
llama
-
离开OpenAI待业的Karpathy做了个大模型新项目,Star量一日破千




没工作也要「卷」。 闲不下来的 Andrej Karpathy 又有了新项目! 过去几天,OpenAI 非常热闹,先有 AI 大牛 Andrej Karpathy 官宣离职,后有视频生成模型 Sora 撼动 AI 圈。 在宣布离开 OpenAI 之后,Karpathy 发推表示「这周可以歇一歇了。」…
-
苹果让大模型学会偷懒:更快吐出第一个token,准确度还保住了




偷懒才能更好地工作。 Llama 3.1 刚刚发布,你是否已经尝试了呢?就算你的个人计算机是最近的顶尖配置,运行其中最小的 8B 版本可能也依然会有明显延迟。为了提升模型的推理效率,研究者想出了多种多样的方法,但其中很多都会让模型牺牲一些准确度。 近日,苹果和 Meta AI 的一个研究团队提出了一…
-
70倍极致压缩!大模型的检查点再多也不怕



AIxiv专栏是本站发布学术、技术内容的栏目。过去数年,本站AIxiv专栏接收报道了2000多篇内容,覆盖全球各大高校与企业的顶级实验室,有效促进了学术交流与传播。如果您有优秀的工作想要分享,欢迎投稿或者联系报道。投稿邮箱:liyazhou@jiqizhixin.com;zhaoyunfeng@ji…
-
八问八答搞懂Transformer内部运作原理

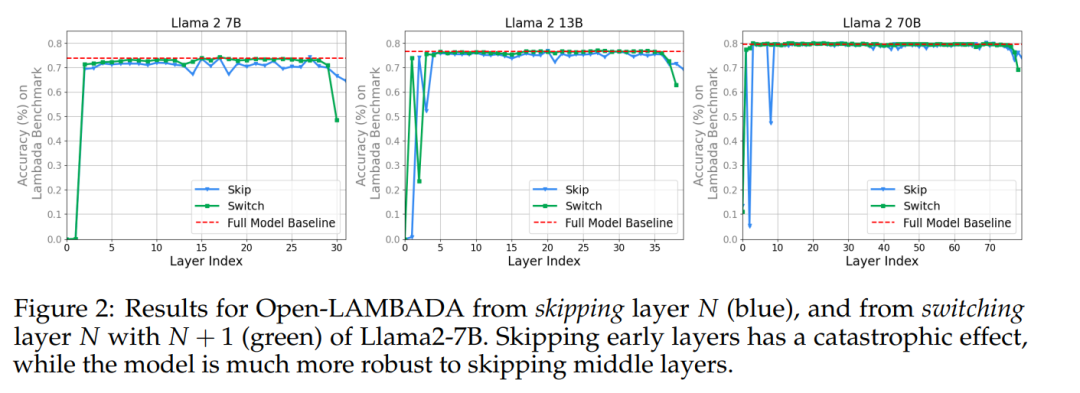
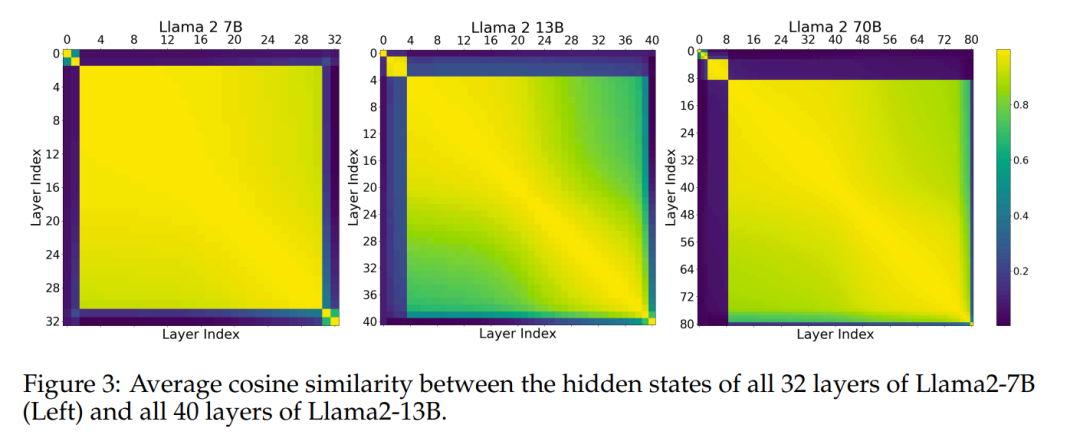
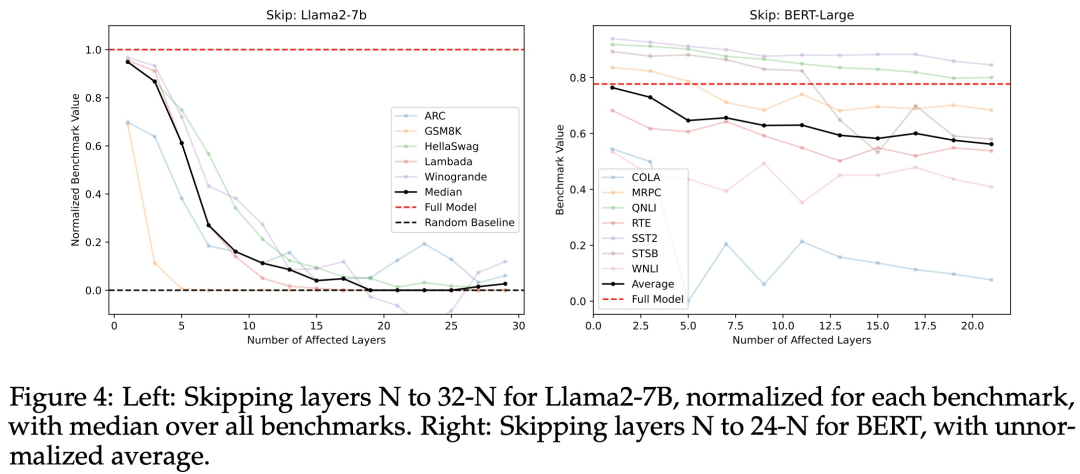
七年前,论文《attention is all you need》提出了 transformer 架构,颠覆了整个深度学习领域。 