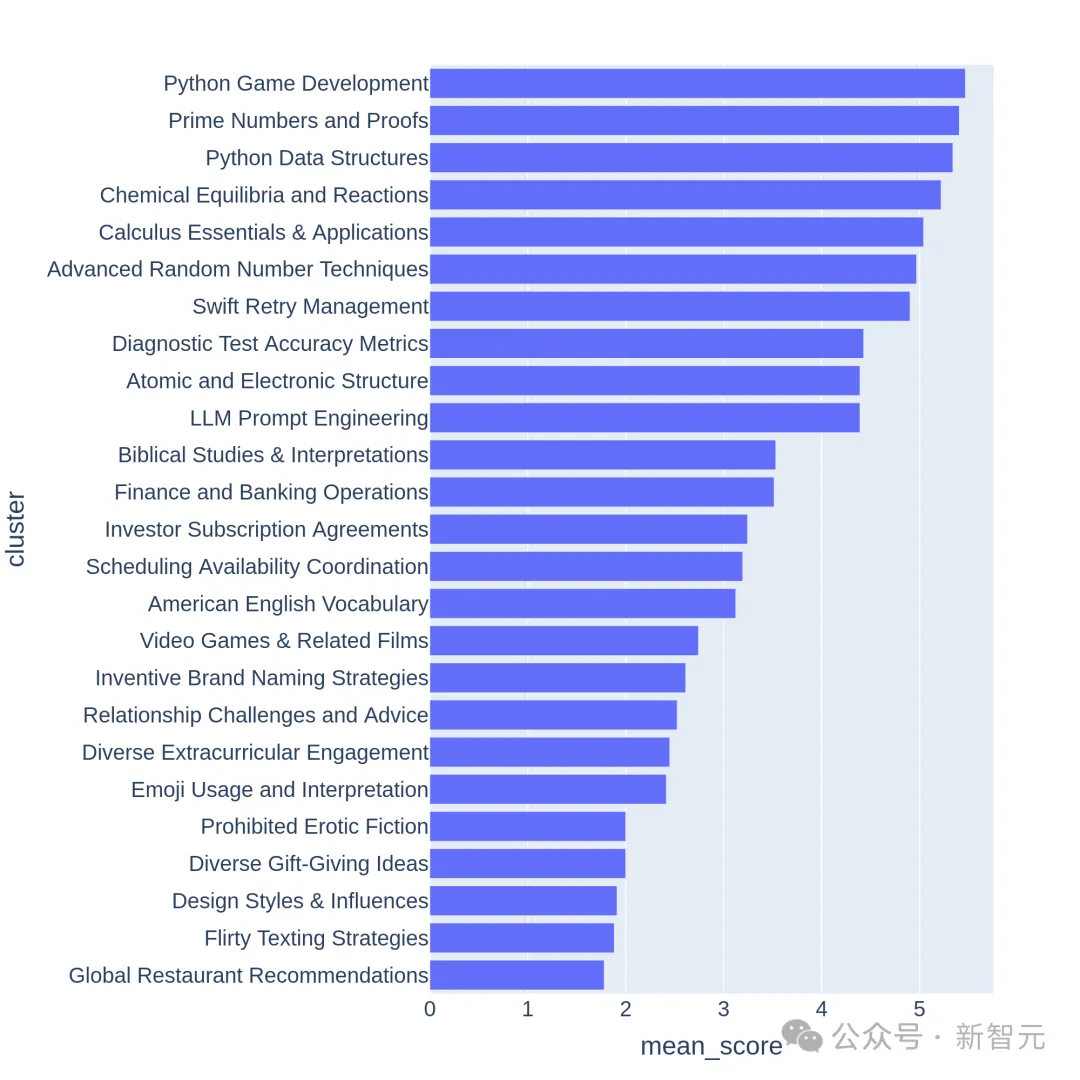
下图展示了部分聚类的平均分排序:
 图片
图片
我们可以观察到,得分较高的聚类通常是比较有挑战性的主题(比如游戏开发、数学证明),而分数较低的聚类则属于琐碎或模棱两可的问题。
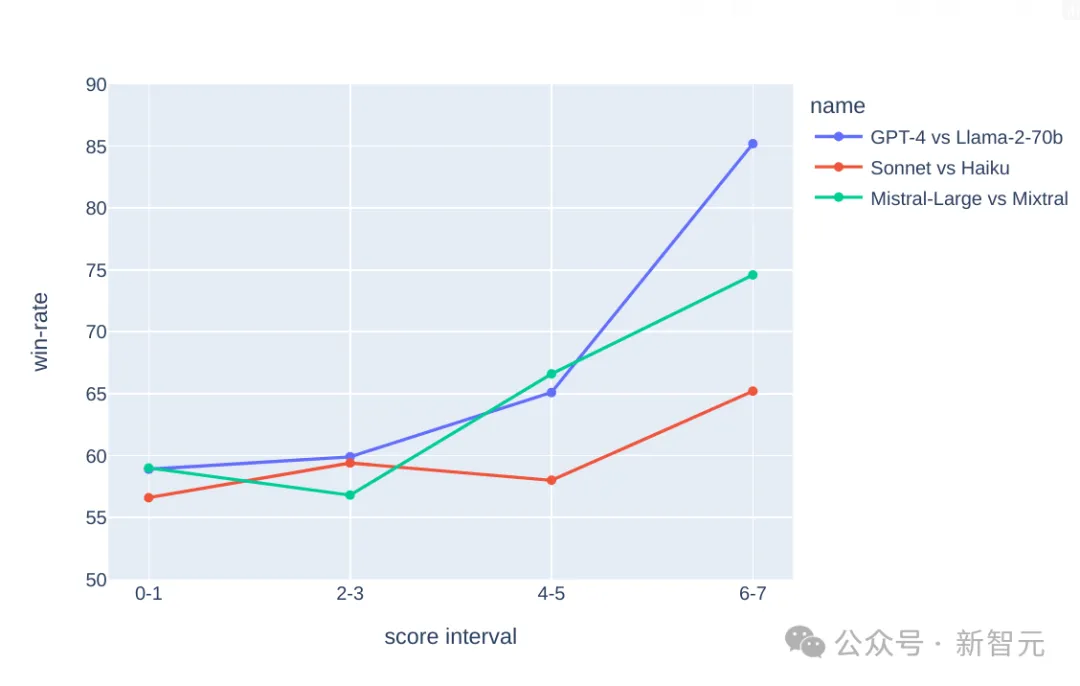
有了这个复杂性,就可以拉开学霸与学渣之间的差距,我们看下面的实验结果:
 图片
图片
在上面的3个比较中,假设GPT-4比Llama2-70b强、Claude的大杯比中杯强,Mistral-Large比Mixtral强,
我们可以看到,随着(复杂性)分数的增加,更强的模型的胜率也在提高——学霸获得区分、学渣获得过滤。
因为分数越好高(问题越复杂),区分度越好,所以最终选取了250 个平均得分>=6分(满分7分)的高质量分类。
然后,随机抽取每个类别的2个提示,形成了这版基准测试—— Arena-Hard-v0.1。
判卷老师靠谱吗?
