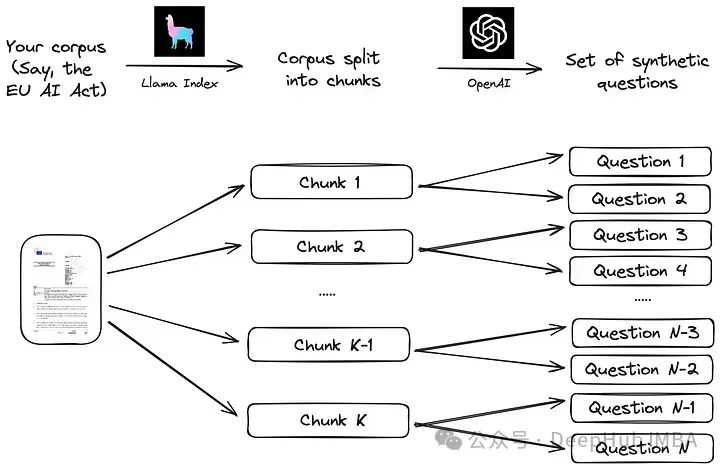
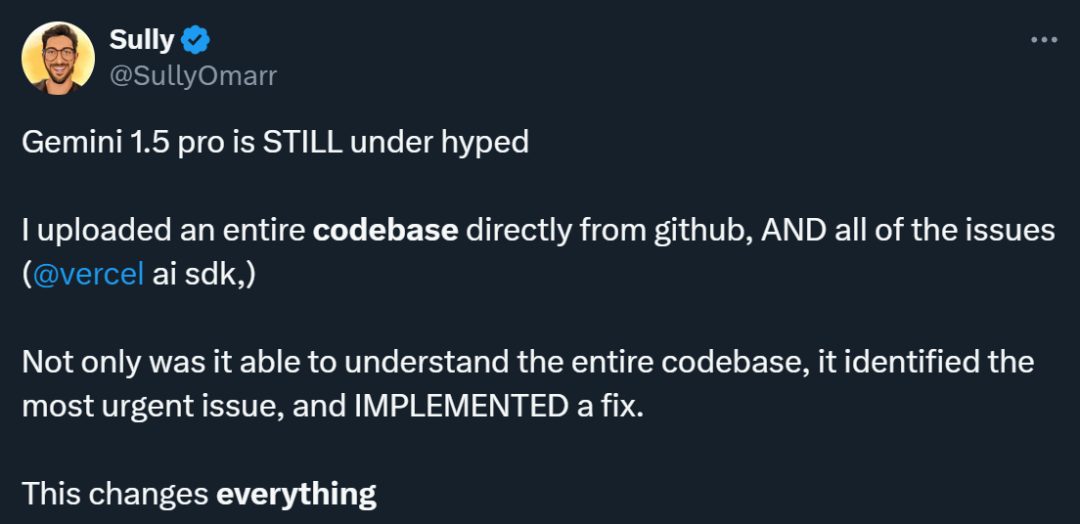
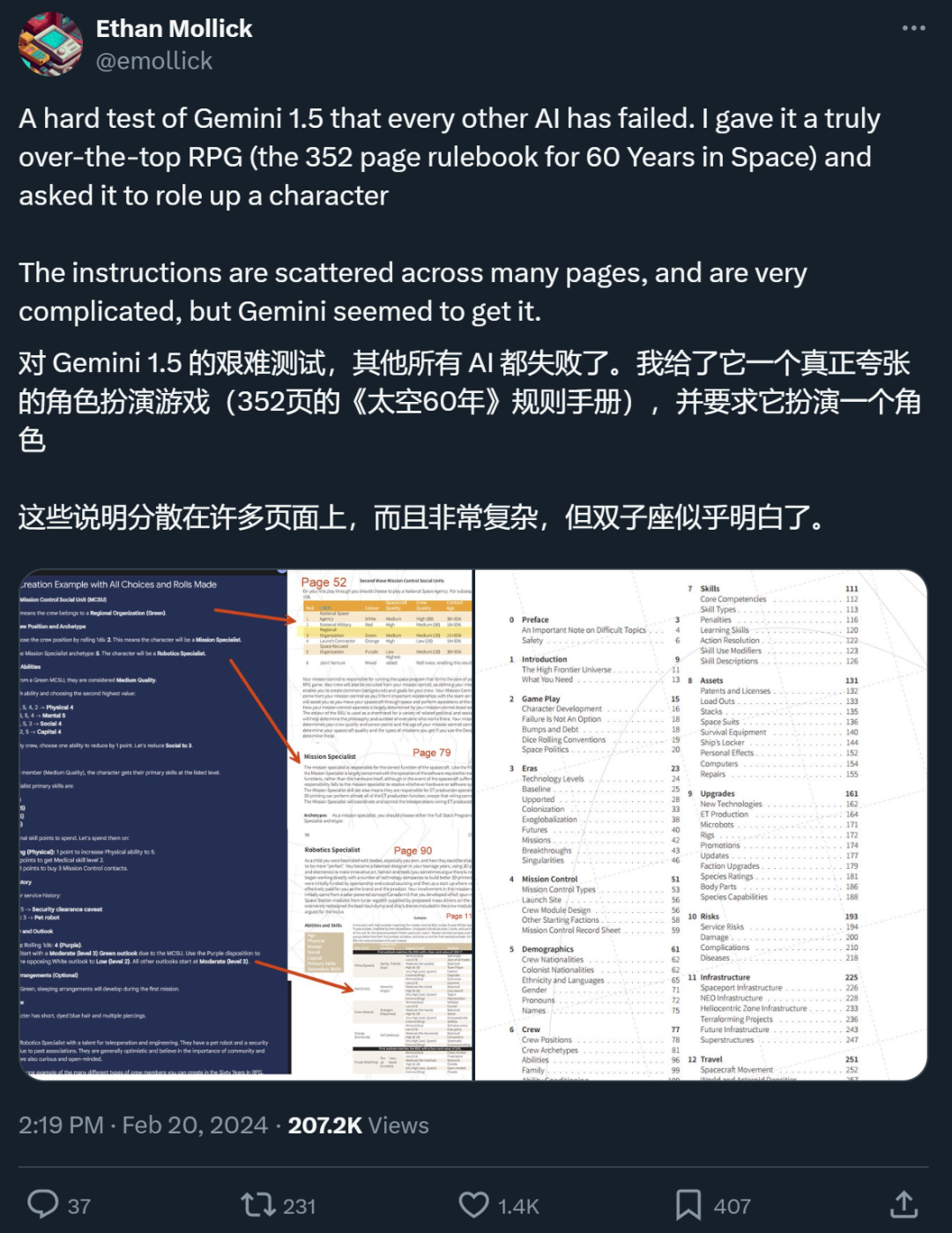
9 月 12 日,淘天集团联合爱橙科技正式对外开源大模型训练框架 ——megatron-llama,旨在让技术开发者们能够更方便的提升大语言模型训练性能,降低训练成本,并且保持和 llama 社区的兼容性。测试显示,在 32 卡训练上,相比 huggingface 上直接获得的代码版本,megatron-llama 能够取得 176% 的加速;在大规模的训练上,megatron-llama 相比较 32 卡拥有几乎线性的扩展性,而且对网络不稳定表现出高容忍度。目前 megatron-llama 已在开源社区上线。
开源地址:https://github.com/alibaba/megatron-llama
 TextCortex
TextCortex
AI写作能手,在几秒钟内创建内容。
 62 查看详情
62 查看详情 
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜
Megatron-LLaMA 的反向流程优化 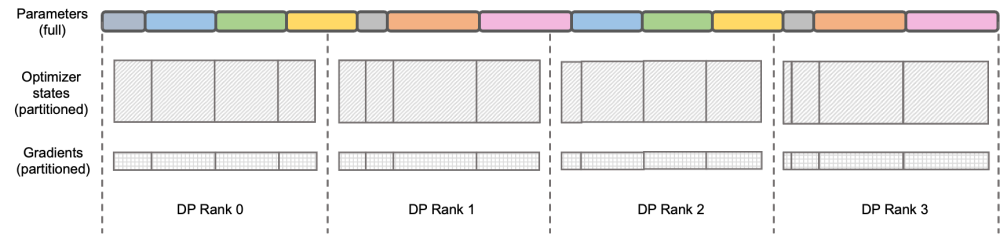 图示:DeepSpeed ZeRO Stage-2
图示:DeepSpeed ZeRO Stage-2
DeepSpeed ZeRO 是微软推出的一套分布式训练框架,其中提出的技术对很多后来的框架都有非常深远的影响。DeepSpeed ZeRO Stage-2(后文简称 ZeRO-2)是该框架中一项节约显存占用且不增加额外计算量和通信量的技术。如上图所示,由于计算需要,每个 Rank 都需要拥有全部的参数。但对于优化器状态而言,每个 Rank 只负责其中的一部分即可,不必所有 Rank 同时执行完全重复的操作。