如今,各家大模型都以 transformer 架构为基础,但 transformer 内部运作原理,仍是一个未解之谜。 去年,transformer 论文作者之一 Lli…
-
刚刚,开源大模型的新王诞生了:超越GPT-4o,模型还能自动纠错
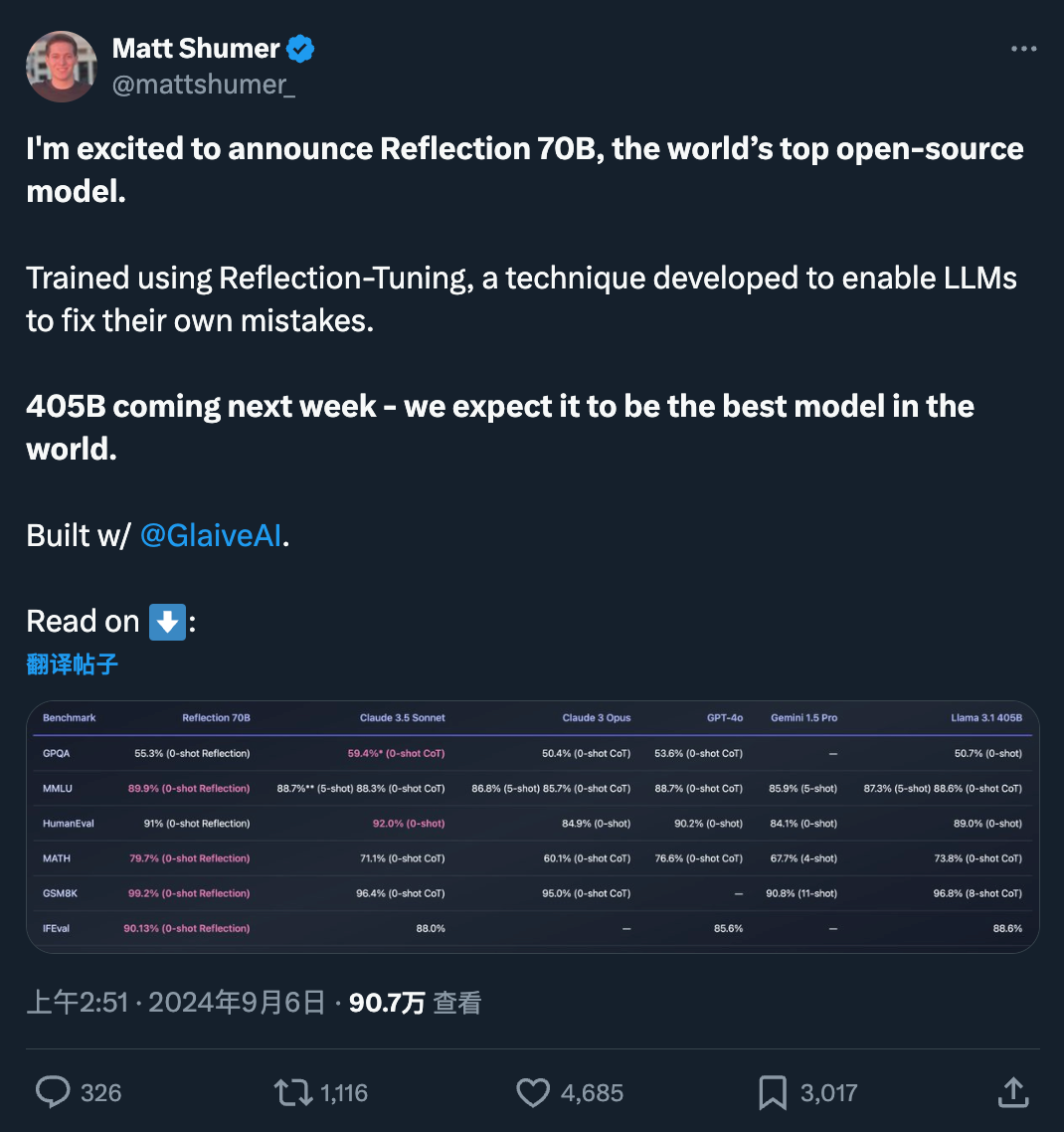
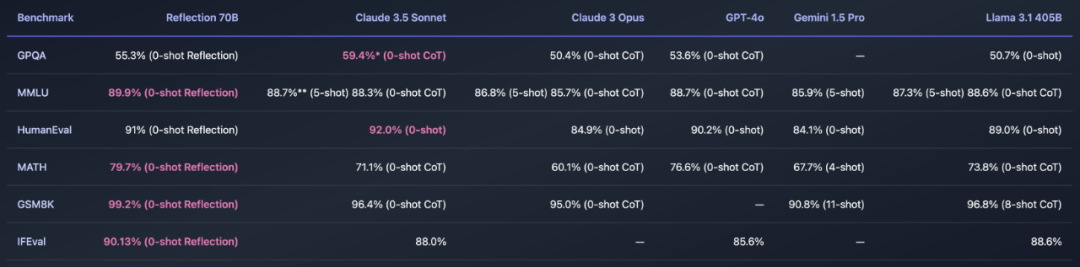

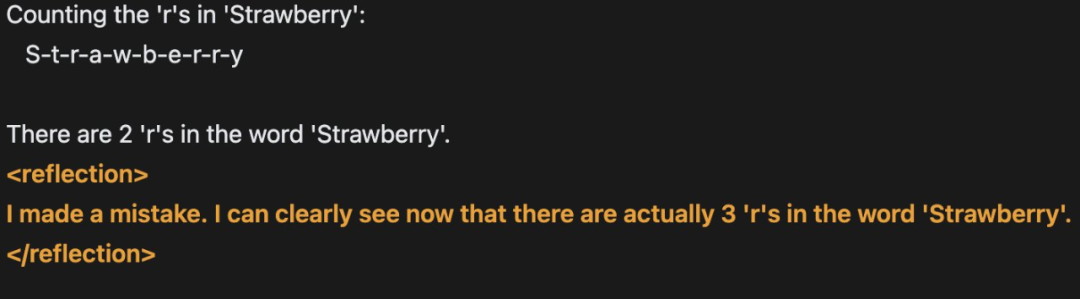
快速更迭的开源大模型领域,又出现了新王:Reflection 70B。 横扫 MMLU、MATH、IFEval、GSM8K,在每项基准测试上都超过了 GPT-4o,还击败了 405B 的 Llama 3.1。 这个新模型 Reflection 70B,来自 AI 写作初创公司 HyperWrite。…