试卷出完了,谁来判卷是个问题。
人工当然是最准的,而且因为这是「Hard模式」,很多涉及领域知识的问题还需要专家前来评估——这显然不行。
那么退而求其次,选择目前公认的最聪明的模型GPT-4来当判卷老师。
比如上面的那些图表中,涉及打分的环节,都是交给GPT-4来做的。另外,研究人员使用CoT提示LLM,在做出判决之前先生成答案。
GPT-4 判出的结果
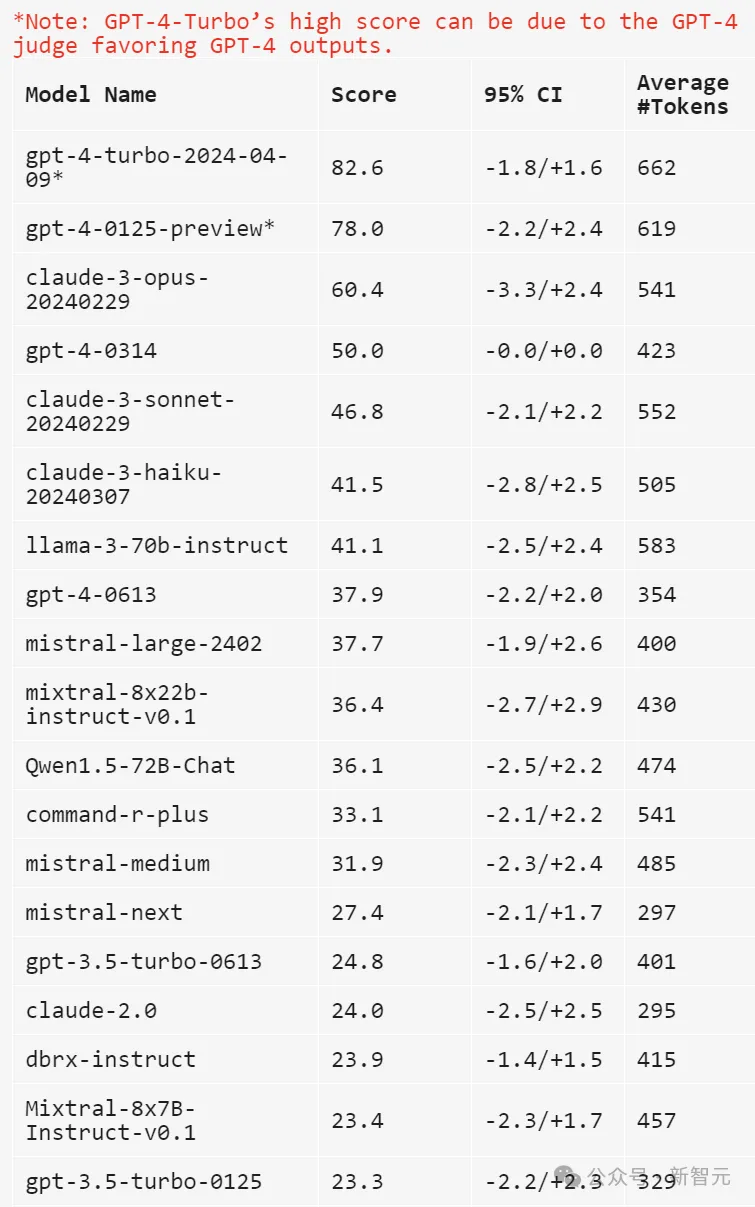
下面使用gpt-4-1106-preview作为判断模型,用于比较的基线采用gpt-4-0314。
 图片
图片
上表中比较并计算了每个模型的Bradley-Terry系数,并转换为相对于基线的胜率作为最终分数。95%置信区间是通过100轮引导计算得出的。
克劳德表示不服
——我Claude-3 Opus也是排行榜并列第一啊,凭啥让GPT当判卷老师?
