
scale ai最新发布的swe-bench pro编程能力评估结果显示,即便是当前最前沿的模型如gpt-5、claude opus4.1和gemini2.5,也未能突破25%的解决率门槛。
其中,GPT-5仅取得23.3%的解决率,Claude Opus4.1以22.7%紧随其后,而Google的Gemini2.5则表现更弱,仅有13.5%的任务被成功解决。
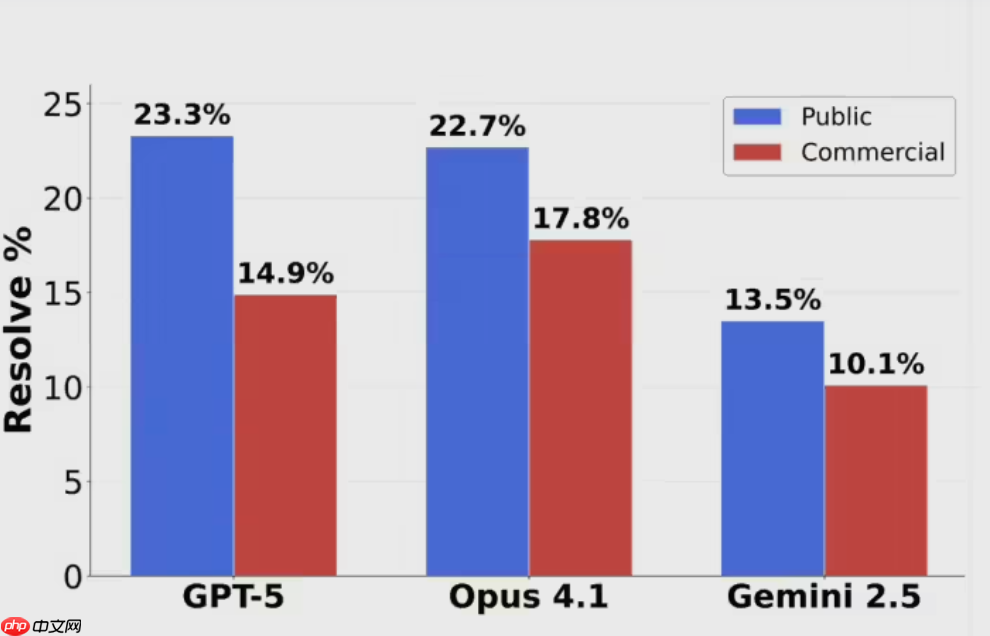
前OpenAI研究员Neil Chowdhury指出,当GPT-5决定尝试解决问题时,其实际成功率高达63%,远超Claude Opus4.1的31%。这表明尽管GPT-5在整体得分上并不突出,但在它认为可以处理的任务中,依然具备显著的技术领先优势。

立即进入“豆包AI人工智官网入口”;
立即学习“豆包AI人工智能在线问答入口”;
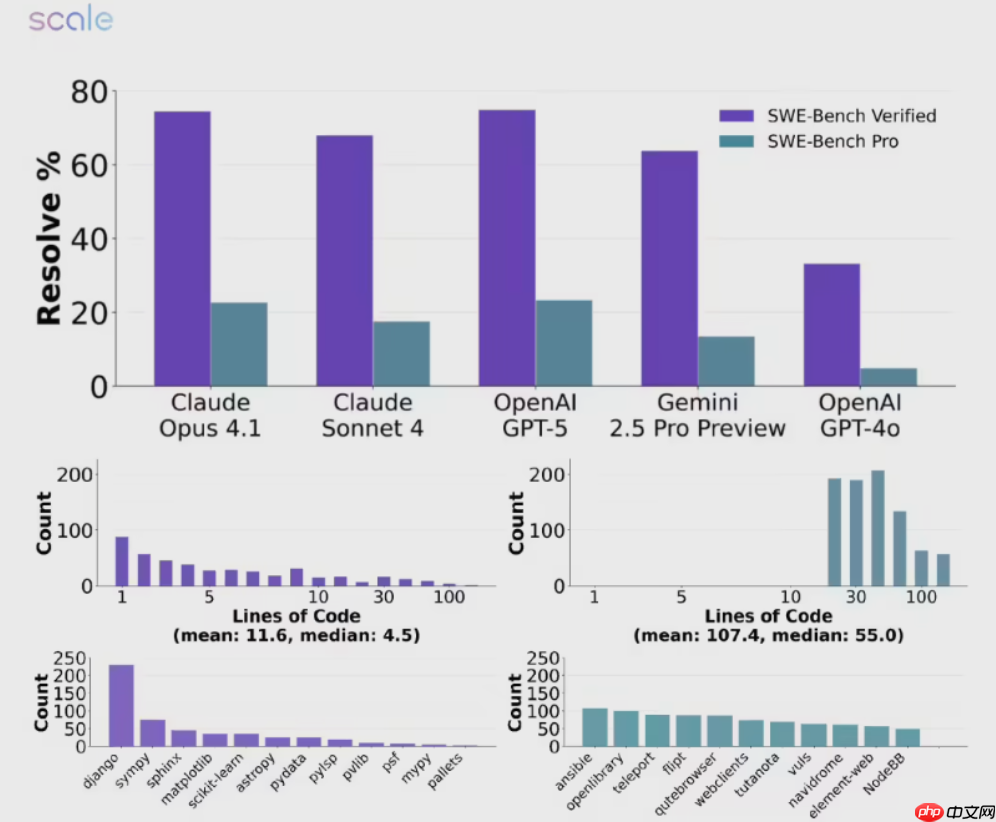
与以往常出现70%以上高分的SWE-Bench-Verified测试不同,SWE-BENCH PRO特别排除了所有可能已用于训练的数据,从根本上杜绝了数据泄露或记忆式答题的可能性。这一改进使得模型必须依赖真实的理解与推理能力来应对挑战,而非依赖训练过程中的“死记硬背”。