-
Mistral首个多模态模型Pixtral 12B来了!还是直接放出24GB磁力链接
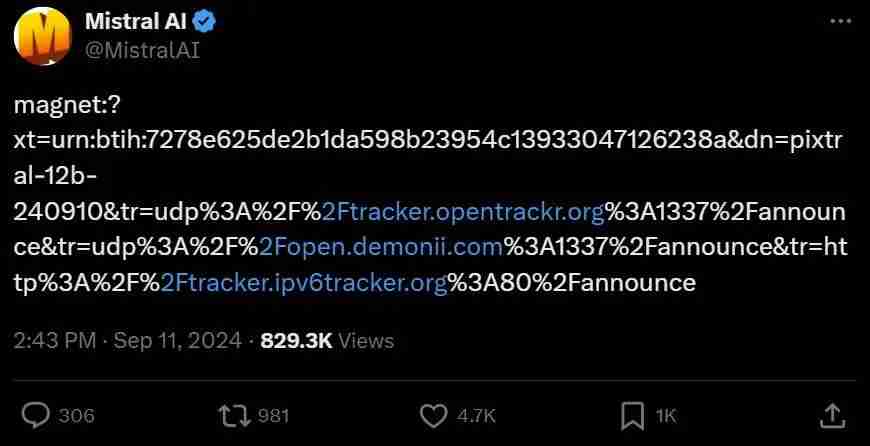
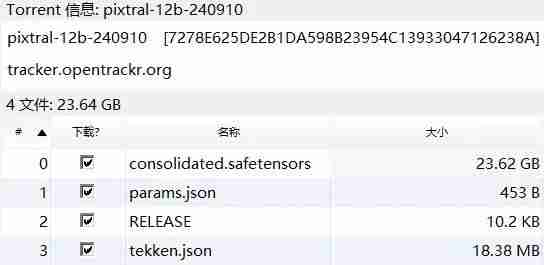

训练完就直接上模型。 我们都知道,Mistral 团队向来「人狠话不多」。昨天下午,他们又又又丢出了一个不带任何注解的磁力链接。 ☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜ 解析一下这个链接,可以看到大小共 23.64 GB,其中包含 4…
-
刚刚,Llama 3.2 来了!支持图像推理,还有可在手机上运行的版本

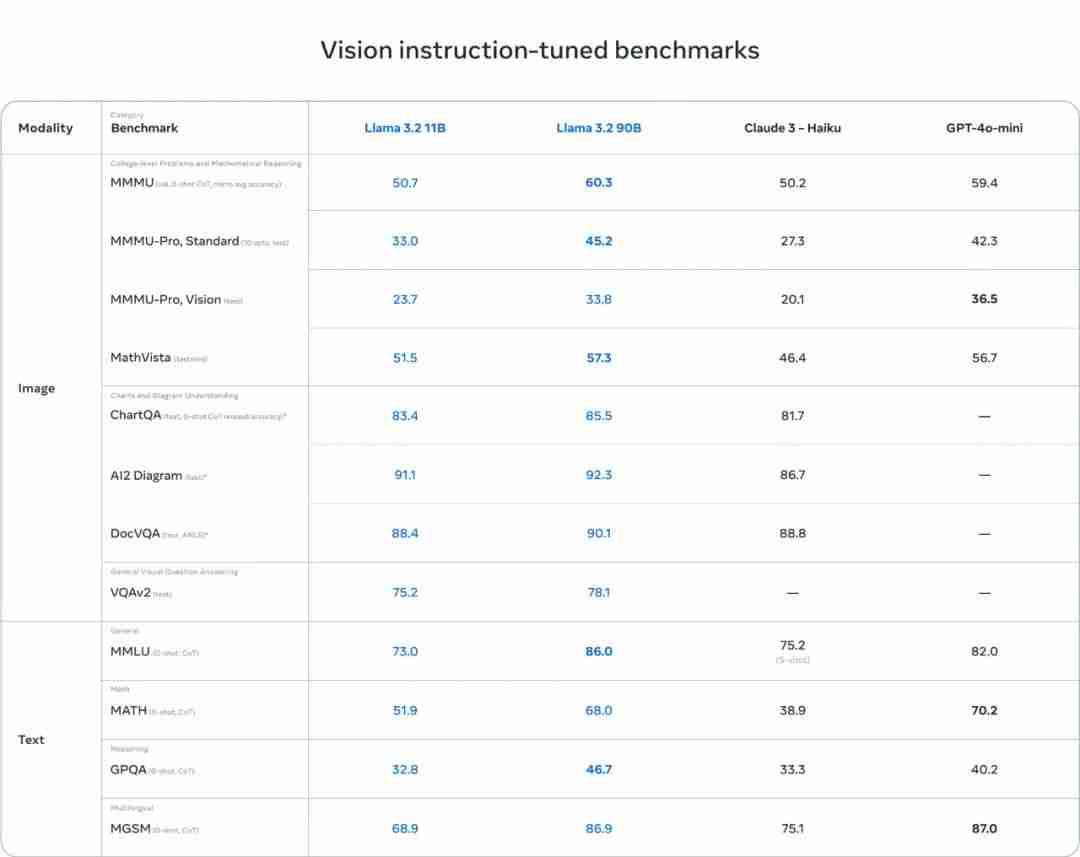