于是 ZeRO-2 提出将优化器状态均匀地切分在每个 Rank 上(注意,这里并不需要保证每个变量被均分或完整保留在某个 Rank 上),每个 Rank 在训练进程中只负责对应部分的优化器状态和模型参数的更新。在这种设定下,梯度也可以按此方式进行切分。默认情况下,ZeRO-2 在反向时在所有 Rank 间使用 Reduce 方式聚合梯度,而后每个 Rank 只需要保留自身所负责的参数的部分,既消除了冗余的重复计算,又降低了显存占用。
Megatron-LM DistributedOptimizer 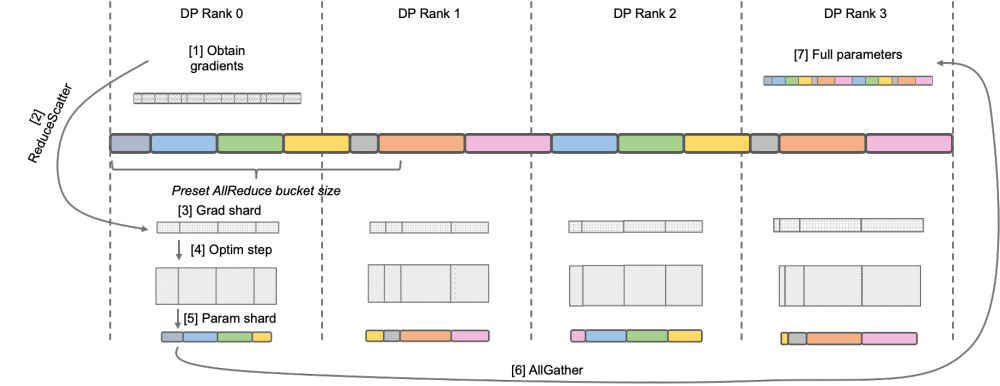 原生 Megatron-LM 通过 DistributedOptimizer 实现了类似 ZeRO-2 的梯度和优化器状态切分,以减少训练中的显存占用。如上图所示,DistributedOptimizer 在每次获得预设的梯度聚合过的所有梯度后,通过 ReduceScatter 算子,将之前累积的全部梯度分发到不同的 Rank。每个 Rank 只获得自己需要处理的部分梯度,而后进行优化器状态的更新和对应参数的更新。最后各个 Rank 通过 AllGather 的方式从其他节点上获取更新过的参数,最终取得全部的参数。实际训练的结果显示,Megatron-LM 的梯度和参数通信与其他计算串行进行,对于大规模预训练任务,为了保证总批数据大小不变,通常无法开启较大的 GA。于是通信占比会伴随机器增加上升,这时候串行通信的特点导致扩展性很弱。在社区内,这方面的需求也很迫切。
原生 Megatron-LM 通过 DistributedOptimizer 实现了类似 ZeRO-2 的梯度和优化器状态切分,以减少训练中的显存占用。如上图所示,DistributedOptimizer 在每次获得预设的梯度聚合过的所有梯度后,通过 ReduceScatter 算子,将之前累积的全部梯度分发到不同的 Rank。