于是,研究人员比较GPT-4-1106-Preview和Claude-3 Opus作为判卷老师的表现。
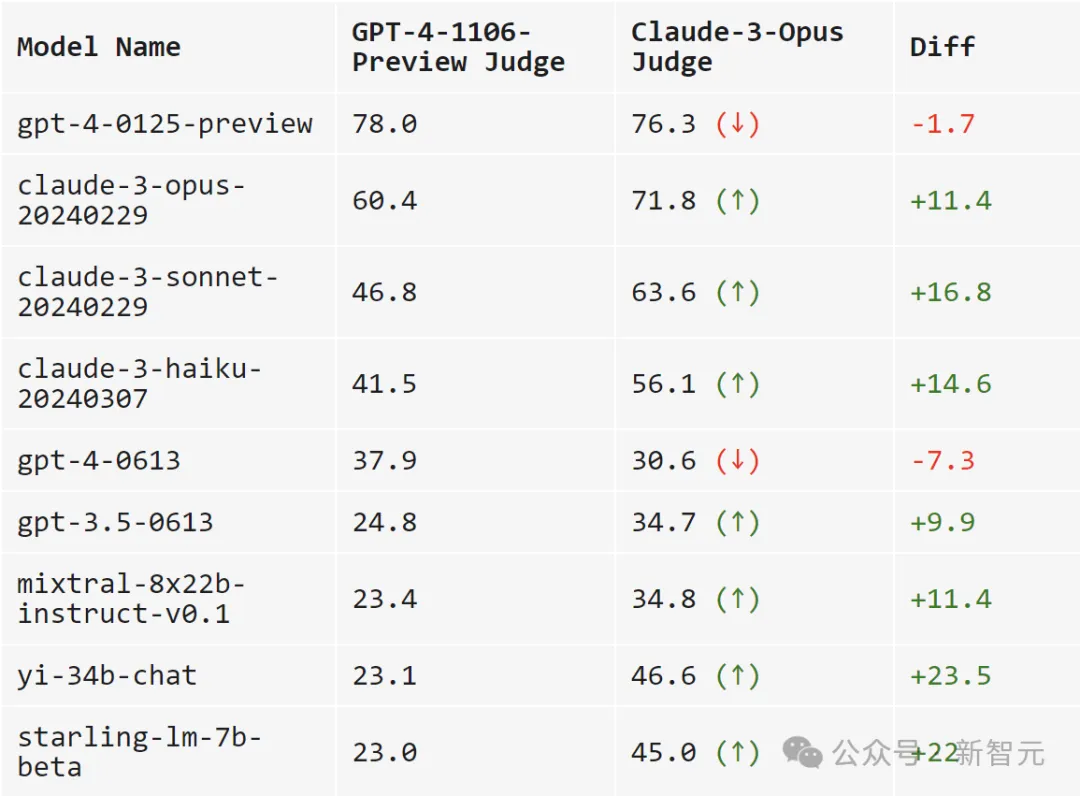
一句话总结:GPT-4是严父,Claude-3是慈母。
 图片
图片
当使用GPT-4打分时,跨模型的可分离性更高(范围从23.0到78.0)。
而当使用Claude-3时,模型的得分大多都提高了不少:自家的模型肯定要照顾,开源模型也很喜欢(Mixtral、Yi、Starling),gpt-4-0125-preview也确实比我更好。
Claude-3甚至爱gpt-3.5-0613胜过gpt-4-0613。
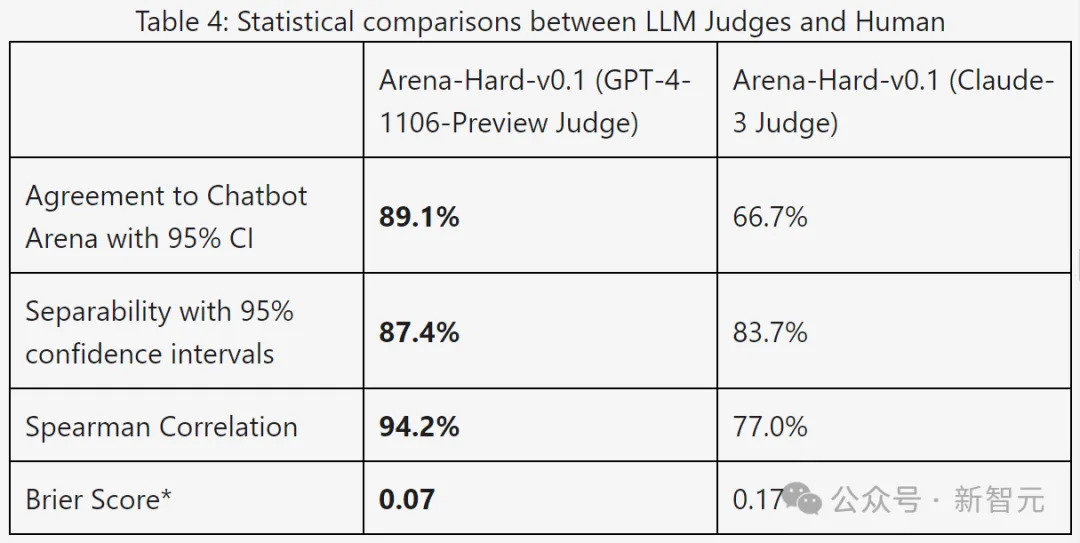
下表使用可分离性和一致性指标进一步比较了GPT-4和Claude-3:
 图片
图片
从结果数据来看,GPT-4在所有指标上都明显更好。
通过手动比较了GPT-4和Claude-3之间的不同判断示例,可以发现,当两位LLM意见不一致时,通常可以分为两大类:
保守评分,以及对用户提示的不同看法。
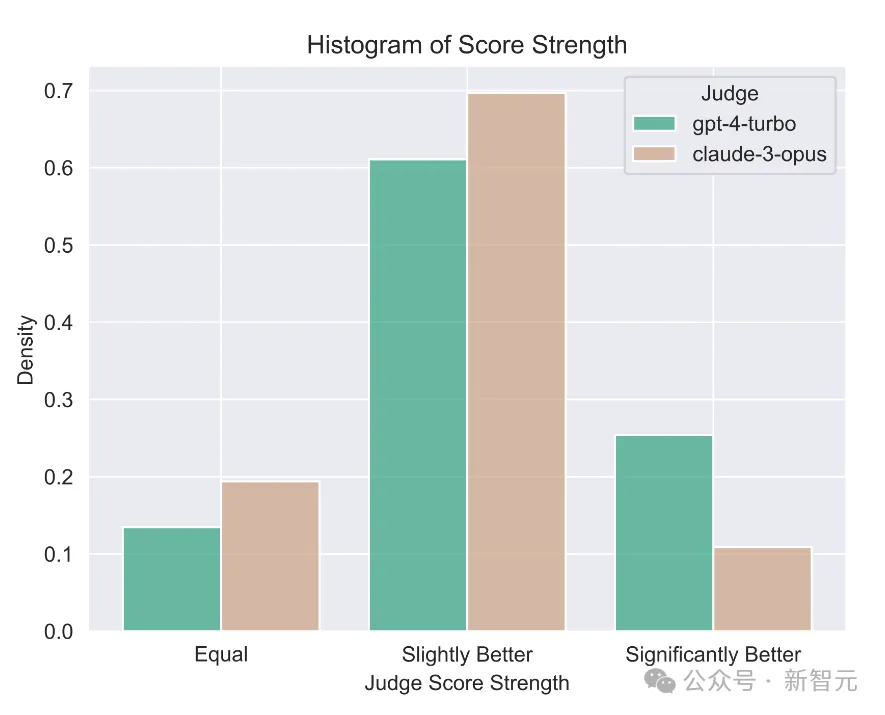
