
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

11 月 16 日消息,%ignore_a_1%公司近日发布新闻稿,介绍了小型人工智能模型 mirasol,可以回答有关视频的问题并创造新的记录。
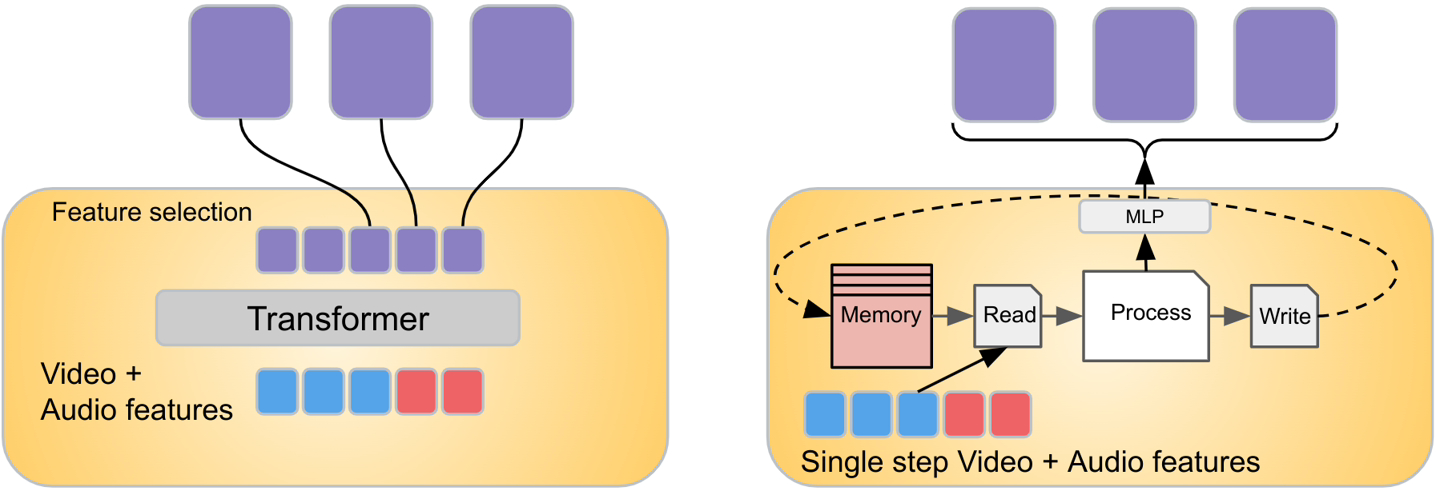
AI 模型目前很难处理不同的数据流,如果要让 AI 理解视频,需要整合视频、音频和文本等不同模态的信息,这大大增加了难度。
谷歌和谷歌 Deepmind 的研究人员提出了新的方法,将多模态理解扩展到长视频领域。
