
deep research agent –狐獴家族系列(二)
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜
 descript
descript
在通义“狐獴家族”(一)中,我们系统介绍了 WebWalker、WebDancer、WebSailor、WebShaper、WebWatcher 以及 WebSailor V2 论文的工作,梳理了 WebAgent 所遵循的“数据合成—采样轨迹—冷启动—强化学习”通用流程范式,分析了各篇论文在各个环节中的关键优化,尤其是数据合成方法的持续演进,使得 WebAgent 能够有效应对复杂的多跳推理任务。
然而,随着任务复杂度的不断提升,Agent在执行过程中累积的轨迹上下文迅速膨胀,逐渐逼近甚至超出模型的最大上下文长度限制,由此引发的核心挑战便是上下文爆炸。
本文将聚焦于Tongyi Deep Research Agent家族中,针对长上下文信息爆炸问题所提出的创新解决方案。
通义 DeepResearch git代码:
https://github.com/Alibaba-NLP/DeepResearch
通义 DeepResearch技术报告
https://tongyi-agent.github.io/zh/blog/introducing-tongyi-deep-research/
1 WebResearcher
WebResearcher: Unleashing unbounded reasoning capability in Long-Horizon Agent (2025-09-23)
论文地址: https://arxiv.org/pdf/2509.13309
1.1 背景和动机
之前介绍的Deepresearch方案均采用线性累积策略,通过不断扩展的上下文窗口整合所有工具调用、检索结果和推理步骤,在处理复杂任务时面临三大核心挑战:上下文爆炸(超出模型最大上下文限制)、噪声污染(早期错误与冗余信息层层累积)以及推理性能的显著下降。
Tongyi团队出了一种创新框架WebResearcher,其核心包含两个关键组件:
(1)IterResearch一种迭代式深度研究范式
(2)WebFrontier一种可扩展的数据合成引擎。
1.2 论文方案
1.2.1 IterResearch
IterResearch是基于迭代的深度研究范式,问题转化为马尔可夫决策过程,Agent能够定期将研究成果整合到不断演进的报告中,同时保持专注的工作空间,从而有效克服现有单一上下文方法中常见的“情境窒息”和“噪声污染”问题。
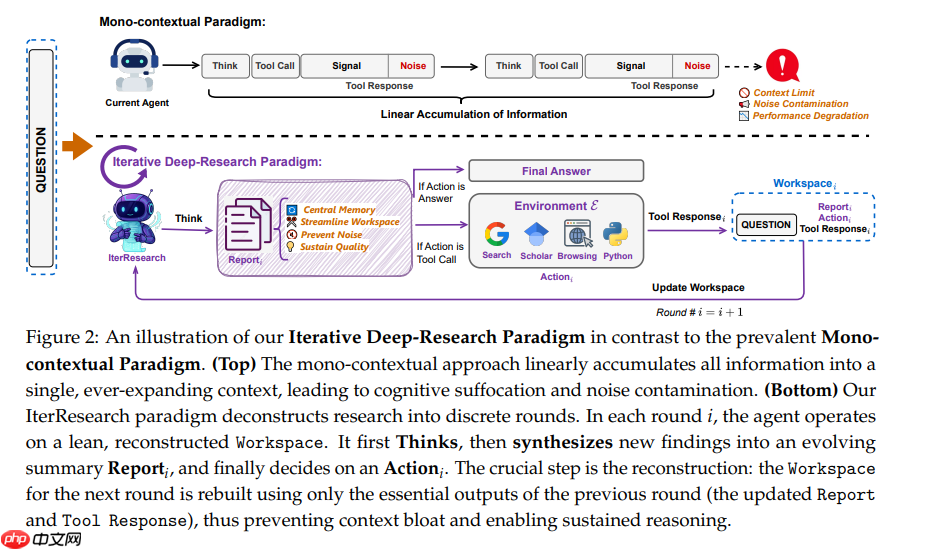 descript
descript如上图,IterResearch的核心思想是用迭代式合成与重构取代线性累积。在每轮研究中,系统都会在一个专注的工作空间内运作,既保持清晰度,又通过不断更新的报告实现连续性,该报告充当智能体的中央记忆。
在第i轮,智能体的状态si由三个部分组成:Think–Report–Action
