
接着上篇《pytorch简明教程上篇》,继续学习多层感知机,卷积神经网络和lstmnet。
1、多层感知机
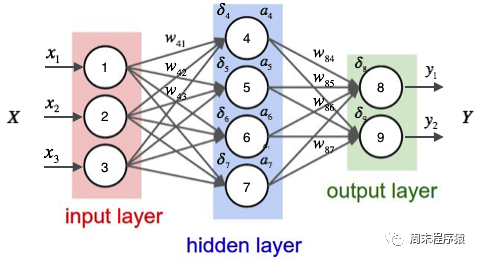
多层感知机是一种简单的神经网络,也是深度学习的重要基础。它通过在网络中添加一个或多个隐藏层来克服线性模型的限制。具体的图示如下:
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜
import numpy as npimport torchfrom torch.autograd import Variablefrom torch import optimfrom data_util import load_mnistdef build_model(input_dim, output_dim):return torch.nn.Sequential(torch.nn.Linear(input_dim, 512, bias=False),torch.nn.ReLU(),torch.nn.Dropout(0.2),torch.nn.Linear(512, 512, bias=False),torch.nn.ReLU(),torch.nn.Dropout(0.2),torch.nn.Linear(512, output_dim, bias=False),)def train(model, loss, optimizer, x_val, y_val):model.train()optimizer.zero_grad()fx = model.forward(x_val)output = loss.forward(fx, y_val)output.backward()optimizer.step()return output.item()def predict(model, x_val):model.eval()output = model.forward(x_val)return output.data.numpy().argmax(axis=1)def main():torch.manual_seed(42)trX, teX, trY, teY = load_mnist(notallow=False)trX = torch.from_numpy(trX).float()teX = torch.from_numpy(teX).float()trY = torch.tensor(trY)n_examples, n_features = trX.size()n_classes = 10model = build_model(n_features, n_classes)loss = torch.nn.CrossEntropyLoss(reductinotallow='mean')optimizer = optim.Adam(model.parameters())batch_size = 100for i in range(100):cost = 0.num_batches = n_examples // batch_sizefor k in range(num_batches):start, end = k * batch_size, (k + 1) * batch_sizecost += train(model, loss, optimizer,trX[start:end], trY[start:end])predY = predict(model, teX)print("Epoch %d, cost = %f, acc = %.2f%%"% (i + 1, cost / num_batches, 100. * np.mean(predY == teY)))if __name__ == "__main__":main()
(1)以上代码和单层神经网络的代码类似,区别是build_model构建一个包含三个线性层和两个ReLU激活函数的神经网络模型:
向模型中添加第一个线性层,该层的输入特征数量为input_dim,输出特征数量为512;接着添加一个ReLU激活函数和一个Dropout层,用于增强模型的非线性能力和防止过拟合;向模型中添加第二个线性层,该层的输入特征数量为512,输出特征数量为512;接着添加一个ReLU激活函数和一个Dropout层;向模型中添加第三个线性层,该层的输入特征数量为512,输出特征数量为output_dim,即模型的输出类别数量;
(2)什么是ReLU激活函数?ReLU(Rectified Linear Unit,修正线性单元)激活函数是深度学习和神经网络中常用的一种激活函数,ReLU函数的数学表达式为:f(x) = max(0, x),其中x是输入值。ReLU函数的特点是当输入值小于等于0时,输出为0;当输入值大于0时,输出等于输入值。简单来说,ReLU函数就是将负数部分抑制为0,正数部分保持不变。ReLU激活函数在神经网络中的作用是引入非线性因素,使得神经网络能够拟合复杂的非线性关系,同时,ReLU函数相对于其他激活函数(如Sigmoid或Tanh)具有计算速度快、收敛速度快等优点;
(3)什么是Dropout层?Dropout层是一种在神经网络中用于防止过拟合的技术。在训练过程中,Dropout层会随机地将一部分神经元的输出置为0,即”丢弃”这些神经元,这样做的目的是为了减少神经元之间的相互依赖,从而提高网络的泛化能力;
(4)print(“Epoch %d, cost = %f, acc = %.2f%%” % (i + 1, cost / num_batches, 100. * np.mean(predY == teY)))最后打印当前训练的轮次,损失值和acc,上述的代码输出如下:
...Epoch 91, cost = 0.011129, acc = 98.45%Epoch 92, cost = 0.007644, acc = 98.58%Epoch 93, cost = 0.011872, acc = 98.61%Epoch 94, cost = 0.010658, acc = 98.58%Epoch 95, cost = 0.007274, acc = 98.54%Epoch 96, cost = 0.008183, acc = 98.43%Epoch 97, cost = 0.009999, acc = 98.33%Epoch 98, cost = 0.011613, acc = 98.36%Epoch 99, cost = 0.007391, acc = 98.51%Epoch 100, cost = 0.011122, acc = 98.59%
可以看出最后相同的数据分类,准确率比单层神经网络要高(98.59% > 97.68%)。
2、卷积神经网络
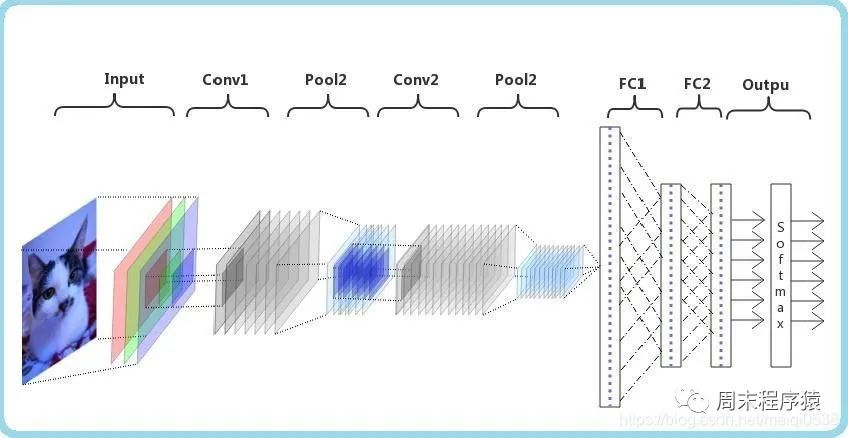
卷积神经网络(CNN)是一种深度学习算法。当输入一个矩阵时,CNN可以对其中的重要和不重要部分进行区分(分配权重)。相较于其他分类任务,CNN对数据预处理的要求并不高,只要经过充分的训练,就能够学习到矩阵的特征。下图展示了该过程:
import numpy as npimport torchfrom torch.autograd import Variablefrom torch import optimfrom data_util import load_mnistclass ConvNet(torch.nn.Module):def __init__(self, output_dim):super(ConvNet, self).__init__()self.conv = torch.nn.Sequential()self.conv.add_module("conv_1", torch.nn.Conv2d(1, 10, kernel_size=5))self.conv.add_module("maxpool_1", torch.nn.MaxPool2d(kernel_size=2))self.conv.add_module("relu_1", torch.nn.ReLU())self.conv.add_module("conv_2", torch.nn.Conv2d(10, 20, kernel_size=5))self.conv.add_module("dropout_2", torch.nn.Dropout())self.conv.add_module("maxpool_2", torch.nn.MaxPool2d(kernel_size=2))self.conv.add_module("relu_2", torch.nn.ReLU())self.fc = torch.nn.Sequential()self.fc.add_module("fc1", torch.nn.Linear(320, 50))self.fc.add_module("relu_3", torch.nn.ReLU())self.fc.add_module("dropout_3", torch.nn.Dropout())self.fc.add_module("fc2", torch.nn.Linear(50, output_dim))def forward(self, x):x = self.conv.forward(x)x = x.view(-1, 320)return self.fc.forward(x)def train(model, loss, optimizer, x_val, y_val):model.train()optimizer.zero_grad()fx = model.forward(x_val)output = loss.forward(fx, y_val)output.backward()optimizer.step()return output.item()def predict(model, x_val):model.eval()output = model.forward(x_val)return output.data.numpy().argmax(axis=1)def main():torch.manual_seed(42)trX, teX, trY, teY = load_mnist(notallow=False)trX = trX.reshape(-1, 1, 28, 28)teX = teX.reshape(-1, 1, 28, 28)trX = torch.from_numpy(trX).float()teX = torch.from_numpy(teX).float()trY = torch.tensor(trY)n_examples = len(trX)n_classes = 10model = ConvNet(output_dim=n_classes)loss = torch.nn.CrossEntropyLoss(reductinotallow='mean')optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.9)batch_size = 100for i in range(100):cost = 0.num_batches = n_examples // batch_sizefor k in range(num_batches):start, end = k * batch_size, (k + 1) * batch_sizecost += train(model, loss, optimizer,trX[start:end], trY[start:end])predY = predict(model, teX)print("Epoch %d, cost = %f, acc = %.2f%%"% (i + 1, cost / num_batches, 100. * np.mean(predY == teY)))if __name__ == "__main__":main()
