
ocr图片识别通常可以借助tesserocr模块,将图片中的内容识别出来并转换为文本输出。tesserocr是python的一个ocr识别库,是对tesseract进行的一层python api封装。在安装tesserocr之前,需要先安装tesseract。
tesseract文件可从以下链接下载:
https://www.php.cn/link/2ae3d2aaceaf26246581744124859b07
Python安装tesserocr可以通过下载对应的.whl文件来安装(使用pip方式容易出错)。
tesseract与对应的tesserocr版本可从以下链接获取:
立即学习“Python免费学习笔记(深入)”;
https://www.php.cn/link/1ba4d572a08babfe8c7d9c9717ec1599
实现代码如下:
from PIL import Imageimport tesserocrtesserocr识别图片的两种方法
img = Image.open("code.jpg")verify_code1 = tesserocr.image_to_text(img)
print(verify_code1)
verify_code2 = tesserocr.file_to_text("code.jpg")
print(verify_code2)
然而,当图片中存在大量干扰元素,如验证码中的多余线条时,识别结果可能不够准确。这时需要进行一些预处理操作,如转换为灰度图和进行二值化处理。
可以使用Image对象的convert()方法,将图片转换为灰度图,传入”L”参数;传入1参数则对图像进行二值处理(默认阈值为127)。
原验证码:

img = Image.open("code.jpg")img_L = img.convert("L")img_L.show()

也可以自定义二值化阈值:
threshold = 100 # 设置二值的阈值为100table = []for i in range(256):if i < threshold:table.append(0)else:table.append(1)point()方法返回给定查找表对应的图像像素值的拷贝,变量table为图像的每个通道设置256个值,为输出图像指定一个新的模式,模式为"L"和"P"的图像进一步转换为模式为"1"的图像
image = img_L.point(table, "1")image.show()

img_1 = tesserocr.image_to_text(image)print(img_1)>> 5SA6
操作系统:Win10 1709 X64
Python版本:3.6.5
依赖模块:PIL、tesserocr。
需要说明的是,在Windows系统上通过PowerShell使用pip3 install tesserocr安装验证码识别模块时,需要先安装Tesseract(一款由HP实验室开发、由Google维护的开源OCR引擎,与Microsoft Office Document Imaging(MODI)相比,我们可以不断训练的库,使图像转换文本的能力不断增强)。
以中国知网的注册页面为例,我们常被要求输入这类简单的字母组成,背景含有很多杂线的验证码,如下图所示:
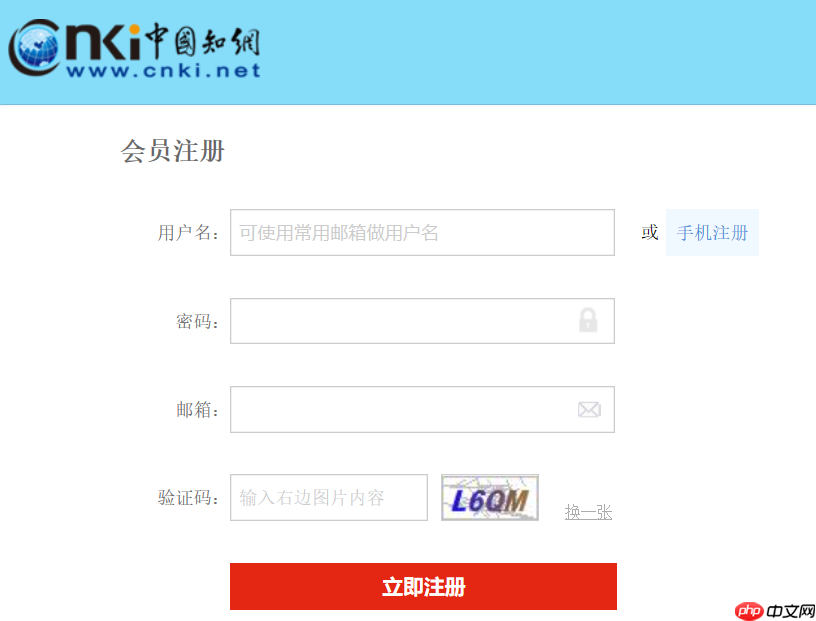
我们将验证码另存为到本地代码所在目录,取名:test.png。
下图是直接使用对应模块识别的代码示例:
import tesserocrfrom PIL import Imageimage = Image.open('test.png')image.show() # 可以打印出图片,供预览print(tesserocr.image_to_text(image))

原始图片尺寸较小,极少数情况下如果无法正常识别,可以借助图片处理工具PIL模块进行图片等比例放大后保存。此例中直接运行上述代码,结果为“VHIHI”,即使是肉眼可见较为清晰的验证码,如果图片未经处理直接交由tesserocr解析,也可能识别率很低。
通常情况下,我们还需要做一些额外的图片处理,如转换为灰度图、二值化等。
利用Image对应的convert()方法传参L,即可将图片转换为灰度图。
image = image.convert('L')image.show()
传入1即可完成二值化,如下:
image = image.convert('1')image.show()
当然,我们更多时候需要根据图片的实际情况指定二值化的阈值,比如我们将阈值设定为80,先转灰度图,再二值化,代码如下:
import tesserocrfrom PIL import Imageimage = Image.open('test.png')image = image.convert("L")threshold = 80table = []for i in range(256):if i < threshold:table.append(0)else:table.append(1)
观察到处理后的图片如右:

尽管图片已经转为灰度图,且过滤了大部分杂线,但是图片关键像素丢失严重,识别结果自然也不尽如人意,结果:“VH.”。
此时我们根据图片的实际情况,人为调整程序中预设的阈值到130,再观察:

这次的图片转换效果显著,我们再次查看识别结果,“VHRU”,与肉眼观察到的别无二致,合乎要求。
可见验证码的识别除了用好识别模块,还需要在必要时引入PIL(图片处理模块)进行图片预处理,预处理过程中的阈值等设定也存有技巧,不同的参数设定,会完全影响最终的识别率。
现实中很多网站的验证码要远比例子中的来得复杂,尤其是12306购票网站的验证码,使行为验证码开始高速发展,肉眼分辨起来都异常困难,这就要求我们对验证码的识别技术要不断提升,才能突破网站逐步升级的反爬虫机制。
以上就是python图形验证码模块tesserocr的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/80644.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 
