原始的研究问题q;(2) 上一轮的动态报告;(3) 最近执行的动作。
这种紧凑的状态表示不仅确保了马尔可夫性质,还完整保留了所有关键信息,以支持决策制定。
1.2.2 WebFrontier
WebFrontier提出了一套可扩展的数据合成引擎。通过工具增强的复杂度递增策略生成高质量的训练数据,助力系统化地创建研究任务。
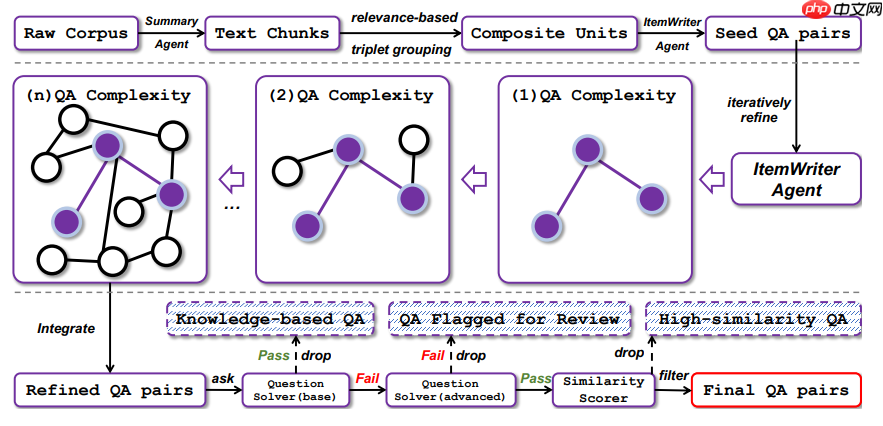 descript
descript主要三个阶段的迭代工作流:
(1)种子数据生成:基于网络数据构建可验证、有明确参考答案的研究任务。
(2)逐步提升任务复杂度:使用大模型和工具,用强求解器生成复杂、长链路的数据。
(3)严格的质量控制: 保证每条数据都是可用且可检验的 high-signal 轨迹。
1.2.3 推理框架
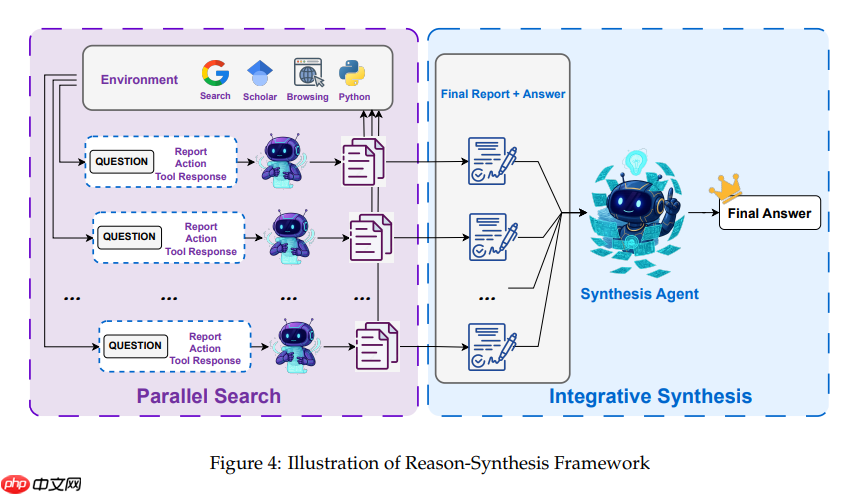 descript
descript在测试推理阶段,每个并行研究阶段部署多个SearchAgent,各自独立地解决目标问题。每个智能体都遵循IterResearch范式,但通过调用不同工具、生成各异的推理路径,开辟出独特的解决方案轨迹,最终使用合成Agent得到最终的报告。
1.3 主要贡献
WebResearcher的核心创新点在于提出了IterResearch(迭代深度研究范式)和WebFrontier(可扩展数据合成引擎),解决了推理轮数线性累计上下文的单一范式。
在HLE 和 BrowseComp 等六个挑战性基准测试中,性能显著优于现有的开源,并超越 OpenAI Deep Research闭源系统。
2 WebWeaver
WebWeaver: Structuring Web-Scale Evidence with Dynamic Outlines for Open-Ended Deep Research (2025-10-08)
论文地址: https://arxiv.org/pdf/2509.13312
2.1 背景和动机
前面介绍的论文都是基于深度网络检索解决复杂多跳问题。在生成和构建QA对的方案中,我们也可以发现,都是基于实体或者有明确答案的问题来获取推理路径。但是很多检索问题是没有明确答案的,论文中叫Open-Ended Deep Research(OEDR),比如深度研究报告。所以,我认为前面的论文工作都属于深度检索方面的研究;而从WebWeaver开始才是真正的深度研究报告,开始输出一份完整的研究报告。
WebWeaver是一种多Agent报告撰写系统。类似人类写文章,我们都是先搜索一堆网页,然后通过标题和摘要选出重要文献,进行详细内容查看,整理出文章大纲。然后再基于文献针对每个章节扩展。
WebWeaver是一样的思路,框架由一个Planner和一个Writer组成。Planner负责动态循环地获取证据并优化大纲,而Writer则执行取自于证据库、以章节为单位的合成过程来构建最终的报告。
2.2 论文方案
