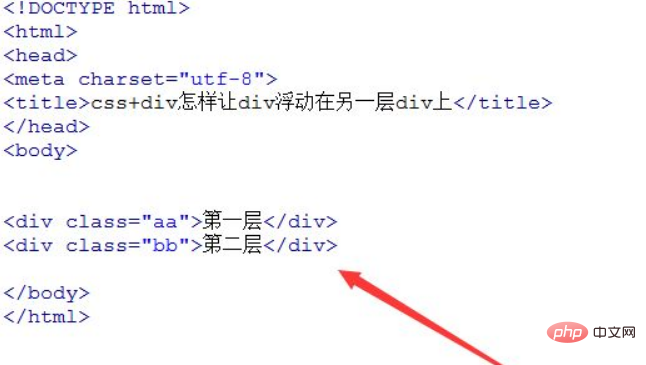
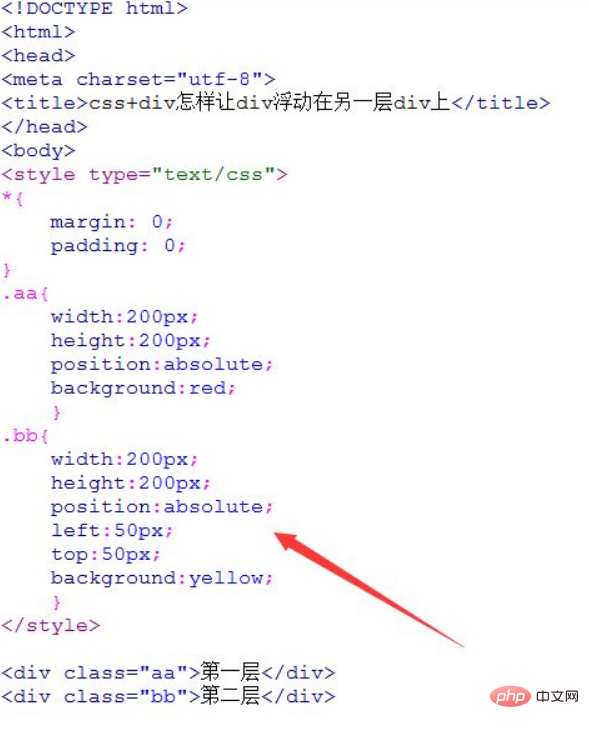
通过 PHP 获取网页源码有三种方法:file_get_contents:适用于本地或远程文件的简单读取。cURL:提供高级自定义功能,如 HTTP 请求和头信息。DOMDocument:用于结构化 HTML 解析和元素操作。

如何通过 PHP 获取网页源码
获取网页源码是 Web 开发中一项常见任务,它使我们能够分析和处理网页内容。PHP 提供了多种方法来实现这一目的。
方法 1:file_get_contents
file_get_contents 函数用于读取本地文件或远程文件的内容。要获取网页源码,可以使用以下语法:
立即学习“PHP免费学习笔记(深入)”;
$html = file_get_contents("https://example.com");其中 “https://example.com” 是目标网页的 URL。
方法 2:curl
 SDCMS-B2C商城网站管理系统
SDCMS-B2C商城网站管理系统
SDCMS-B2C商城网站管理系统是一个以php+MySQL进行开发的B2C商城网站源码。 本次更新如下: 【新增的功能】 1、模板引擎增加包含文件父路径过滤; 2、增加模板编辑保存功能过滤; 3、增加对统计代码参数的过滤 4、新增会员价设置(每个商品可以设置不同级不同价格) 5、将微信公众号授权提示页单独存放到data/wxtemp.php中,方便修改 【优化或修改】 1、修改了check_b
 13 查看详情
13 查看详情 
cURL 库允许我们以编程方式发送 HTTP 请求。它提供了更多的灵活性,使我们能够自定义头信息、POST 数据等。以下是使用 cURL 获取网页源码的示例:
$ch = curl_init("https://example.com");curl_setopt($ch, CURLOPT_RETURNTRANSFER, true);$html = curl_exec($ch);curl_close($ch);方法 3:DOMDocument
DOMDocument 类允许我们以结构化的方式解析和处理 HTML 文档。我们可以使用它来获取网页源码并访问其元素:
$doc = new DOMDocument();$doc->loadHTML(file_get_contents("https://example.com"));一旦加载完毕,我们可以使用 DOMDocument 方法来遍历元素、检索内容或修改文档。
最佳实践:
始终使用 HTTPS 协议来确保通信安全。处理远程文件时要小心,因为它们可能包含恶意代码。如果需要解析复杂 HTML 文档,请考虑使用 HTML 解析库(例如 PHP Simple HTML DOM Parser)。
以上就是php如何获得网页源码的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/901754.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