
豆包大模型1.6-vision是火山引擎推出的具备工具调用能力的视觉深度思考模型。该模型拥有强大的通用多模态理解和推理能力,支持responses api,能够自主调用工具对图像进行定位、剪裁、点选、画线、缩放、旋转等精细操作。通过将图像融入思维链并模拟人类“从全局扫描到局部聚焦”的视觉推理过程,提升了图像理解的精准度与推理可解释性。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜
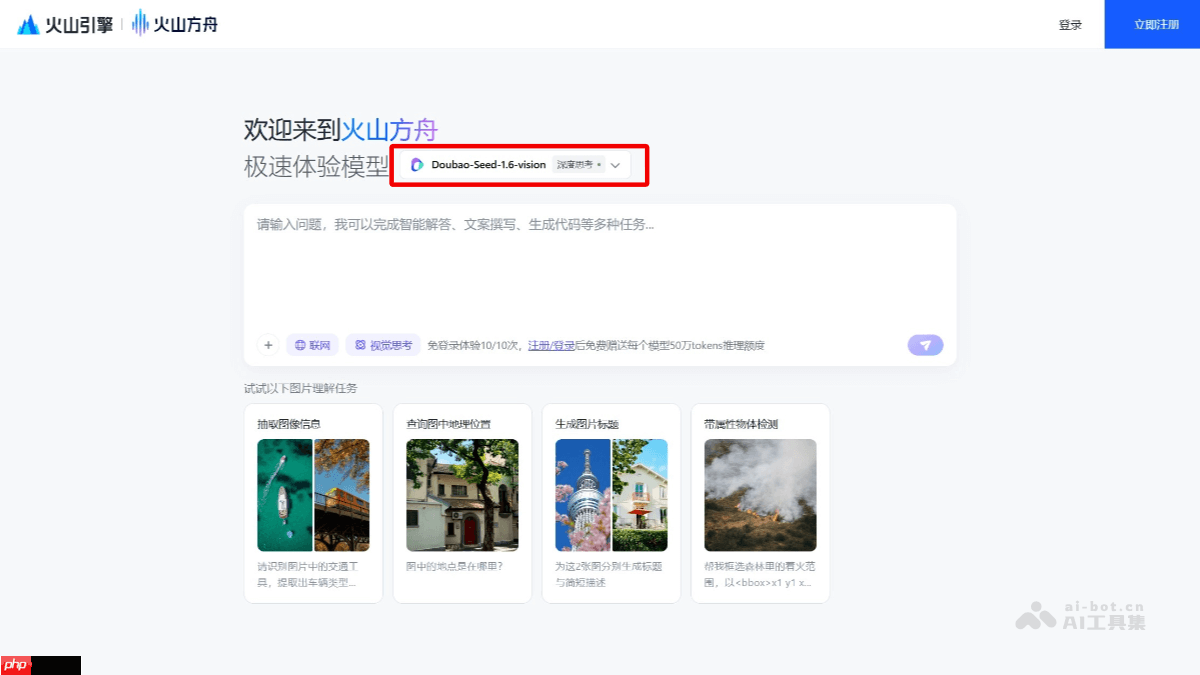
相比上一代视觉模型Doubao-1.5-thinking-vision-pro,豆包大模型1.6-vision在综合成本上降低约50%,以更低的成本实现更强的性能,显著提升性价比。该模型已在OCR信息抽取、图像审核、巡检与安防、视频与图片标注、教育解题以及AI搜索问答等多个专业场景中展现出优异表现,助力企业高效、低成本地构建和部署AI应用。
主要功能特点:
工具调用能力:可自主调用POINT(绘制点线)、GROUNDING(框选区域)、ZOOM(图像缩放)和ROTATE(图像旋转)等工具,完成复杂图像操作。多模态理解与推理:深度融合文本与视觉信息,模拟人类视觉认知路径,增强推理逻辑的透明度与准确性。Responses API 支持:开发者可通过API让模型自主决策是否调用工具,大幅减少Agent开发中的编码工作量,提升开发效率。高性价比:在性能提升的同时,整体使用成本下降近半,更适合大规模商业应用。易于集成与扩展:提供灵活的接口设计,便于企业根据具体业务需求进行定制化开发与集成。
核心技术原理:
 Grok
Grok
马斯克发起的基于大语言模型(LLM)的AI聊天机器人TruthGPT,现用名Grok
 437 查看详情
437 查看详情 
立即进入“豆包AI人工智官网入口”;
立即学习“豆包AI人工智能在线问答入口”;
基于先进的多模态架构,强化模型对图文混合输入的理解能力。引入工具调用机制,使图像处理成为模型思考过程的一部分,实现“边看边想边操作”。模拟人类视觉注意机制,先进行全局感知再聚焦关键区域,提升分析效率与准确率。结合响应式API架构,优化人机协作流程,降低开发门槛。
典型应用场景包括:
OCR信息抽取:自动识别文档、票据中的文字内容并结构化输出。图像审核:智能检测违规或敏感图像内容,提升内容安全管控效率。巡检与安防:应用于工业巡检、城市监控等场景,自动发现异常情况。视频与图片标注:为多媒体数据自动生成语义标签,服务于内容管理与推荐系统。教育解题:解析数学题、几何图示等学习材料,辅助智能辅导与批改。AI搜索问答:结合图像理解能力,提升跨模态检索与问答系统的智能化水平。
如何使用:可通过访问豆包大模型官方网站获取API接入方式、技术文档及开发指南,快速集成至各类AI应用中。
以上就是豆包大模型1.6-vision— 火山引擎推出的视觉深度思考模型的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/940157.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 
























