陈丹琦
-
陈丹琦新作:大模型强化学习的第三条路,8B 小模型超越 GPT-4o


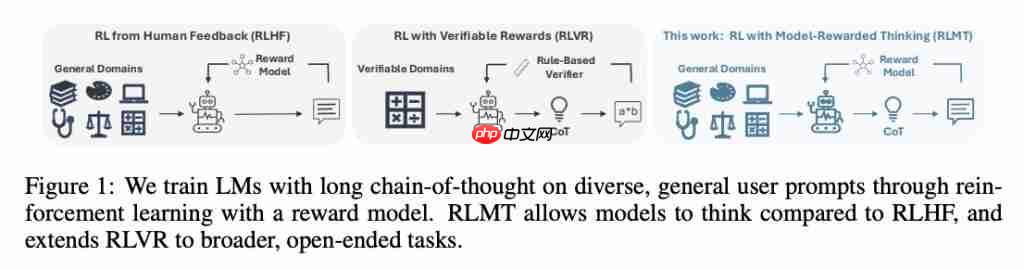
结合 RLHF 与 RLVR 的优势,仅需 8B 参数的小模型便能超越 GPT-4o,并媲美 Claude-3.7-Sonnet。 陈丹琦团队最新研究引发广泛关注。 他们提出了一种名为 RLMT(Reinforcement Learning with Model-rewarded Thinking,…

结合 RLHF 与 RLVR 的优势,仅需 8B 参数的小模型便能超越 GPT-4o,并媲美 Claude-3.7-Sonnet。 陈丹琦团队最新研究引发广泛关注。 他们提出了一种名为 RLMT(Reinforcement Learning with Model-rewarded Thinking,…
