
前言
在如今的大模型部署世界里,大家讨论得最多的往往是模型本身:参数规模、上下文长度、推理速度、吞吐表现……但只要真正踩过一次从“模型参数”到“实际落地推理服务”的坑,很快就能意识到,决定性能上限的其实并不是模型本身,而是躲在系统底层的那一层算子实现。尤其是在像 deepseek-v3.2-exp 这种体量级别的模型里,任何一个算子的执行效率、调度策略、内存占用乃至调优方式,都可能在最终推理效果上被无限放大。
PyPTO(Python-based PTO Operator)正是这样一个容易被忽视、但在大型模型推理链路中极其关键的角色。它既不是简单的 PyTorch 包装层,也不是某种为特定硬件而写的 kernel glue,相反,PyPTO 更像是一个“介于框架与硬件之间的软垫层”,负责把模型中的关键计算步骤、特定结构(例如 DeepSeek 的 Sparse Attention、MoE Experts 调度、长上下文 KV 缓存策略)精确而高效地映射到目标设备上。对于 GPU,如 CUDA;对于 NPU,则是 CANN、AscendC;对于多节点系统,则必须进一步考虑通信拓扑与算子调度策略。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜
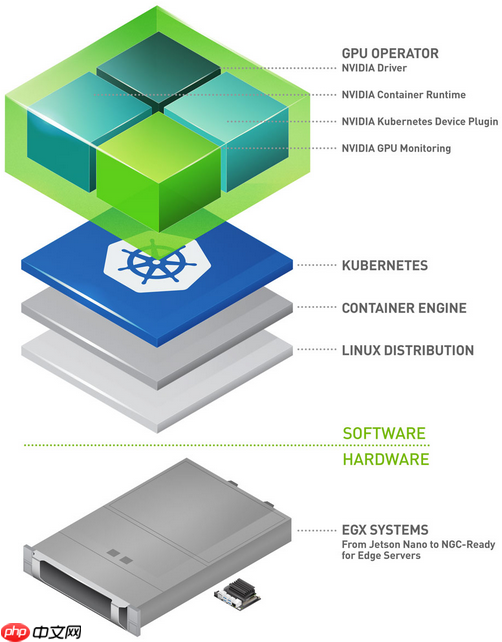
换句话说,PyPTO 不是“模型能不能跑起来”的问题,而是“模型能不能跑好、跑稳、跑快”的关键。
DeepSeek-V3.2-Exp 官方文档(pypto operator guide / ascendc operator guide / inference guide)分别从算子逻辑、硬件适配以及整体推理路径出发,构成了一套较为完整的解释体系。本篇文章希望在此基础上,站在一个大模型工程师的角度,梳理 PyPTO 的技术背景、核心功能、关键设计思路,以及它在真实工程场景中“为什么重要、如何发挥价值”。
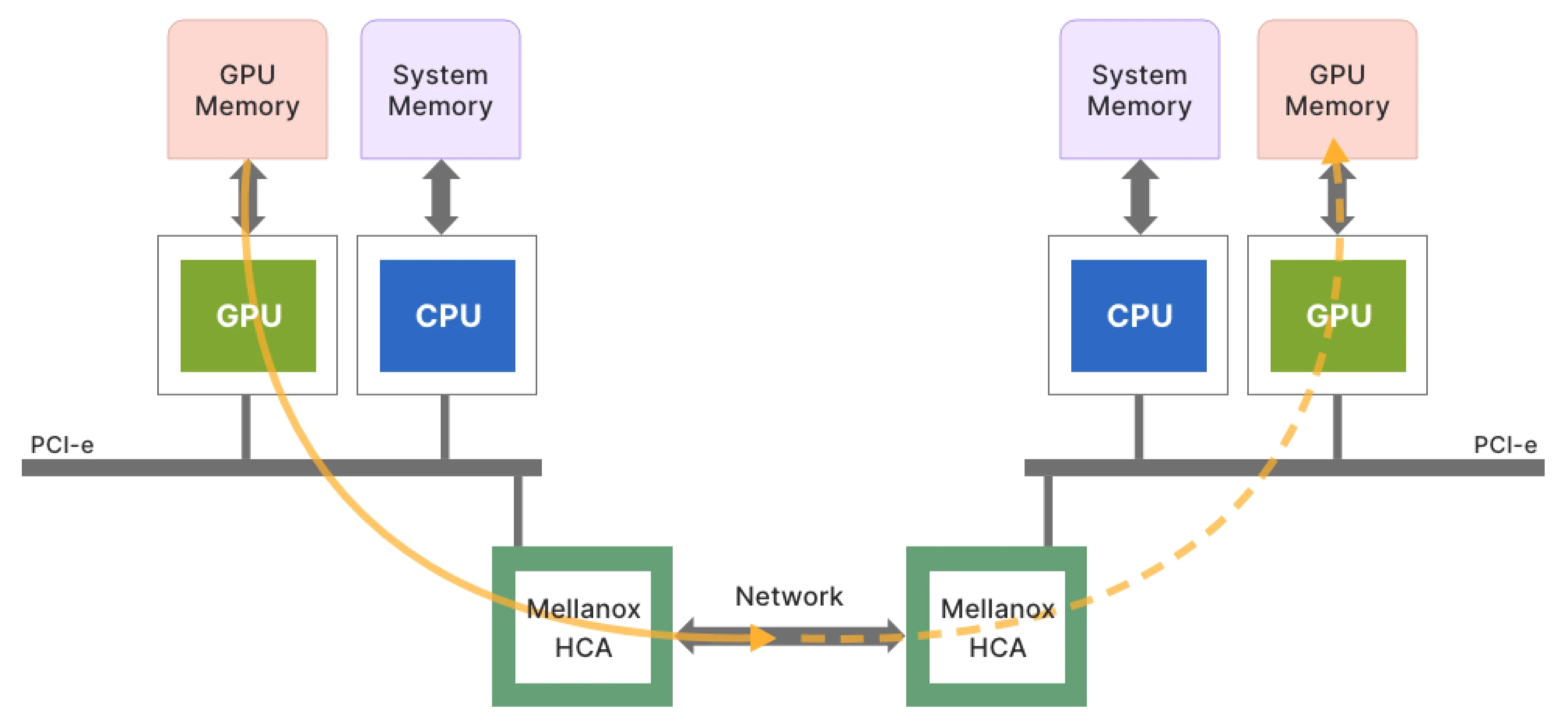
如果你正在做自研 LLM 部署、在 GPU/NPU 之间迁移模型、需要手动调优算子行为,或者正在搭建一个“能稳定跑 7×24 小时”的推理服务,那么你大概率会在文中找到某些与你经历相同的部分。
接下来,我们会从 PyPTO 的角色定位讲起,然后深入它的算子结构、运行逻辑、适配机制,最后结合 DeepSeek-V3.2-Exp 的部署文档,给出一套完整可落地的理解框架。
我是Fanstuck,致力于将复杂的技术知识以易懂的方式传递给读者,热衷于分享最新的行业动向和技术趋势。如果你对大模型的创新应用、AI技术发展以及实际落地实践感兴趣的话,敬请关注。
一、大模型推理与算子体系
如果说早期的深度学习部署还停留在“模型导出 → 推理框架载入 → 直接跑起来”这个相对线性的流程,那么从 70B、300B 到现在动辄上千亿参数的模型,整个推理体系已经演变成一种高度精细化、强依赖底层优化的工程生态。你可以把它类比成高性能数据库的查询优化器:真正决定性能的不是 SQL 本身,而是底层的执行计划。