Claude-3-Opus在给分时比较宽容,给出苛刻分数的可能性要小得多——它特别犹豫是否要宣称一个回答比另一个回答「好得多」。
相比之下,GPT-4-Turbo会识别模型响应中的错误,并以明显较低的分数惩罚模型。
另一方面,Claude-3-Opus有时会忽略较小的错误。即使Claude-3-Opus确实发现了这些错误,它也倾向于将它们视为小问题,并在评分过程中非常宽容。
即使是在编码和数学问题中,小错误实际上会完全破坏最终答案,但Claude-3-Opus仍然对这些错误给予宽大处理,GPT-4-Turbo则不然。
 图片
图片
对于另外一小部分提示,Claude-3-Opus和GPT-4-Turbo以根本不同的角度进行判断。
例如,给定一个编码问题,Claude-3-Opus倾向于不依赖外部库的简单结构,这样可以为用户提供最大教育价值的响应。
而GPT-4-Turbo可能会优先考虑提供最实用答案的响应,而不管它对用户的教育价值如何。
虽然这两种解释都是有效的判断标准,但GPT-4-Turbo的观点可能与普通用户更接近。
有关不同判断的具体例子,参见下图,其中许多都表现出这种现象。
 图片
图片
局限性测试
LLM喜欢更长的回答吗?
