
bootstrap
-
如何使用Python和Spark Streaming高效读取Kafka数据并解决依赖库缺失错误?
Python与Spark Streaming高效读取Kafka数据及依赖库缺失问题解决 本文详细讲解如何利用Python和Spark Streaming框架高效读取Kafka数据,并解决常见的依赖库缺失错误。 核心问题:在使用Spark SQL读取Kafka数据时,出现java.lang.NoCla…
-
Spark Streaming读取Kafka数据时遇到依赖问题如何解决?
使用Spark Streaming和Python读取Kafka数据:解决依赖性问题 本文探讨如何用Python和Spark Streaming高效读取Kafka数据,并重点解决依赖问题。 问题: 在使用Spark Structured Streaming读取Kafka数据并启用Kafka身份验证时,…
-
Python和Spark Streaming读取Kafka数据时遇到java.lang.NoClassDefFoundError错误怎么办?
Python和Spark Streaming读取Kafka数据:排查依赖性问题 本文将指导您如何使用Python和Spark Streaming读取Kafka数据,并重点解决文中出现的依赖性问题。 文中遇到的java.lang.NoClassDefFoundError: org/apache/kaf…
-
开源LLMS应该得到代码,而不是提示! (DSPY,瞧!)

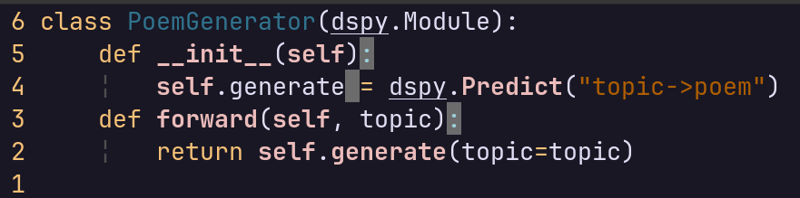


DSPY:将提示工程转变为提示编程的革命性框架 大型语言模型 (llm) 时代,新模型层出不穷。然而,充分发挥 llm 的潜力往往依赖于繁琐易错的提示工程。dspy 应运而生,它是一个开源框架,彻底改变了我们与 llm 交互的方式。dspy 将提示视为可训练、模块化的组件,而非静态文本,并通过编程方…
-
如何在Reactjs中使用Shadcn/UI

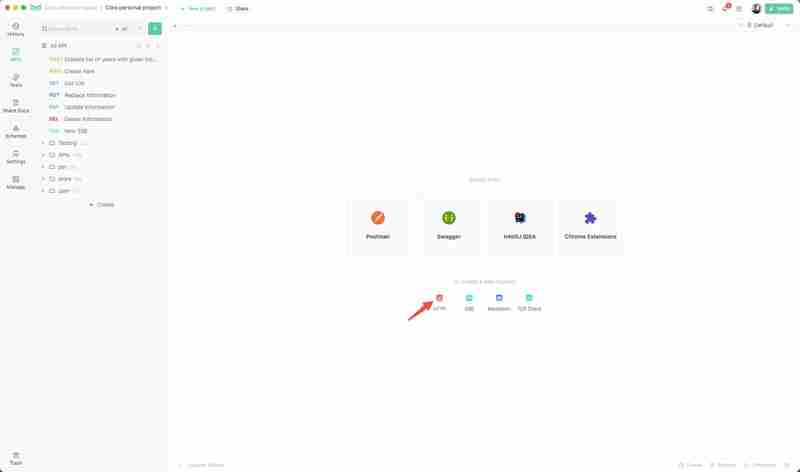
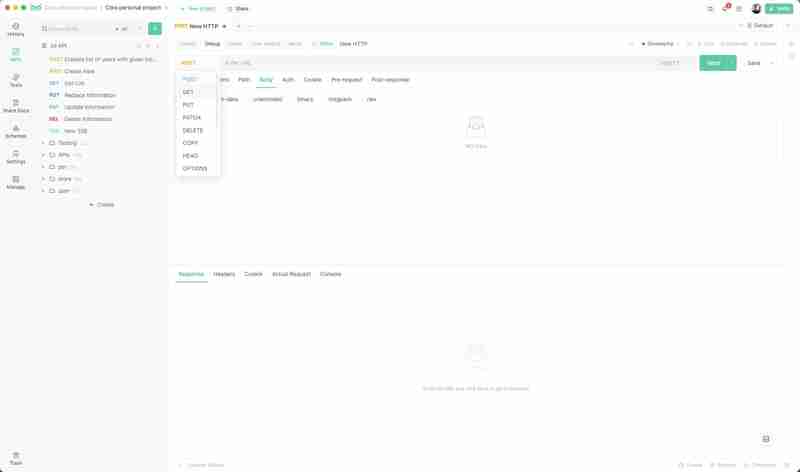
如何在 react.js 中使用 shadcn/ui 了解如何利用 react.js 中的 shadcn/ui 来构建可定制的轻量级界面。了解如何将其与 echoapi 集成以实现高效的 api 管理和测试。非常适合希望增强 react.js 项目的开发人员! 使用 shadcn/ui 构建现代界面…
-
如何在Windows系统中打包需要特定Python版本(3.11.6)的脚本?
用特定版本运行脚本并打包进文件夹 在需要特定版本(3.11.6)运行脚本但又使用 3.12 版作为主力的情况下,如何将脚本打包到文件夹中并正常执行? 解决方法: 对于 linux 系统,使用 docker 是理想的选择。但对于 windows 系统,推荐使用以下步骤: 立即学习“Python免费学习…
-
如何在共享主机的子目录中托管 Laravel 项目而不在 URL 中暴露“/public”
在共享主机上托管 laravel 项目时,一个常见的挑战是确保 url 不需要 /public 目录。这是在子目录中托管 laravel 应用程序同时保持 url 干净的分步指南。 第 1 步:将 laravel 项目上传到服务器 登录您的托管帐户并访问您的文件管理器。导航到 public_html…
-
爬虫python库怎么安装
推荐使用 pip 安装 scrapy,步骤如下:安装 pip:curl https://bootstrap.pypa.io/get-pip.py -o get-pip.py && python get-pip.py安装 scrapy:pip install scrapy验证方法:sc…
-
CSV – 在 Python 中处理本地和远程文件
编码员们大家好! 本文介绍了一个开源工具,它能够处理本地和远程 csv 文件、加载和打印信息,然后将列映射到 django 类型。当数据集变大、excel不支持自定义报告或通过数据表进行完整数据操作时,通常需要处理csv文件,并且需要api。 当前的功能列表可以进一步扩展,以将 csv 文件映射到数…
-
tea-tasting:用于 A/B 测试统计分析的 Python 包
简介 我开发了tea-tasting,一个用于 a/b 测试统计分析的 python 包,具有: 学生的 t 检验、bootstrap、cuped 方差缩减、功效分析以及其他开箱即用的统计方法和方法。支持广泛的数据后端,例如 bigquery、clickhouse、postgresql/gree…