在大模型世界里,执行计划就是“算子(Operator)”。
要理解 PyPTO 的出现,我们先得把当前大模型推理的几个现实放回到桌面上。
1.1DeepSeek 系列模型的技术背景
DeepSeek-V3.2-Exp 系列模型本身已经不是“搭个 transformer、堆点层数”这么简单的结构,而是集成了大量面向性能和长上下文的复杂机制,比如:
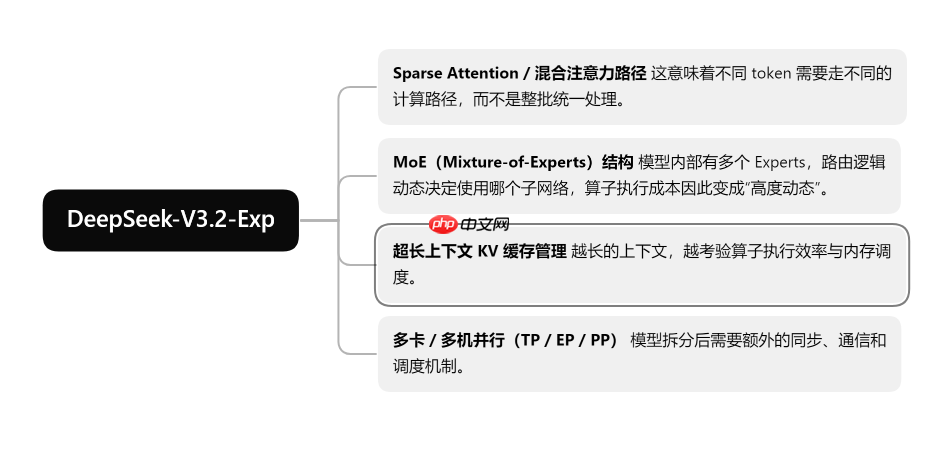
这些东西不是“多写几行 PyTorch”就能搞定的,尤其是在推理场景里,你必须保证延迟、吞吐、资源占用都稳定可靠。
而 PyPTO 就是在这样的背景下被推上舞台的:它的任务是把这些复杂结构的计算拆解成可控的算子,并映射到具体的硬件执行路径里。
1.2Operator 在大模型部署中的地位
在推理框架(如 PyTorch、vLLM、AscendC Runtime、Megatron、CANN Runtime)之下,真正执行矩阵乘法、attention、softmax、路由、KV 管理等工作的,是算子。算子就像一个个“小型程序单元”,专门负责某一类数学计算或数据处理操作。
而随着模型规模爆炸式增长,算子的角色已经变成了:

PyPTO 的设计初衷,就是要让 DeepSeek-V3.2-Exp 系列的核心组件拥有可控、可调优且可移植的 Operator 层。从官方的 PyPTO operator guide 可以看出,PyPTO 已经不仅仅是一个“可加可不加的扩展模块”,一方面模型结构复杂到需要专用算子,尤其是 Sparse Attention + MoE 路由这类场景;
另一方面不同硬件差异巨大,GPU 用 CUDA kernel,NPU 用 CANN / AscendC kernel,两者性能差距完全取决于算子层怎么写。同时上述也影响了框架之间的能力,vLLM、PyTorch、TensorRT、MindSpore,各自的 operator 能力和接口不同,PyPTO 的职责就是做「统筹」。因此PyPTO 算是整个 DeepSeek-V3.2-Exp 推理流程中的关键环节,PyPTO 的存在价值不是“满足模型需求”,而是“让这个规模的模型有能力在生产环境稳定运行”。

二、PyPTO Operator 深度解析
2.1PyPTO 到底是什么?
如果你第一次打开 PyPTO 的 Operator 源码,比如 quant_lightning_indexer_prolog.cpp,很可能会有种既熟悉又陌生的感觉。熟悉的是:里面几乎都是你在算子开发中见过的 Cast、Matmul、Reshape、Concat、Transpose;陌生的是:这些操作却并不是用标准 CUDA Kernel 或传统算子 API 写出来的,而是通过 CANN/Ascend 的 Tile-Level Operator Framework(tile_fwk) 来“编排”出的执行路径。
 TextCortex