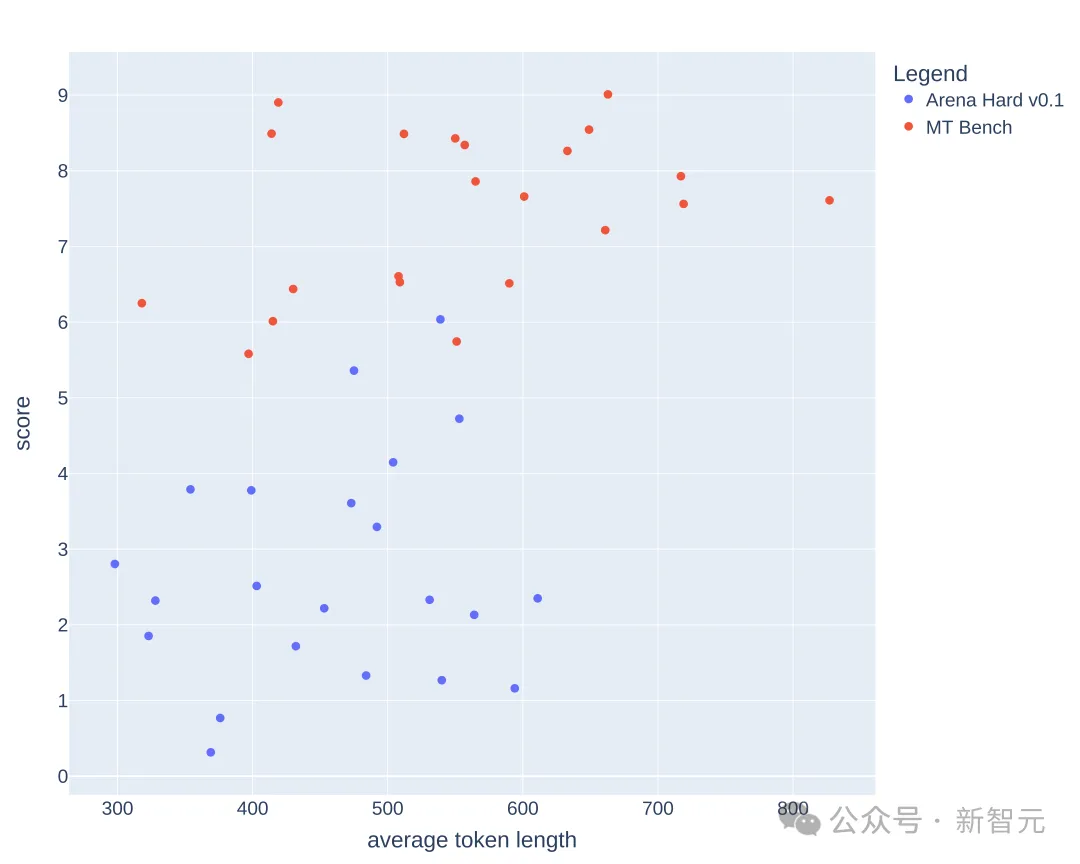
下面绘制了在MT-Bench和Arena-Hard-v0.1上,每个模型的平均token长度和分数。从视觉上看,分数和长度之间没有很强的相关性。
 图片
图片
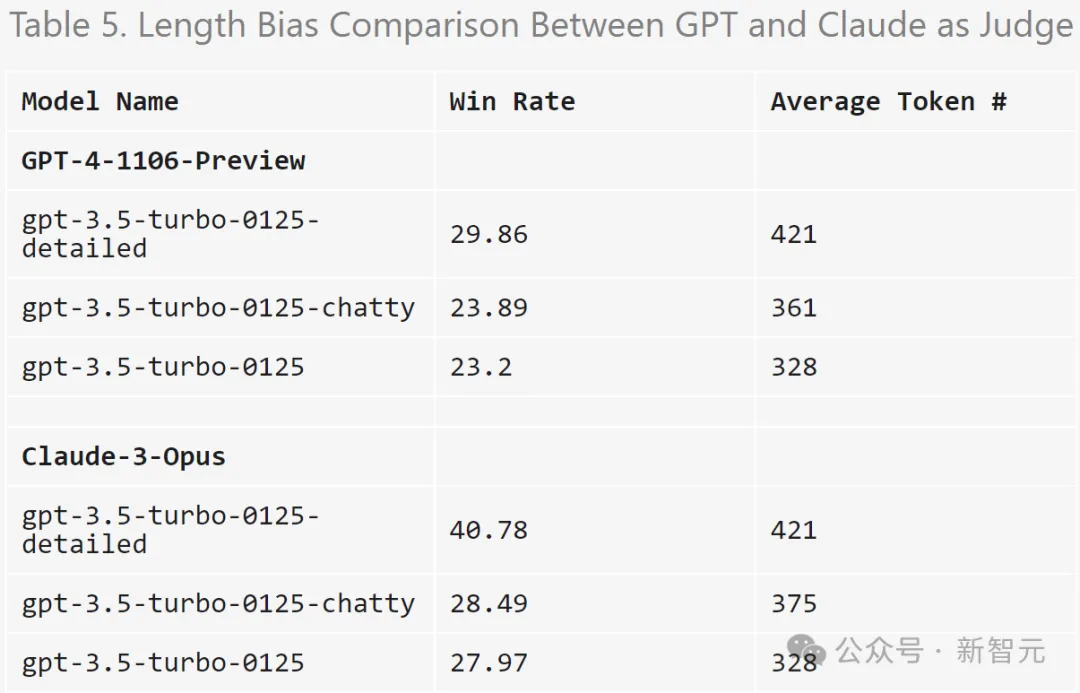
为了进一步检查潜在的冗长偏差,研究人员使用GPT-3.5-Turbo对三种不同的系统提示(原始、健谈、详细)进行了消融。
结果表明,GPT-4-Turbo和Claude-3-Opus的判断都可能受到更长输出的影响,而Claude受到的影响更大(因为GPT-3.5-Turbo对GPT-4-0314的胜率超过40%)。
有趣的是,「健谈」对两位裁判的胜率影响不大,这表明输出长度不是唯一的因素,更详细的答案也可能受到LLM评委的青睐。
 图片
图片
实验使用的提示:
detailed: You are a helpful assistant who thoroughly explains things with as much detail as possible.
chatty: You are a helpful assistant who is chatty.
GPT-4 判断的方差
研究人员发现,即使温度=0,GPT-4-Turbo仍可能产生略有不同的判断。
下面对gpt-3.5-turbo-0125的判断重复三次并计算方差。
 图片
图片
由于预算有限,这里只对所有模型进行一次评估。不过作者建议使用置信区间来确定模型分离。
参考资料:https://www.php.cn/link/c30ca4400db3c72274c8ad819f688c21
以上就是众包新玩法!LLM竞技场诞生基准测试,严格分离学渣学霸的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/795646.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 

