(1)以上代码定义了一个名为ConvNet的类,它继承自torch.nn.Module类,表示一个卷积神经网络,在__init__方法中定义了两个子模块conv和fc,分别表示卷积层和全连接层。在conv子模块中,我们定义了两个卷积层(torch.nn.Conv2d)、两个最大池化层(torch.nn.MaxPool2d)、两个ReLU激活函数(torch.nn.ReLU)和一个Dropout层(torch.nn.Dropout)。在fc子模块中,定义了两个线性层(torch.nn.Linear)、一个ReLU激活函数和一个Dropout层;
池化层在CNN中扮演着重要的角色,其主要目的有以下几点:
 python基础教程至60课_python入门基础资料 word版
python基础教程至60课_python入门基础资料 word版
python基础教程至60课,这篇教程开始就为大家介绍了,为什么学习python,python有什么优点等,确实让你想快点学习python。为什么用Python作为编程入门语言? 原因很简单。 每种语言都会有它的支持者和反对者。去Google一下“why python”,你会得到很多结果,诸如应用范围广泛、开源、社区活跃、丰富的库、跨平台等等等等,也可能找到不少对它的批评,格式死板、效率低、国内用的人很少之类。不过这些优缺点的权衡都是程序员们的烦恼。作为一个想要学点
 1 查看详情
1 查看详情  降低维度:池化层通过对输入特征图(Feature maps)进行局部区域的下采样操作,降低了特征图的尺寸。这样可以减少后续层中的参数数量,降低计算复杂度,加速训练过程;平移不变性:池化层可以提高网络对输入图像的平移不变性。当图像中的某个特征发生小幅度平移时,池化层的输出仍然具有相似的特征表示。这有助于提高模型的泛化能力,使其能够在不同位置和尺度下识别相同的特征;防止过拟合:通过减少特征图的尺寸,池化层可以降低模型的参数数量,从而降低过拟合的风险;增强特征表达:池化操作可以聚合局部区域内的特征,从而强化和突出更重要的特征信息。常见的池化操作有最大池化(Max Pooling)和平均池化(Average Pooling),分别表示在局部区域内取最大值或平均值作为输出;
降低维度:池化层通过对输入特征图(Feature maps)进行局部区域的下采样操作,降低了特征图的尺寸。这样可以减少后续层中的参数数量,降低计算复杂度,加速训练过程;平移不变性:池化层可以提高网络对输入图像的平移不变性。当图像中的某个特征发生小幅度平移时,池化层的输出仍然具有相似的特征表示。这有助于提高模型的泛化能力,使其能够在不同位置和尺度下识别相同的特征;防止过拟合:通过减少特征图的尺寸,池化层可以降低模型的参数数量,从而降低过拟合的风险;增强特征表达:池化操作可以聚合局部区域内的特征,从而强化和突出更重要的特征信息。常见的池化操作有最大池化(Max Pooling)和平均池化(Average Pooling),分别表示在局部区域内取最大值或平均值作为输出;
(3)print(“Epoch %d, cost = %f, acc = %.2f%%” % (i + 1, cost / num_batches, 100. * np.mean(predY == teY)))最后打印当前训练的轮次,损失值和acc,上述的代码输出如下:
...Epoch 91, cost = 0.047302, acc = 99.22%Epoch 92, cost = 0.049026, acc = 99.22%Epoch 93, cost = 0.048953, acc = 99.13%Epoch 94, cost = 0.045235, acc = 99.12%Epoch 95, cost = 0.045136, acc = 99.14%Epoch 96, cost = 0.048240, acc = 99.02%Epoch 97, cost = 0.049063, acc = 99.21%Epoch 98, cost = 0.045373, acc = 99.23%Epoch 99, cost = 0.046127, acc = 99.12%Epoch 100, cost = 0.046864, acc = 99.10%
可以看出最后相同的数据分类,准确率比多层感知机要高(99.10% > 98.59%)。
3、LSTMNet
LSTMNet是使用长短时记忆网络(Long Short-Term Memory, LSTM)构建的神经网络,核心思想是引入了一个名为”记忆单元”的结构,该结构可以在一定程度上保留长期依赖信息,LSTM中的每个单元包括一个输入门(input gate)、一个遗忘门(forget gate)和一个输出门(output gate),这些门的作用是控制信息在记忆单元中的流动,以便网络可以学习何时存储、更新或输出有用的信息。
