
1、 想要进行词频分析,可以借助文本处理%ignore_a_1%textmechanic。由于百度限制,无法提供具体链接。只需将感兴趣的英文文章、论文或教材内容复制粘贴到该工具中,系统便会自动统计词汇出现频率,帮助掌握文本中词语的使用情况与分布规律。
2、 如何对英文文本进行词频统计并导出结果?


3、 制作词汇表
4、 将词频分析结果复制到新建的TXT文档中,清除顶部无关数字信息,并在保存时选择ASNI编码格式。
5、 因后续导入功能仅支持ASNI编码,因此必须采用此格式保存文件。
6、 如何将有道词典的生词本导入知米背单词
7、 导入自定义词表
 Shrink.media
Shrink.media
Shrink.media是当今市场上最快、最直观、最智能的图像文件缩减工具
 123 查看详情
123 查看详情 
8、 访问知米官网,点击页面右上角“我的知米”完成登录操作。
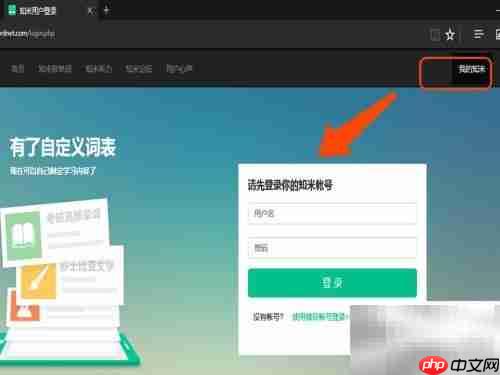
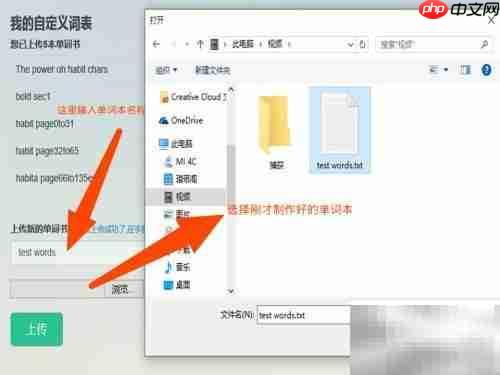
9、 登录后查看最近上传的单词本列表,找到之前准备好的词表文件,执行导入步骤。
10、 建议使用英文为词本命名,若使用中文名称,可能导致手机端无法正常显示内容。
11、 成功导入后,打开知米背单词手机应用,进入学习挑战计划,同步词本数据,即可看到已上传的内容。

以上就是知米词表导入技巧的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/958730.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 


























