
apple mm1team 团队最新力作:87亿参数的苹果视频生成大模型stiv,支持多模态条件,性能超越pika、kling和gen-3。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

AIxiv专栏持续报道全球顶尖AI研究成果,已收录2000多篇内容,涵盖高校及企业顶级实验室。欢迎投稿或联系报道!(投稿邮箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com)
紧随OpenAI发布Sora之后,苹果发布了其多模态视频生成大模型STIV,论文已发表于arXiv(论文地址:https://www.php.cn/link/07b95840d88e2f1c033865fba89f624b),Hugging Face链接:https://www.php.cn/link/5d4d48d0359e45e4fdf997818d6407fd)。该模型拥有87亿参数,支持文本和图像条件下的视频生成。

STIV 旨在克服现有文本到视频(T2V)模型在生成连贯、真实视频方面的挑战,并高效地将图像条件融入Diffusion Transformer (DiT) 架构。该研究提供了全面的技术报告,涵盖模型架构、训练策略、数据集以及下游应用,实现了T2V和文本-图像到视频(TI2V)任务的统一处理。
主要贡献和亮点:
提出STIV模型,统一处理T2V和TI2V任务,并通过JIT-CFG显著提升生成质量;系统性研究了T2I、T2V和TI2V模型的架构设计、高效稳定的训练技术以及渐进式训练策略;模型易于训练且具有强大的适应性,可扩展至视频预测、帧插值和长视频生成等任务;实验结果在VBench基准数据集上展现了STIV的优势,包括详细的消融实验和对比分析。

STIV不仅提升了视频生成质量,也为其在更多应用场景中的推广奠定了基础。
STIV模型架构及训练策略详解
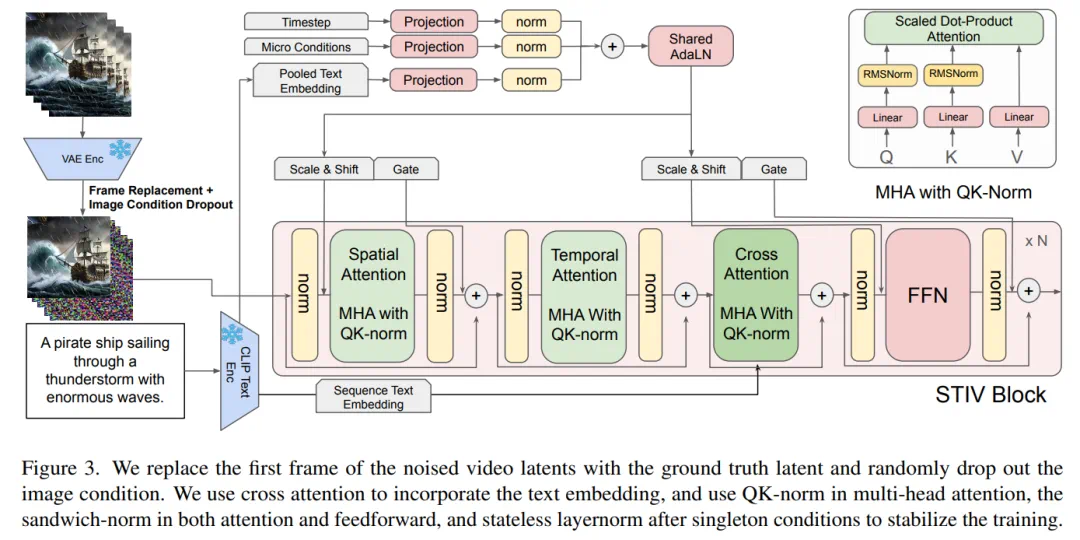
STIV基于PixArt-Alpha架构,并进行了多项优化,包括时空注意力分解、条件嵌入、旋转位置编码(RoPE)和流匹配目标函数等。 在训练方面,采用稳定训练策略(QK-Norm、sandwich-norm)和高效训练改进(MaskDiT、AdaFactor、梯度检查点),支持更大规模模型的训练。
 ONLYOFFICE
ONLYOFFICE
用ONLYOFFICE管理你的网络私人办公室
 1027 查看详情
1027 查看详情 
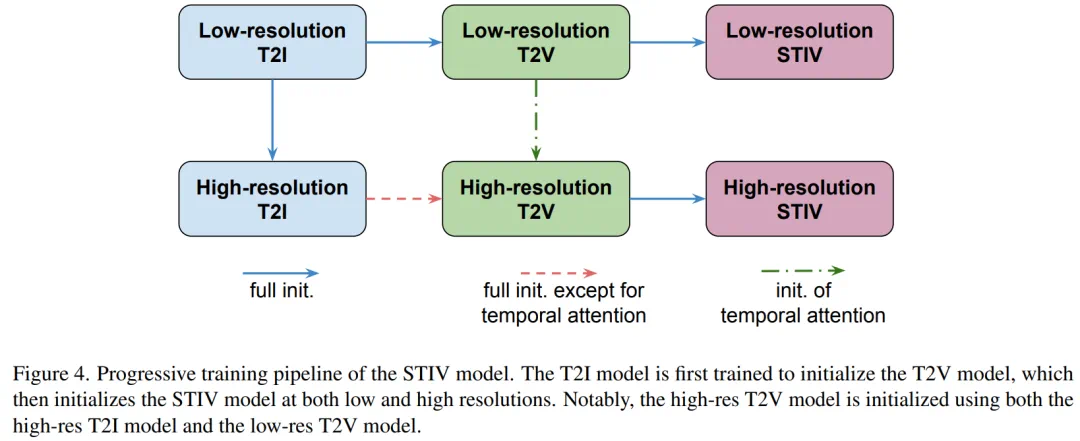
图像条件融合方法包括简单的帧替换和图像条件随机丢弃,并结合联合图像-文本无分类器引导(JIT-CFG)进一步提升生成质量。 此外,采用渐进式训练策略,先训练T2I模型,再训练T2V模型,最后训练STIV模型,提高训练效率。
数据集与评估