TextCortex
AI写作能手,在几秒钟内创建内容。
 62 查看详情
62 查看详情 
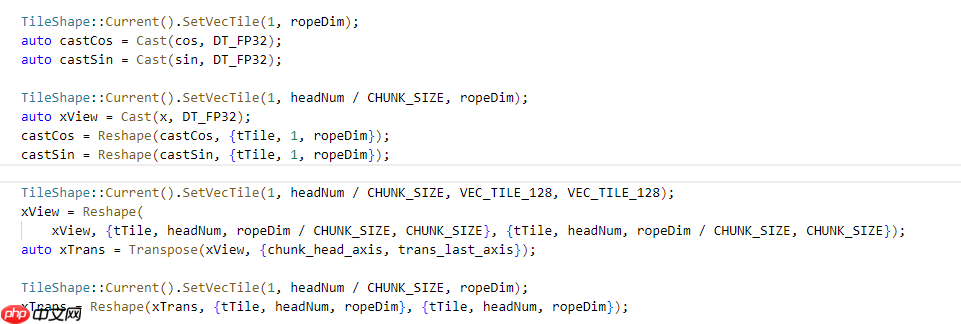
这其实正点出了 PyPTO 的核心定位: PyPTO 不是某一种算子,而是一套用于构建“可控、可复用、可调优算子”的轻量级算子 DSL(领域算子语言),专门用于支撑 DeepSeek 系列这种复杂模型的推理需求。
换句话说,如果把大模型推理看作一条 pipeline,那 PyPTO 就像是 pipeline 里的一段“可编程执行器”。 它的工作方式不是“调用某个固定的库函数”,而是“利用一套基础操作,把复杂计算路径现场拼装出来”。
从 PrologQuant() 开始我们能看出PyPTO 是“算子层的编排器”,而不是某种 Kernel 实现:
auto inputFp32 = Cast(input, DataType::DT_FP32, CAST_NONE); auto absRes = Abs(inputFp32); auto maxValue = RowMaxSingle(absRes); ... auto outInt8 = Cast(outHalf, DataType::DT_INT8, CAST_TRUNC); 这些操作本质上并不是 “C++ 函数逻辑”,而是调用 TileFwk 的原子算子(Cast、Abs、RowMax、Mul、Div、Concat…),最终由 CANN Runtime 把它们调度到 NPU 上执行,也就是说,PyPTO 在这里扮演的是把一条复杂计算展开成底层算子序列。它不负责实现 Matmul/Cast/Reduce 的具体低层 kernel,而是告诉底层 runtime:“我要按这个顺序执行这些操作,你帮我按最佳方式调度”。
这种模式的好处是可以随时调整算子组合,插入语义标签(用于 profiling),可以根据动态 shape 自动决定执行路径而不需要每写一个逻辑都重新实现 kernel。对于像 DeepSeek-V3.2-Exp 这种结构复杂的模型,这种“可拼装式 Operator”反而更灵活。
2.2PyPTO 的基本能力
PyPTO 的基本能力来自 Tile-Level 框架,而非 PyTorch/CUDA,从
TileShape::Current().SetVecTile(1, ropeDim);以及:
LOOP("QuantIndexerPrologLoop", FunctionType::DYNAMIC_LOOP, tIdx, LoopRange(t), unrollList)就能看出 PyPTO 的核心依赖是控制算子的 Tile 切分策略的TileShape,Dynamic Loop + SymbolicScalar 支持动态长度(如 tTile),Matrix::Matmul 是 tile_fwk 下的高性能 Matmul 接口,整个算子逻辑通过 DSL 风格 写好后,由 CANN Runtime 决定如何调度。