该评测覆盖了来自真实商业应用与开发工具的1865个实际问题,题目被划分为公共集、商业集和保留集三个层级,确保测试内容对所有模型而言都是全新的。同时,研究团队还引入人工增强机制,进一步提升了任务的真实性和复杂度。
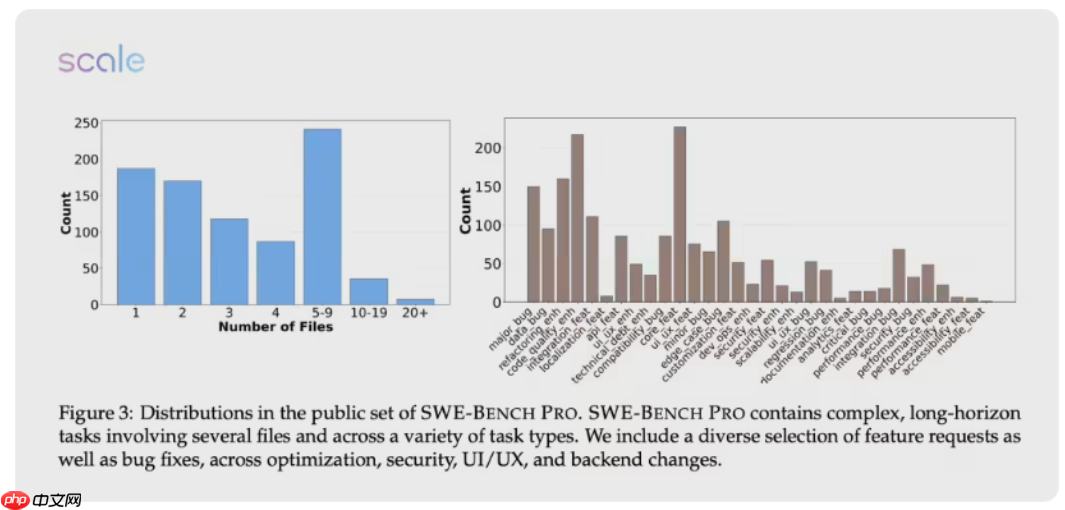
测评结果也揭示了当前AI代码生成模型的核心短板——面对真实世界中的工程问题,其能力仍十分有限。尤其是在JavaScript和TypeScript等广泛使用的语言上,各模型的表现波动剧烈且难以预测。深入分析显示,不同模型在处理相似任务时展现出截然不同的行为模式,反映出背后技术路线与训练策略的根本差异。
以上就是AI 三巨头惨遭滑铁卢:最新编程测试正确率全线跌破 25%的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/92176.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 
