借助Mirasol AI模型,该团队努力解决两个关键挑战:
需要以高频采样同步视频和音频,但要异步处理标题和视频描述。视频和音频会生成大量数据,这会让模型的容量紧张。
在Mirasol中,谷歌采用了合路器和自回归转换器模型
该模型组件将处理时间同步的视频和音频信号,然后将视频拆分成独立的片段
 神采PromeAI
神采PromeAI
将涂鸦和照片转化为插画,将线稿转化为完整的上色稿。
 97 查看详情
97 查看详情 
转换器处理每个片段,并学习每个片段之间的联系,然后使用另一个转换器处理上下文文本,这两个组件交换有关其各自输入的信息。
一个新的转换模块名为Combiner,能够从每个片段中提取通用表示,并通过降维来压缩数据。每个片段包含4到64帧,该模型目前拥有30亿个参数,能够处理128到512帧的视频

在测试中,Mirasol3B 在视频问题分析方面达到了新的基准,体积明显更小,并且可以处理更长的视频。通过使用带有内存的组合器变体,该团队能够进一步降低所需的计算能力18%

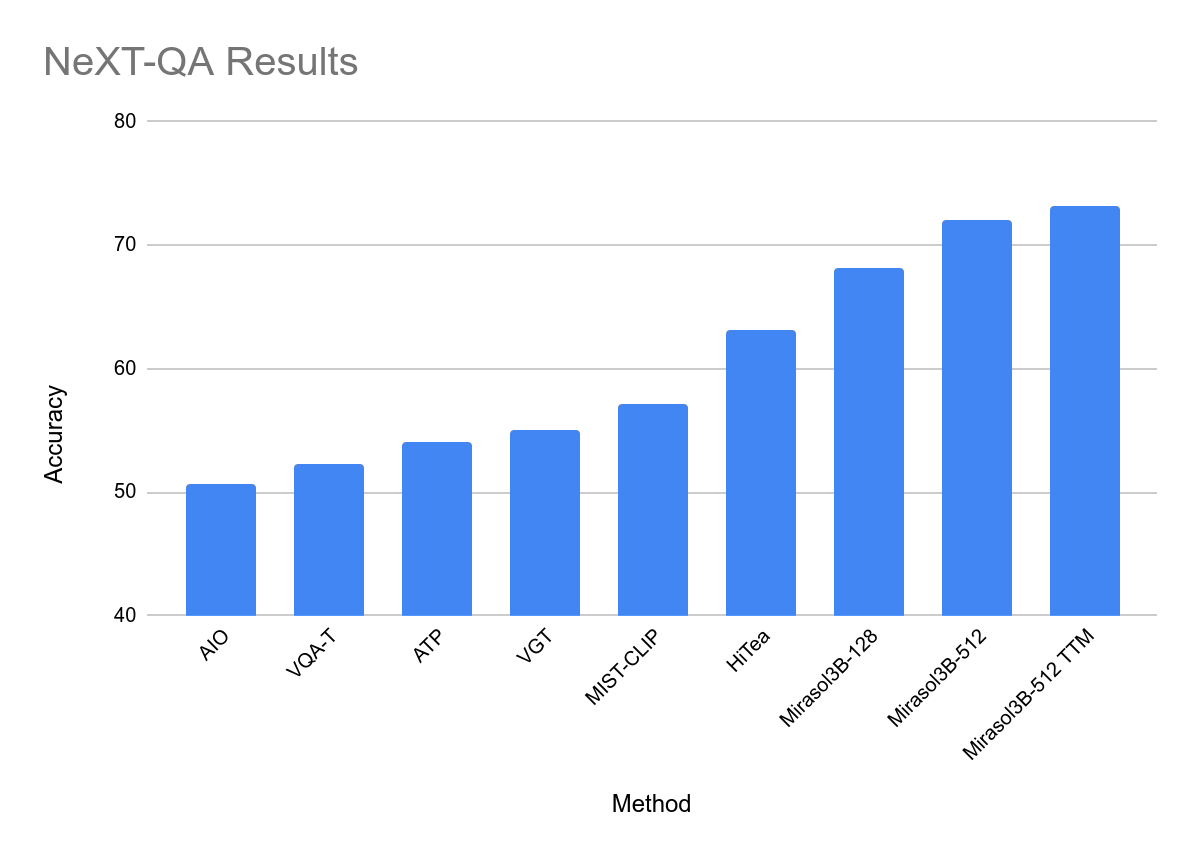
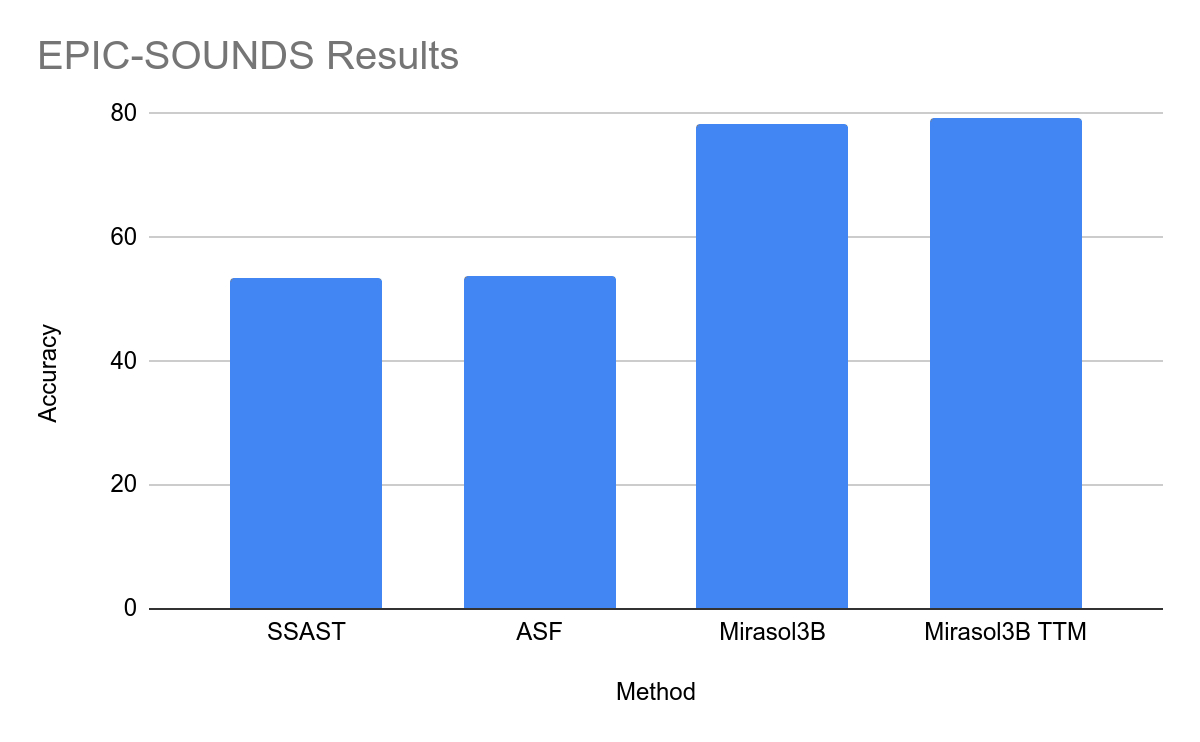
