
html元素
-
使用Selenium和JavaScript精准提取HTML标签内的直属文本内容

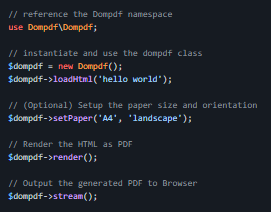


本教程详细阐述了如何利用Selenium的execute_script方法结合JavaScript,精准地从HTML标签中提取所有直接文本内容,而非其子元素中的文本。通过遍历DOM节点并识别TEXT_NODE类型,此方法能够有效解决传统文本提取方式的局限性,确保获取到纯粹的、非嵌套的文本信息。 在W…
-
Scrapy CSS选择器:利用::text伪元素精准提取HTML标签内部文本
本文深入讲解在Scrapy中使用CSS选择器时,如何通过::text伪元素精准提取HTML标签(如 标签)的纯文本内容,而非包含标签的完整html结构。教程将提供详细代码示例,并阐述get()方法的正确用法,以及如何处理多个匹配元素,帮助开发者高效、准确地获取所需数据。 在进行网页数据抓取时,我们经…
-
Scrapy CSS选择器:使用::text伪元素精准提取HTML标签内文本
本教程详细介绍了在Scrapy中使用CSS选择器提取HTML标签(特别是p标签)内部纯文本内容的技巧。通过引入::text伪元素,您可以精确地获取元素内的文本节点,而非包含标签的完整HTML片段,从而避免不必要的后处理,提升数据提取的效率和准确性。 在进行网页抓取时,我们经常需要从html元素中提取…
-
Scrapy CSS选择器提取P标签内文本的技巧


本文详细介绍了在Scrapy中使用CSS选择器提取HTML p 标签内纯文本内容的方法。核心在于利用 ::text 伪元素,它能精确地选取元素的直接文本节点,而非包含标签的完整HTML。教程通过代码示例展示了如何应用 ::text 来获取单个或多个 p 标签的内部文本,并强调了 get() 和 ge…
-
StackExchange API:高效获取问题主体内容的实用指南
本教程详细介绍了如何利用StackExchange API高效获取问题的完整主体内容。针对API默认只返回问题标题的问题,文章重点阐述了通过在请求参数中添加filter=’withbody’来确保获取包括HTML格式的正文、代码块等详细信息,从而实现更全面的数据抓取。 在使用…
-
Python Web Scraping技巧:处理同名类标签并精确筛选数据
本文详细介绍了如何利用Python的requests和BeautifulSoup库进行网页数据抓取,特别是当网页中存在多个具有相同HTML类名的元素时,如何精确筛选出所需信息。文章着重演示了如何通过高级CSS选择器,例如:-soup-contains(),来排除不符合条件的数据(如“在线视频咨询”)…
-
利用BeautifulSoup和Pandas高效抓取并结构化网页表格数据
本教程详细介绍了如何使用Python的requests、BeautifulSoup和Pandas库从复杂网页中精确提取结构化表格数据。我们将以抓取特定区域的积雪深度数据为例,演示从识别HTML元素、解析表格结构到最终构建Pandas DataFrame的完整过程,并提供实用的代码示例和注意事项。 1…
-
利用Python进行网页表格数据抓取与Pandas DataFrame转换
本教程详细介绍了如何使用Python的requests、BeautifulSoup和pandas库,从动态网页中抓取结构化的表格数据,特别是雪深信息,并将其高效地转换为Pandas DataFrame。内容涵盖了HTTP请求、HTML解析、元素定位以及数据清洗与整合,旨在提供一套完整的网页数据抓取与…
-
使用BeautifulSoup移除HTML元素中的指定标签
本文旨在介绍如何使用Python的BeautifulSoup库从HTML文档中移除特定的标签,例如移除 标签内的所有标签。我们将通过示例代码详细讲解如何定位目标标签,并使用replace_with()方法或extract()方法将其移除,最终得到清洗后的HTML内容。 在处理HTML文档时,我们经常…
-
使用BeautifulSoup移除HTML元素中的特定标签
本文旨在指导开发者如何使用BeautifulSoup库从HTML文档中移除特定的标签,同时保留标签内的文本内容。通过结合select()和replace_with()方法,可以精确地定位并移除目标标签,从而实现对HTML结构的精细控制。本文将提供详细的代码示例和步骤,帮助读者理解和掌握这一技巧。 使…