它不像 CUDA 里那样 kernel-level 手写 thread/block/grid,也不像 PyTorch 里那样简单写个 torch.matmul() 就完事。而是给算子开发者一种“高层描述到底层自动优化”的写法。
所以,PyPTO 可以说是写算子的中层编排工具,而不是底层 kernel 编写工具。这也是为什么 DeepSeek 官方提供 PyPTO Operator Guide,而不是让开发者直接去写内核。
2.3高度结构化的模型逻辑处理
例如在 QuantRope3D 中:
auto xView = Cast(x, DT_FP32); xView = Reshape(xView, {tTile, headNum, ropeDim / CHUNK_SIZE, CHUNK_SIZE}); auto xTrans = Transpose(xView, {chunk_head_axis, trans_last_axis});这不是普通的 rope,而是分 head /分 block/分 chunk,在 tile 粒度执行 transpose,再配合 cos/sin 做三维 rope 编码,最后再 reshape 回原来的结构。普通框架中很难做到这么细粒度、可控的 rope 设计,但在 PyPTO 中,只需通过基本操作组合即可。
同理,在主算子 QuantLightningIndexerPrologCompute() 里,你可以看到整套 Query/Key 的预处理流程

这些步骤的复杂度远远超过“一般 transformer 模型”,只有 PyPTO 这种“可编排式算子框架”才能容纳得下。
2.4PyPTO高性能推理指向
从:
config::SetRuntimeOption("machine_sched_mode", MachineScheduleConfig::L2CACHE_AFFINITY_SCH);看出主要目的是降低推理时的 memory stall、提高流水化效率,一般来说训练中不会使用这类优化。大量 FP16/INT8 转换也说明其定位更偏向推理:
auto outInt8 = Cast(outHalf, DataType::DT_INT8, CAST_TRUNC);也包括量化前的 FP32 normalization,Rope 的 tile-level 展开,Query/Key 的动态片段(tTile)运算和ScatterUpdate 写入 KCache。这些都指向一个事实:PyPTO Operator 是为推理(尤其是 NPU 推理)设计的算子拼装层,旨在充分挖掘硬件吞吐量、降低延迟、提升能效。
以上就是深入解析 PyPTO Operator:以 DeepSeek‑V3.2‑Exp 模型为例的实战指南的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/985273.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 






