数据预处理包括场景分割和特征提取,以确保输入数据的质量。 视频字幕生成采用高效的视频字幕生成器和LLM分类,并通过DSG-Video模块评估字幕的丰富度和准确性。
实验结果与应用
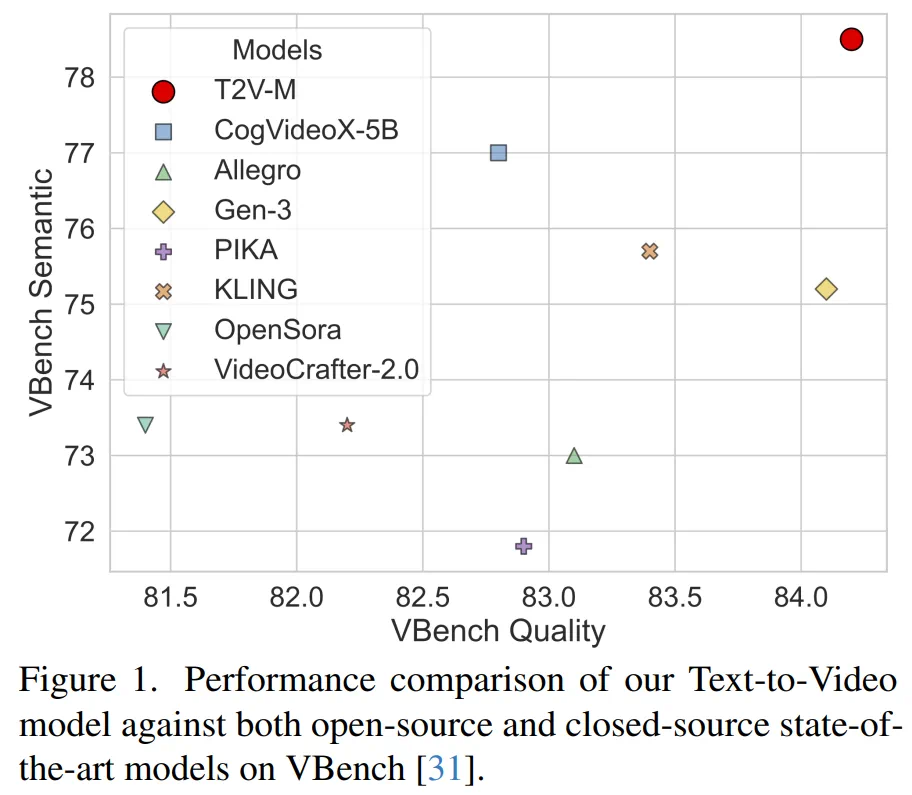
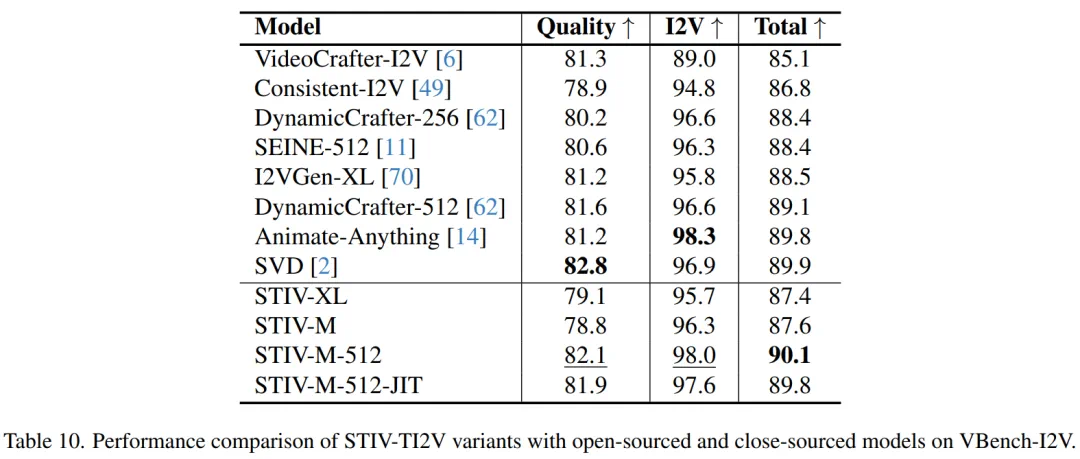
实验结果表明,STIV在VBench基准测试中超越了PIKA、KLING和Gen-3等模型。 STIV还可应用于视频预测、帧插值和长视频生成等任务。