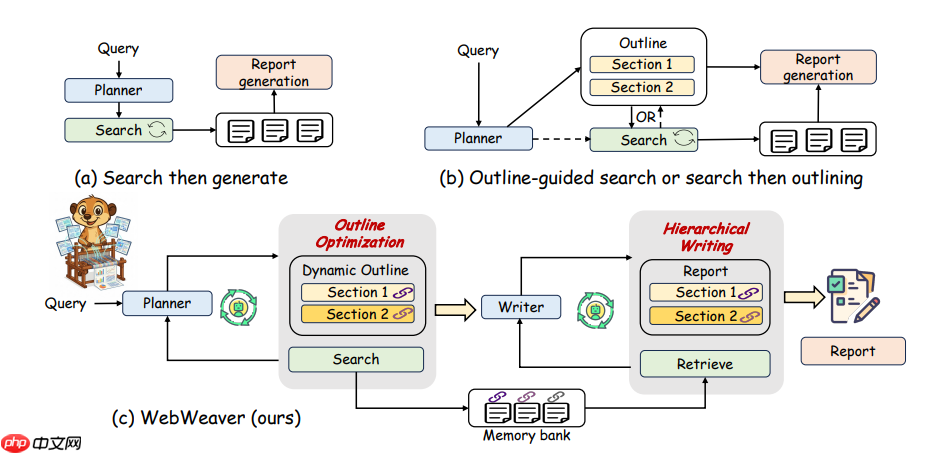 descript
descript针对写报告的Deepresearch工作,目前的主流方案都存在问题。a)方案将检索信息一次性给大模型进行报告生成,容易导致上下文爆炸,中间信息丢失和长文本性能降低等问题。 b)方案生成静态大纲再检索证据进行报告章节撰写,存在研究过程僵化的问题,如果在检索过程中发现了新的信息,无法调整框架限制报告生成质量。
所以论文提出了c)方案WebVeaver,框架流程如下图:
 descript
descript2.2.1 动态研究循环(Dynamic Research Cycle)
规划者(Planner):迭代地交替执行证据检索与大纲优化。代理根据新发现的证据动态调整大纲结构(如新增子章节、修改逻辑顺序),生成全面且结构良好的大纲。
证据库(Memory Bank):存储结构化证据(如引用片段、数据点),并为大纲章节添加显式引用,确保后续写作有据可依。
2.2.2 分层注意力写作(Hierarchical Attentional Writing)
写作者(Writer):基于优化后的大纲,逐章节执行“检索-思考-写作”循环。
针对性检索:仅从证据库中提取当前章节所需证据,避免冗余信息干扰。
动态上下文管理:完成章节后立即移除无关证据,防止上下文溢出和跨章节干扰。
内部推理(Internal Reasoning):在写作前通过“思考”步骤分析证据、构建叙事逻辑,超越简单摘要,实现深度综合。
2.3 主要贡献
WebWeaver框架模仿人类研究过程:查询→ 检索→ 大纲演化→ Memory Bank → 分节写作的框架流程,在开放式深度研究(OEDR)基准测试中建立了新的最高水平(SOTA)。同时构建了 WebWeaver-3k数据集,包含了3.3k 规划轨迹 + 3.1k 写作轨迹,使用 WebWeaver-3k 微调后,7B 模型在 OEDR 任务中的表现可与 175B 模型相媲美。
另外在长上下文方面,使用大纲和章节多阶段的方式缓解一次性输入检索内容进行生成的信息爆炸问题,在撰写章节过程中是记忆库(证据库)中进行检索。
3 WebReSummer
ReSum: Unlocking Long-Horizon Search Intelligence via Context Summarization (2025-10-16)
论文地址: https://arxiv.org/pdf/2509.13313
 Word-As-Image for Semantic Typography
Word-As-Image for Semantic Typography
文字变形艺术字、文字变形象形字
 62 查看详情
62 查看详情 
3.1 背景和动机
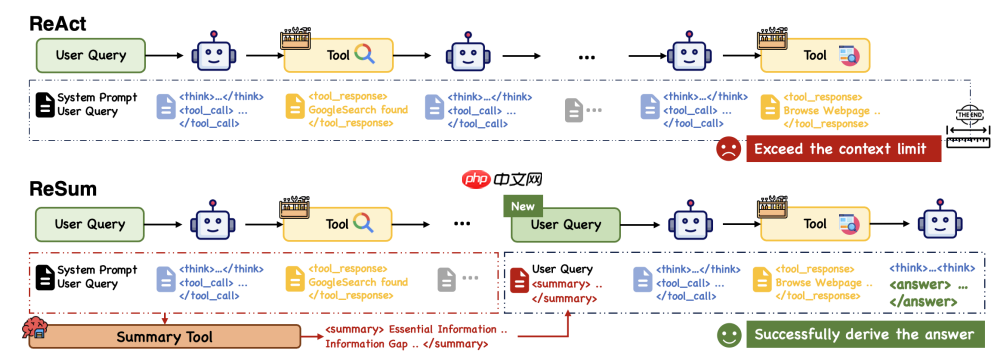
即使WebResearcher和WebWeaver在上下文记忆上做了很多工作,但是使用ReAct 框架,需要记录多轮think, tool_call, tool_response的信息,对复杂问题很容易触达上下文上限,使得探索被迫中断、最终无法完成推理。
