
英伟达正式宣布将生成式AI面部动画模型Audio2Face全面开源,此次开放不仅包括核心模型代码,还提供了完整的软件开发工具包(SDK)以及整套训练架构,旨在让全球的游戏开发者与3D应用创作者都能轻松集成高保真、智能化的面部动画系统到自己的项目中。
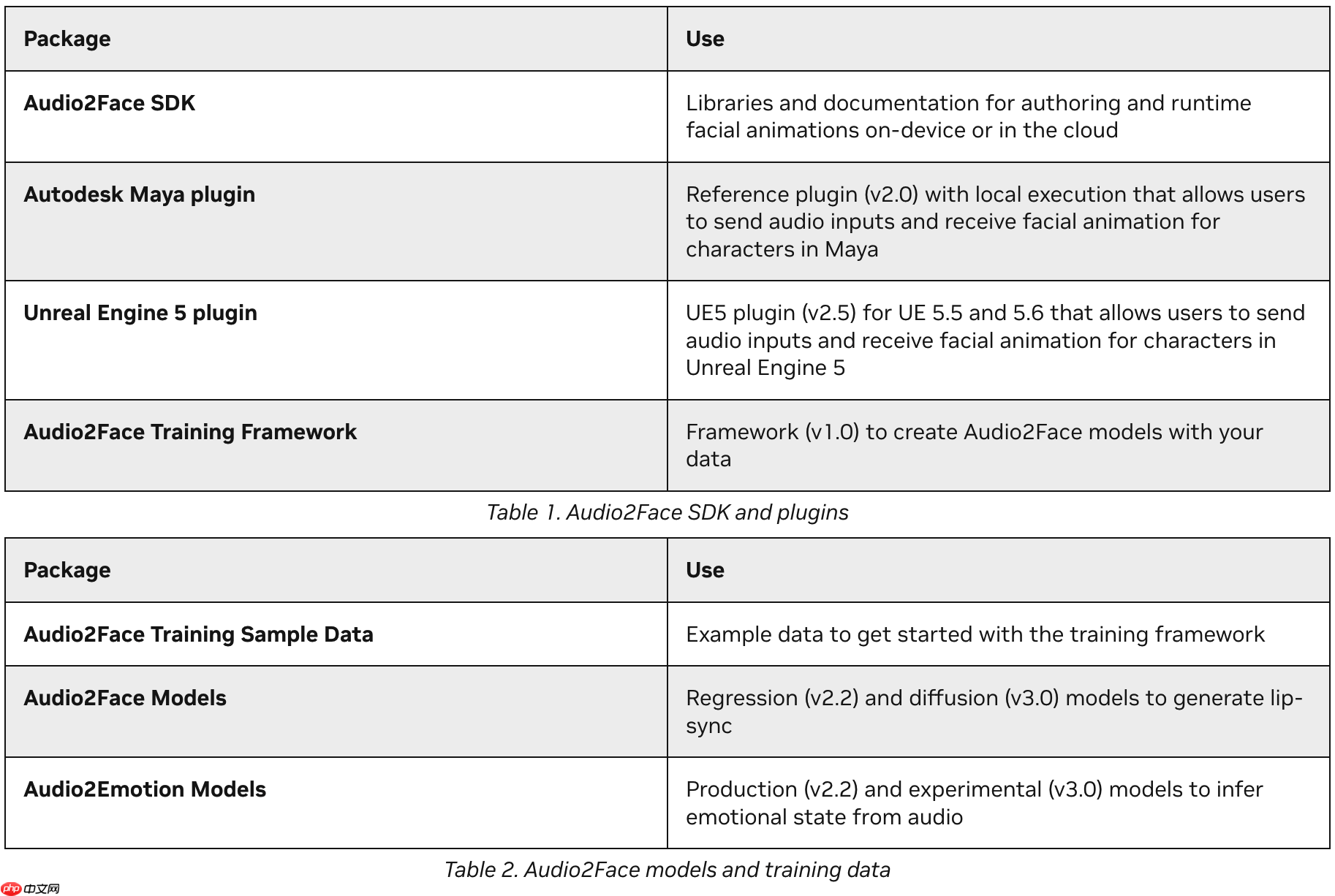
开发者可通过Audio2Face提供的训练框架,针对特定角色或应用场景对预训练模型进行微调和个性化定制,从而满足多样化的内容创作需求。
该技术基于人工智能算法,能够从输入的语音音频中提取音素、语调等声学特征,自动生成精准的面部表情动画序列,并将其映射到3D角色的面部骨骼或变形目标上。所生成的动画既可用于影视级内容的离线渲染,也可驱动实时交互场景中的虚拟形象,实现高度自然的口型同步与情绪表达。
Audio2Face支持两种主要运行模式以适应不同使用场景:一是面向预录音频的离线处理模式,适用于电影、动画等对细节表现要求较高的制作流程;二是面向实时互动的流式推断模式,可广泛应用于游戏NPC、虚拟主播、智能客服等需要低延迟响应的动态环境,确保虚拟角色在对话过程中呈现流畅且富有情感的面部动作。
以上就是英伟达开源生成式 AI 面部动画模型 Audio2Face的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/85503.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 
























