几何
-
机器人感知大升级!轻量化注入几何先验,成功率提升 31%

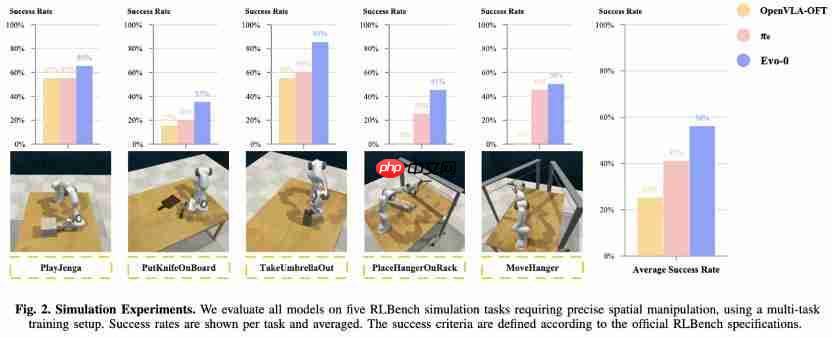
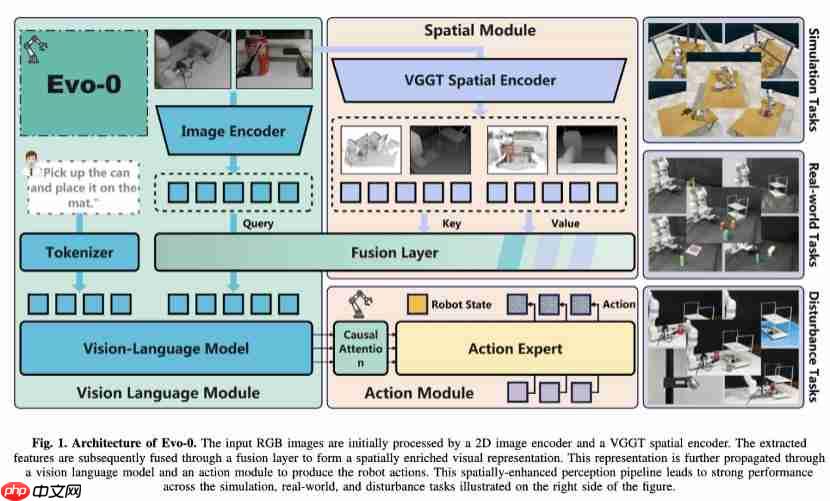
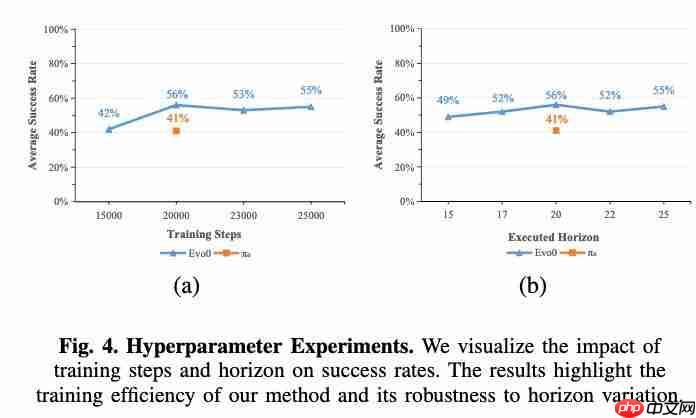
在机器人学习领域,让 ai 真正“看懂”三维世界始终是一个核心挑战。 现有的视觉语言动作(VLA)模型大多基于预训练的视觉语言模型(VLM),仅利用 2D 图像-文本对进行训练,缺乏对真实操作至关重要的 3D 空间感知能力。 虽然当前一些方法通过引入显式深度信息来增强模型,但这类方案通常依赖额外的深…

在机器人学习领域,让 ai 真正“看懂”三维世界始终是一个核心挑战。 现有的视觉语言动作(VLA)模型大多基于预训练的视觉语言模型(VLM),仅利用 2D 图像-文本对进行训练,缺乏对真实操作至关重要的 3D 空间感知能力。 虽然当前一些方法通过引入显式深度信息来增强模型,但这类方案通常依赖额外的深…