WebResummer(ReSum) 提出就是为了解决React框架的缺陷。ReSum思路是在探索过程中,阶段性的进行结构话总结,并基于该总结继续决策,从而突破上下文窗限制,达到“理论上无限长”的探索和推理。
 descript
descript3.2 论文方案
3.2.1 Resum框架
ReSum 仅对 ReAct 做最小修改,避免增加额外的架构复杂度,确保能够与现有Agent即插即用兼容。他的思路也非常简单但高效:
流程如下:
历史累计:智能体正常按 ReAct 流程执行触发总结:当上下文接近 Token 限制时,触发压缩逻辑摘要工具:调用ResumTool工具,将历史对话压缩为关键证据 + 信息缺口重启推理:agent将(原问题 + 摘要)作为新的起点继续搜索
3.2.2 ReSumTool-30B:专用摘要模型
通用的大模型进行摘要,和从长推理工具调用和返回结果链路的交互中提取关键证据进行摘要的目标不一致,所以论文为了支持以目标为导向的对话摘要,针对性训练开发了 ReSumTool-30B。
ReSumTool-30基于Qwen3-30B-A3B-Thinking微调,30B效果超越 Qwen3-235B、DeepSeek-R1-671B 等更大规模模型。
流程如下:
高质量数据:在 SailorFog-QA 上运行完整 ReSum 轨迹,当对话接近上下文上限时触发总结,并让强模型(如 Qwen or DeepSeek)产出结构化 SummarySFT模型微调:将长对话(含多轮 Thought–Action–Observation)与对应 Summary 组成 〈Conversation, Summary〉作为训练数据,微调ReSumTool-30B模型。
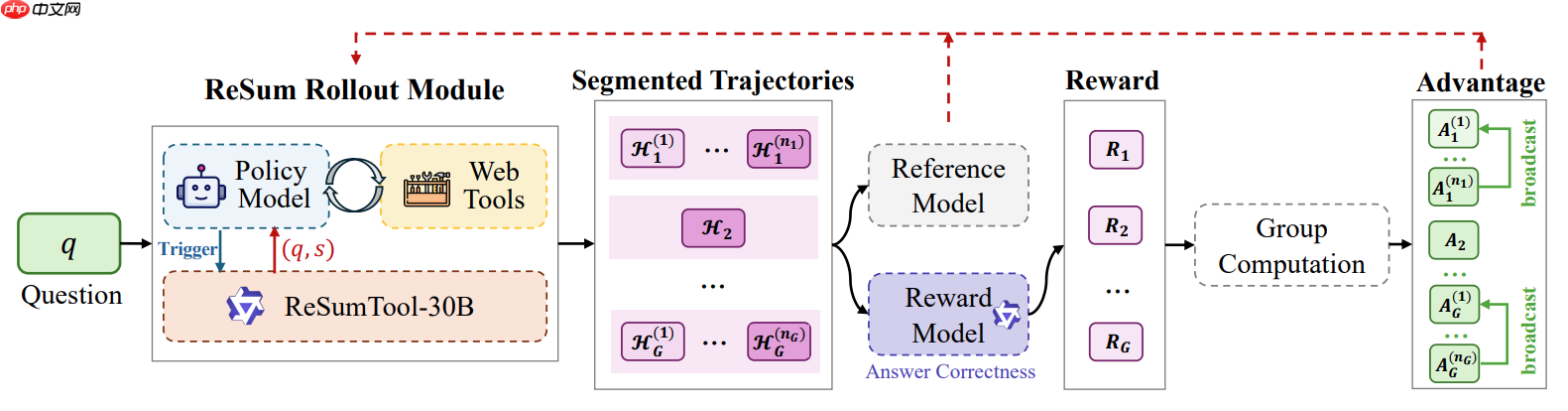
3.2.3 ReSum-GRPO:用于范式适配的强化学习方法
由于Resum引入的数据格式是summary+Qurey,通用Agent并不直接适配。论文又引入ReSum-GRPO 来让Agent习惯基于摘要的推理方式。该方法会将长轨迹切分为多个片段,并将轨迹级别的优势广播到所有片段。在三个具有挑战性的基准测试中,ReSum 在各种 Web 智能体上相比 ReAct 平均提升 4.5%,在经过 ReSum-GRPO 训练后进一步额外提升 8.2%。只使用了1k高质量数据就将模型训练达到SOTA级别。
 descript
descriptReSum-GRPO最核心的思路是将长轨迹进行了分段,然后在GRPO奖励函数设计时是将整个轨迹结果的奖励广播到了每个小段,让每个片段的轨迹在学习过程种为最终结果负责。
3.3 主要贡献
ReSum的主要贡献是提出了ReSum框架,能够在其他DeepResearch框架上即插即用使用ResumTool工具进行阶段性的总结。而这个思路其实在很多长记忆项目或者RAG应用中是常用的,随着长上下文的爆炸,需要不断的对信息进行压缩。
另外提供了ReSumTool-30B模型和训练方案,目前模型还没有开源,git是后续会开源。