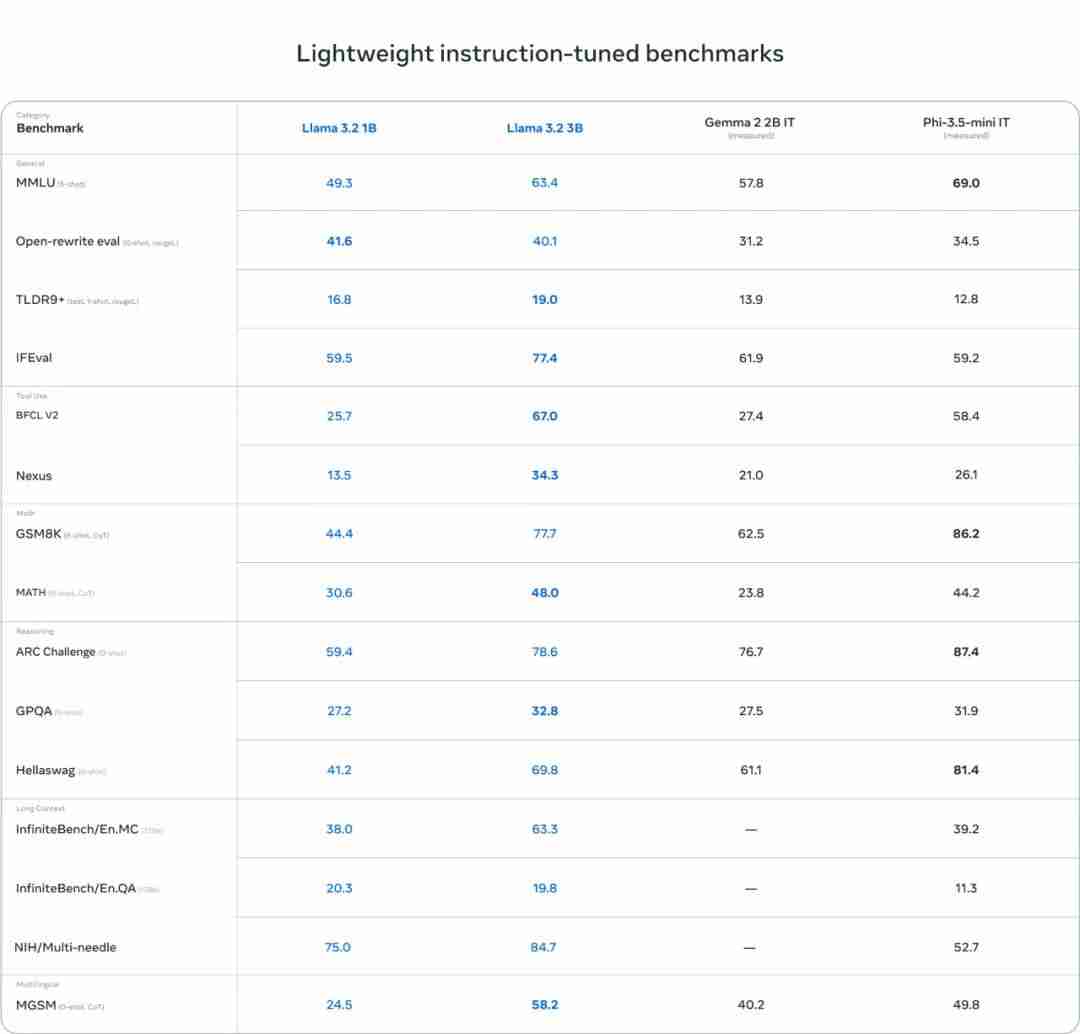
今天凌晨,大新闻不断。一边是 OpenAI 的高层又又又动荡了,另一边被誉为「真・Open AI」的 Meta 对 Llama 模型来了一波大更新:不仅推出了支持图像推理任务的新一代 Llama 11B 和 90B 模型,还发布了可在边缘和移动设备上的运行的轻量级模型 Llama 3.2 1B 和 …
-
与其造神,不如依靠群体的力量:这家公司走出了一条不同于OpenAI的AGI路线




看过剧版《三体》的读者或许都记得一个名场面:来自三体的智子封锁了人类科技,还向地球人发出了「你们是虫子」的宣告。但没有超能力的普通人史强却在蝗群漫天飞舞的麦田中喊出:「把我们人类看成是虫子的三体人,他们似乎忘了一个事实,那就是虫子从来就没有被真正地战胜过」。 ☞☞☞AI 智能聊天, 问答助手, AI…
-
又快又准,即插即用!清华8比特量化Attention,两倍加速于FlashAttention2,各端到端任务均不掉点!




☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜ AIxiv专栏是本站发布学术、技术内容的栏目。过去数年,本站AIxiv专栏接收报道了2000多篇内容,覆盖全球各大高校与企业的顶级实验室,有效促进了学术交流与传播。如果您有优秀的工作想要分享,欢…
-
吴恩达出手,开源最新Python包,一个接口调用OpenAI等模型


在构建应用程序时,与多个提供商集成很麻烦,现在 aisuite 给解决了。 用相同的代码方式调用 OpenAI、Anthropic、Google 等发布的大模型,还能实现便捷的模型切换和对比测试。 刚刚,AI 著名学者、斯坦福大学教授吴恩达最新开源项目实现了。 ☞☞☞AI 智能聊天, 问答助手, A…