每个 Rank 只获得自己需要处理的部分梯度,而后进行优化器状态的更新和对应参数的更新。最后各个 Rank 通过 AllGather 的方式从其他节点上获取更新过的参数,最终取得全部的参数。实际训练的结果显示,Megatron-LM 的梯度和参数通信与其他计算串行进行,对于大规模预训练任务,为了保证总批数据大小不变,通常无法开启较大的 GA。于是通信占比会伴随机器增加上升,这时候串行通信的特点导致扩展性很弱。在社区内,这方面的需求也很迫切。 
Megatron-LLaMA OverlappedDistributedOptimizer
为了解决这一问题,Megatron-LLaMA 改进了原生 Megatron-LM 的 DistributedOptimizer,使其梯度通信的算子能够可以和计算相并行。特别的,相比于 ZeRO 的实现,Megatron-LLaMA 在并行的前提下,通过巧妙的优化优化器分区策略,使用了更具有具有扩展性的集合通信方式来提升扩展性。OverlappedDistributedOptimizer 的主要设计保证了如下几点:a) 单一集合通信算子数据量足够大,充分利用通信带宽;b) 新切分方式所需通信数据量应等于数据并行所需的最小通信数据量;c) 完整参数或梯度与切分后的参数或梯度的转化过程中,不能引入过多显存拷贝。 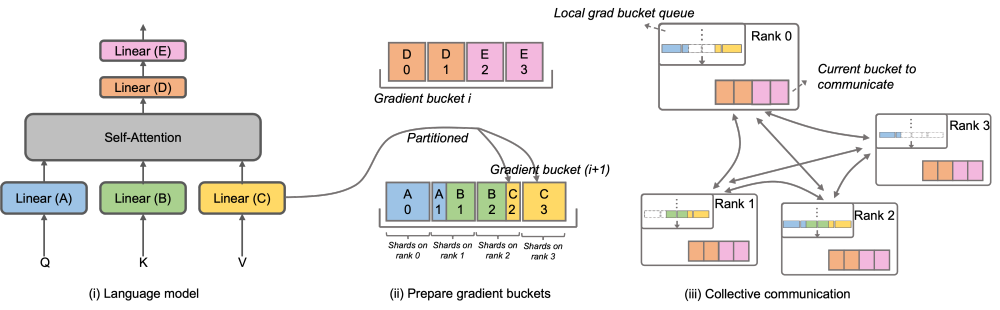
Megatron-LLaMA 的未来计划
更多模型结构或局部设计改动的支持
项目地址:https://github.com/alibaba/Megatron-LLaMA
以上就是淘天集团与爱橙科技合作发布开源大型模型训练框架Megatron-LLaMA的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/967303.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