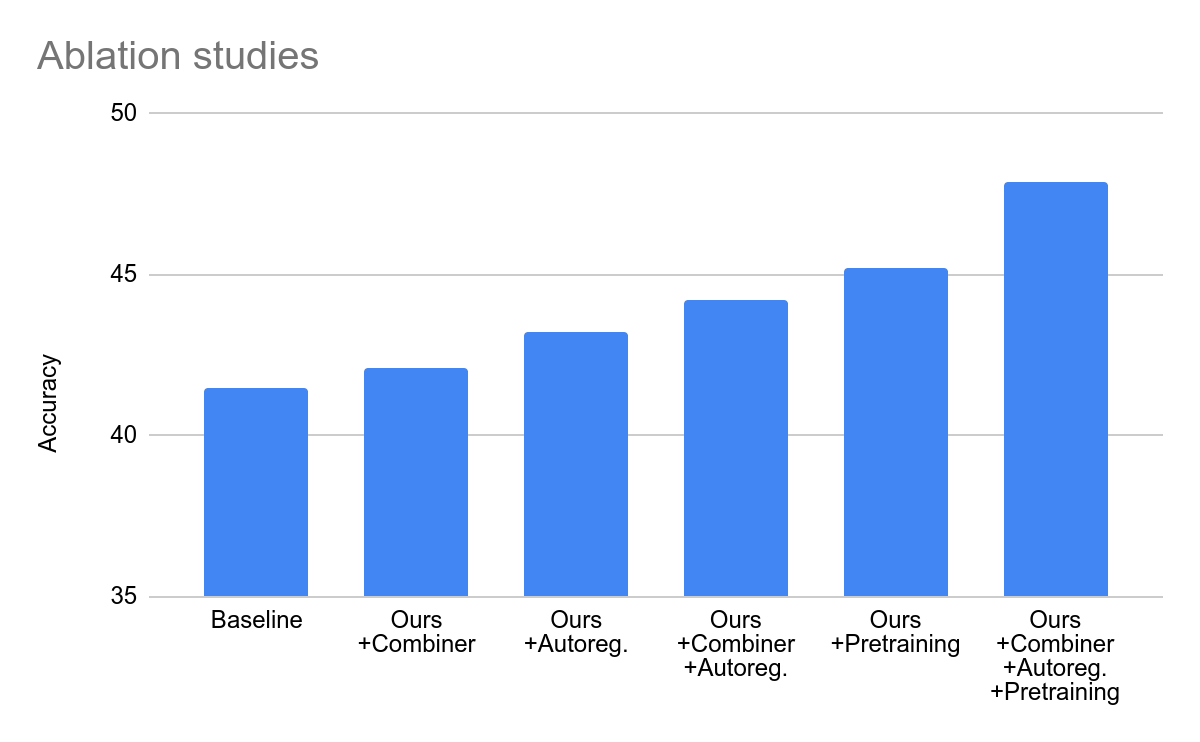
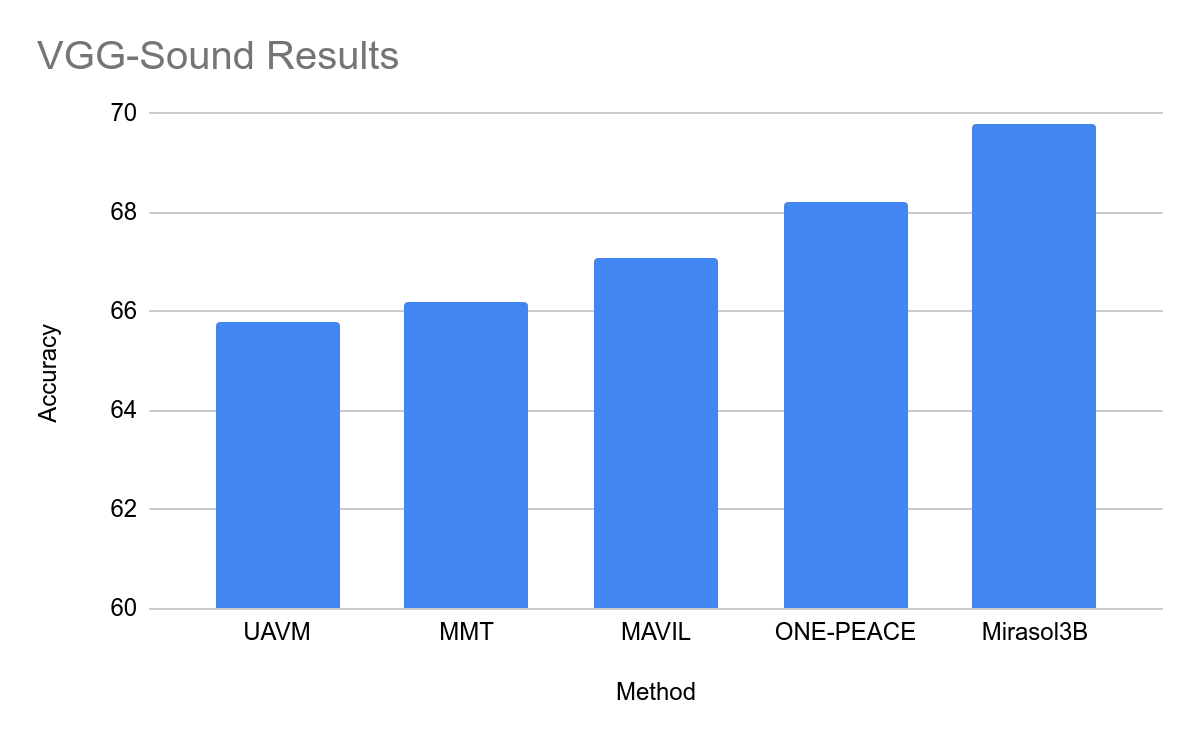
本站在此附上 Mirasol 的官方新闻稿,感兴趣的用户可以深入阅读。
以上就是谷歌推出Mirasol:30亿参数,将多模态理解扩展至长视频的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/851122.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 






