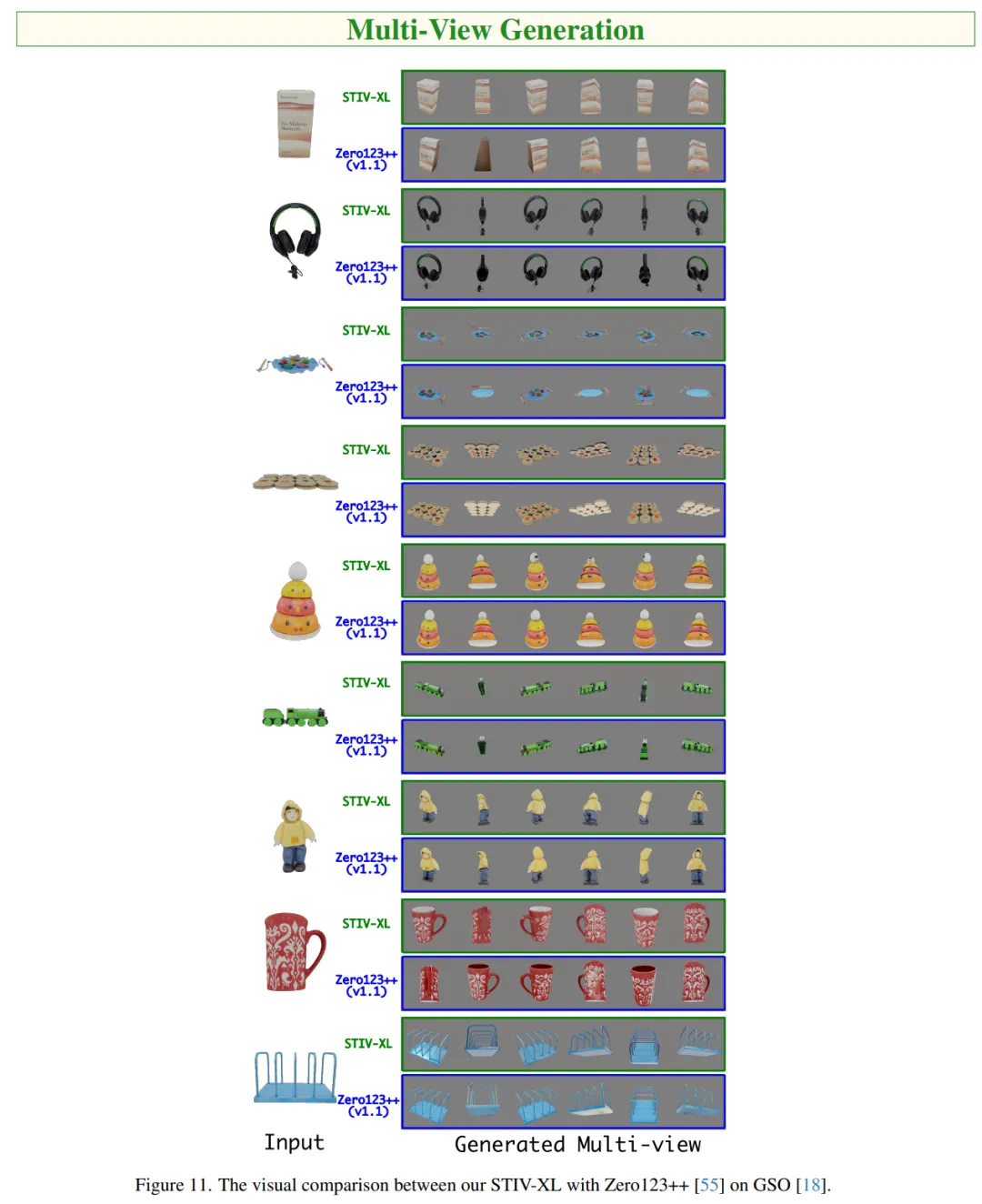

更多细节请参考原文论文。
以上就是Sora之后,苹果发布视频生成大模型STIV,87亿参数一统T2V、TI2V任务的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/867256.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 






