4 AgentFold
AgentFold: Long-Horizon Web Agents with Proactive Context Management(2025-10-29)
论文地址: https://arxiv.org/pdf/2510.24699
4.1 背景和动机
WebAgent面临的核心挑战,是如何在上下文的全面性与简洁性之间取得平衡,尤其是对于复杂问题暴露的挑战尤为显著。而目前主流的ReAct类Agent在ReSum中也指出虽然他的信息完整,但是上下文过长容易受到噪声干扰而且极易超出模型限制;ReSum类Agent对每一步进行摘要压缩,但是过于机械,通常是在达到一定长度或者步骤后触发摘要工具,很容易过早将关键细节丢失,造成重要信息损失。
为了解决ReSum框架的缺陷,一种既能有效提炼信息、又能保留关键细节并支持迭代优化的上下文管理机制AgentFold被提出。
 descript
descript4.2 论文方案
AgentFold方案的流程如下:
 descript
descriptAgentFold’s Context: Multi-Scale State Summaries, Latest Interaction
AgentFold 上下文包含两个关键部分:
多尺度状态摘要:属于长期记忆,由多个折叠块组成,每个块可包含一步或多步
,形成多尺度结构。
最新交互:属于短期记忆,完整记录最近一步的操作,完整保留上一步的思考、动作与观察,用于短期推理。
AgentFold’s Response: Thinking, Folding, Explanation, Action
AgentFold 的响应由四个模块组成:思考、折叠、解释和工具调用。
Thinking 是完整的内部思考链条,用于在模型内部权衡各种折叠与行动方案
Folding 是显式的“上下文改写指令”,决定如何对历史步骤进行折叠与重组,Flod结果用于更新到下一轮的上下文;
Explanation 是对当前决策依据的简要说明,既帮助后续步骤保持语义连贯,也便于人类理解;
Action 则是具体的外部动作(如搜索、访问网页或给出最终答案)。
其中,折叠指令(folding directive)又包含两种操作模式:
细粒度压缩(granular condensation):对单个步骤进行折叠,保留其中有用的信息;
深度整合(deep consolidation):对多个步骤进行折叠,生成粗粒度摘要。
从时间维度看,细粒度压缩更像是“随手记笔记”:每一步结束后把关键结果浓缩成一条短摘要;而深度折叠则像是“阶段性回顾与归档”:当某个子任务告一段落时,对前面整段探索进行整体复盘,为后续规划提供清晰的阶段结论。
如下AgentFold 的案例研究示意图,在经历一系列失败尝试(步骤6至16)后,AgentFold 意识到当前方向可能是一条死胡同,于是将这些中间步骤折叠为一条结论,规划转向其他搜索方向,并确定了新的搜索查询。
 descript
descript4.3 主要贡献