import numpy as npimport torchfrom torch import optim, nnfrom data_util import load_mnistclass LSTMNet(torch.nn.Module):def __init__(self, input_dim, hidden_dim, output_dim):super(LSTMNet, self).__init__()self.hidden_dim = hidden_dimself.lstm = nn.LSTM(input_dim, hidden_dim)self.linear = nn.Linear(hidden_dim, output_dim, bias=False)def forward(self, x):batch_size = x.size()[1]h0 = torch.zeros([1, batch_size, self.hidden_dim])c0 = torch.zeros([1, batch_size, self.hidden_dim])fx, _ = self.lstm.forward(x, (h0, c0))return self.linear.forward(fx[-1])def train(model, loss, optimizer, x_val, y_val):model.train()optimizer.zero_grad()fx = model.forward(x_val)output = loss.forward(fx, y_val)output.backward()optimizer.step()return output.item()def predict(model, x_val):model.eval()output = model.forward(x_val)return output.data.numpy().argmax(axis=1)def main():torch.manual_seed(42)trX, teX, trY, teY = load_mnist(notallow=False)train_size = len(trY)n_classes = 10seq_length = 28input_dim = 28hidden_dim = 128batch_size = 100epochs = 100trX = trX.reshape(-1, seq_length, input_dim)teX = teX.reshape(-1, seq_length, input_dim)trX = np.swapaxes(trX, 0, 1)teX = np.swapaxes(teX, 0, 1)trX = torch.from_numpy(trX).float()teX = torch.from_numpy(teX).float()trY = torch.tensor(trY)model = LSTMNet(input_dim, hidden_dim, n_classes)loss = torch.nn.CrossEntropyLoss(reductinotallow='mean')optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.9)for i in range(epochs):cost = 0.num_batches = train_size // batch_sizefor k in range(num_batches):start, end = k * batch_size, (k + 1) * batch_sizecost += train(model, loss, optimizer,trX[:, start:end, :], trY[start:end])predY = predict(model, teX)print("Epoch %d, cost = %f, acc = %.2f%%" %(i + 1, cost / num_batches, 100. * np.mean(predY == teY)))if __name__ == "__main__":main()
(1)以上这段代码通用的部分就不解释了,具体说LSTMNet类:
self.lstm = nn.LSTM(input_dim, hidden_dim)创建一个LSTM层,输入维度为input_dim,隐藏层维度为hidden_dim;self.linear = nn.Linear(hidden_dim, output_dim, bias=False)创建一个线性层(全连接层),输入维度为hidden_dim,输出维度为output_dim,并设置不使用偏置项(bias);h0 = torch.zeros([1, batch_size, self.hidden_dim])初始化LSTM层的隐藏状态h0,全零张量,形状为[1, batch_size, hidden_dim];c0 = torch.zeros([1, batch_size, self.hidden_dim])初始化LSTM层的细胞状态c0,全零张量,形状为[1, batch_size, hidden_dim];fx, _ = self.lstm.forward(x, (h0, c0))将输入数据x以及初始隐藏状态h0和细胞状态c0传入LSTM层,得到LSTM层的输出fx;return self.linear.forward(fx[-1])将LSTM层的输出传入线性层进行计算,得到最终输出。这里fx[-1]表示取LSTM层输出的最后一个时间步的数据;
(2)print(“第%d轮,损失值=%f,准确率=%.2f%%” % (i + 1, cost / num_batches, 100. * np.mean(predY == teY)))。打印出当前训练轮次的信息,其中包括损失值和准确率,以上代码的输出结果如下:
Epoch 91, cost = 0.000468, acc = 98.57%Epoch 92, cost = 0.000452, acc = 98.57%Epoch 93, cost = 0.000437, acc = 98.58%Epoch 94, cost = 0.000422, acc = 98.57%Epoch 95, cost = 0.000409, acc = 98.58%Epoch 96, cost = 0.000396, acc = 98.58%Epoch 97, cost = 0.000384, acc = 98.57%Epoch 98, cost = 0.000372, acc = 98.56%Epoch 99, cost = 0.000360, acc = 98.55%Epoch 100, cost = 0.000349, acc = 98.55%
4、辅助代码
两篇文章的from data_util import load_mnist的data_util.py代码如下:
import gzipimport osimport urllib.request as requestfrom os import pathimport numpy as npDATASET_DIR = 'datasets/'MNIST_FILES = ["train-images-idx3-ubyte.gz", "train-labels-idx1-ubyte.gz", "t10k-images-idx3-ubyte.gz", "t10k-labels-idx1-ubyte.gz"]def download_file(url, local_path): dir_path = path.dirname(local_path) if not path.exists(dir_path): print("创建目录'%s' ..." % dir_path) os.makedirs(dir_path) print("从'%s'下载中 ..." % url) request.urlretrieve(url, local_path)def download_mnist(local_path): url_root = "http://yann.lecun.com/exdb/mnist/" for f_name in MNIST_FILES: f_path = os.path.join(local_path, f_name) if not path.exists(f_path): download_file(url_root + f_name, f_path)def one_hot(x, n): if type(x) == list: x = np.array(x) x = x.flatten() o_h = np.zeros((len(x), n)) o_h[np.arange(len(x)), x] = 1 return o_hdef load_mnist(ntrain=60000, ntest=10000, notallow=True): data_dir = os.path.join(DATASET_DIR, 'mnist/') if not path.exists(data_dir): download_mnist(data_dir) else: # 检查所有文件 checks = [path.exists(os.path.join(data_dir, f)) for f in MNIST_FILES] if not np.all(checks): download_mnist(data_dir) with gzip.open(os.path.join(data_dir, 'train-images-idx3-ubyte.gz')) as fd: buf = fd.read() loaded = np.frombuffer(buf, dtype=np.uint8) trX = loaded[16:].reshape((60000, 28 * 28)).astype(float) with gzip.open(os.path.join(data_dir, 'train-labels-idx1-ubyte.gz')) as fd: buf = fd.read() loaded = np.frombuffer(buf, dtype=np.uint8) trY = loaded[8:].reshape((60000)) with gzip.open(os.path.join(data_dir, 't10k-images-idx3-ubyte.gz')) as fd: buf = fd.read() loaded = np.frombuffer(buf, dtype=np.uint8) teX = loaded[16:].reshape((10000, 28 * 28)).astype(float) with gzip.open(os.path.join(data_dir, 't10k-labels-idx1-ubyte.gz')) as fd: buf = fd.read() loaded = np.frombuffer(buf, dtype=np.uint8) teY = loaded[8:].reshape((10000)) trX /= 255. teX /= 255. trX = trX[:ntrain] trY = trY[:ntrain] teX = teX[:ntest] teY = teY[:ntest] if onehot: trY = one_hot(trY, 10) teY = one_hot(teY, 10) else: trY = np.asarray(trY) teY = np.asarray(teY) return trX, teX, trY, teY
以上就是机器学习|PyTorch简明教程下篇的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/956088.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 






















