
阿里云正式推出 qwen3-omni,宣告全球首个原生端到端全模态 ai 模型的诞生,该模型现已全面开源。qwen3-omni 能够无缝处理文本、图像、音频和视频等多种输入形式,并支持实时流式输出,无论是通过文字还是自然语音交互,均可实现快速响应与高效反馈。
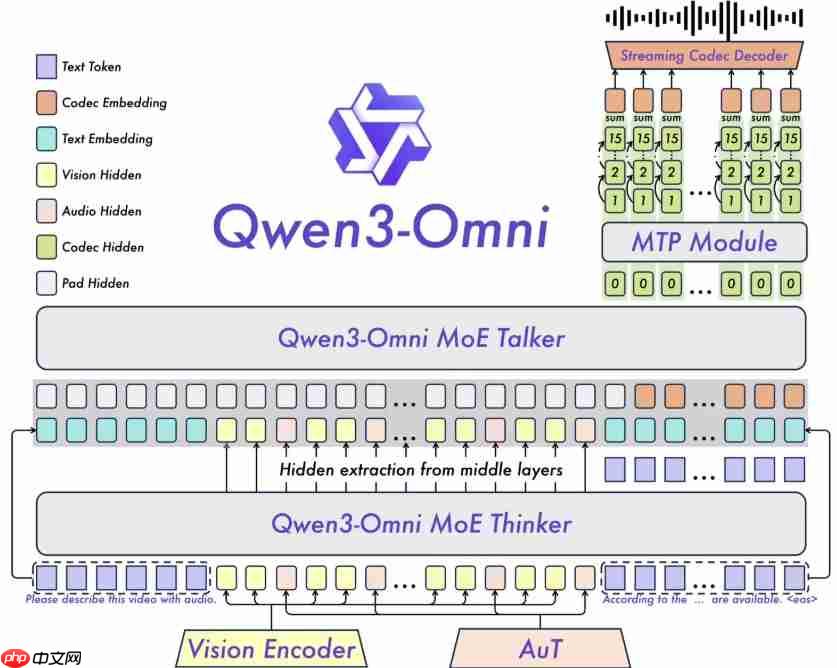
在多项跨模态任务中,Qwen3-Omni 展现出了卓越的性能表现。依托早期以文本为中心的预训练策略以及混合多模态联合训练机制,模型在保持文本与图像处理高水准的同时,在音频和视频理解方面尤为突出。根据涵盖36项音频与视频任务的基准测试结果,Qwen3-Omni 在其中22项中达到了当前最优水平,尤其在自动语音识别(ASR)和复杂音频理解任务上的表现,已可媲美行业领先的 Gemini 2.5 Pro。
该模型具备广泛的语言支持能力,覆盖119种文本语言、19种语音输入语言,以及10种语音输出语言,包括英语、中文、法语、德语等主流语种,显著增强了其在全球范围内的适用性。其核心技术架构采用 MoE(专家混合)结构,并融合 AuT 预训练方法,赋予模型强大的通用表征能力。同时,创新的多码本设计保障了音频与视频交互过程中的低延迟特性,确保自然对话流畅进行。
除 Qwen3-Omni 外,阿里云还同步发布了 Qwen3-TTS——一款先进的文本转语音模型,支持多达17种音色选择。该模型在多个权威评测中超越主流竞品,尤其在语音稳定性与音色还原度方面表现优异。
此外,全新图像编辑工具 Qwen-Image-Edit-2509 也正式亮相,专注于提升多图协同编辑能力。它不仅支持单张图像的精细化修改,还能实现多图拼接与一致性编辑,极大提升了复杂场景下的图像处理效果与操作体验。
GitHub: https://www.php.cn/link/451fbb024d0794ffcda2258170740a1e Hugging Face: https://www.php.cn/link/705e2dd2077bc06fbc5e2c754e75e500
划重点:? Qwen3-Omni 是全球首款原生端到端全模态 AI 模型,实现文本、图像、音频、视频的统一建模与处理。? 支持119种文本语言与19种语音输入语言,满足全球化多语言交互需求。?️ 新推出的 Qwen-Image-Edit-2509 支持多图像联合编辑,显著增强编辑连贯性与视觉质量。
以上就是阿里云推出全球首个全模态 AI 模型 Qwen3-Omni,实现文本、图像、音频与视频的统一处理的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/91331.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 
