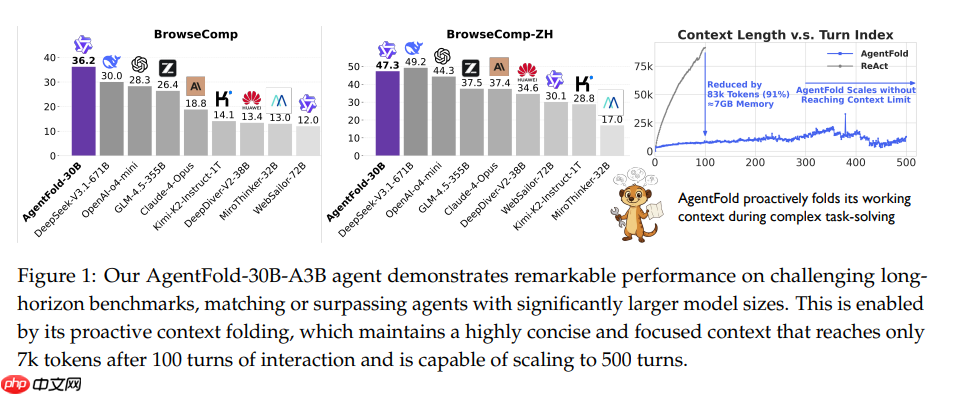
AgentFold-30B-A3B在长跨度基准测试中的性能表现,在100轮交互后仅需7k token的上下文即可维持高效推理,并支持扩展至500轮交互。
AgentFold主要贡献在于提出了一种类似人类长期记忆和短期记忆的思路,其核心思想是将认知工作空间分为多尺度的块状结构,并使用Granular Condensation和Deep Consolidation两种操作来动态调整这些块的大小和数量。这种机制使得AgentFold能够根据任务需求自适应地控制记忆压缩大小和结构,从而提高信息获取效率和长期问题解决能力。而这种思路和Agent中长记忆模块的中长期记忆和短期记忆的思路是类似的,AgentFold将这个思路巧妙应用到了WebAgent中。
5 总结
本文系统梳理了WebResearcher、WebWeaver、ReSum(WebReSummer)与 AgentFold都是狐獴家族应对长周期、高复杂度网页研究任务的技术演进路线。
WebResearcher( 2025-09-23)
首次提出 IterResearch 范式,以“问题 + 上轮报告 + 最新观察”为最小工作集,通过可修订的中心报告实现推理的连续性与轻量化,从根本上规避了单上下文窒息问题。
ReSum(2025-10-08)
则在兼容 ReAct 的前提下,引入阶段性结构化摘要机制,通过专用摘要模型 ReSumTool-30B 实现“探索—压缩—重启”的循环,使智能体具备理论上无限延展的推理能力。
AgentFold (2025-10-16)
更进一步,借鉴人类认知中的短期记忆与长期记忆分离机制,构建多尺度状态摘要体系,通过细粒度压缩与深度整合两种折叠策略,实现对关键信息的动态保留与冗余信息的精准剔除,在 500 轮交互中仍保持高效推理。
WebWeaver(2025-10-29)
首次将焦点转向 开放式深度研究(Open-Ended Deep Research, OEDR),提出模仿人类写作流程的 Planner–Writer 架构:通过动态大纲演化引导证据检索,再基于结构化证据库分章节撰写报告。
从 WebResearcher 的迭代报告,到 WebWeaver 的动态大纲;从 ReSum 的上下文压缩,到 AgentFold 的多尺度记忆,每一步Agent的创新和进步,都能看到在对齐人类在做深度研究的思路。
通过Tongyi Deep Research Agent 家族的系列成果,可以看到未来的 Web 智能体不应只是工具调用的执行者,而应是具备自主规划、动态反思、结构化表达与长期记忆能力的研究。
以上就是Deep Research Agent技术 –通义“狐獴家族”(二)的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/986189.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 






















