
llama
-
引入国产开源MoE大模型,其性能媲美Llama 2-7B,同时计算量减少了60%
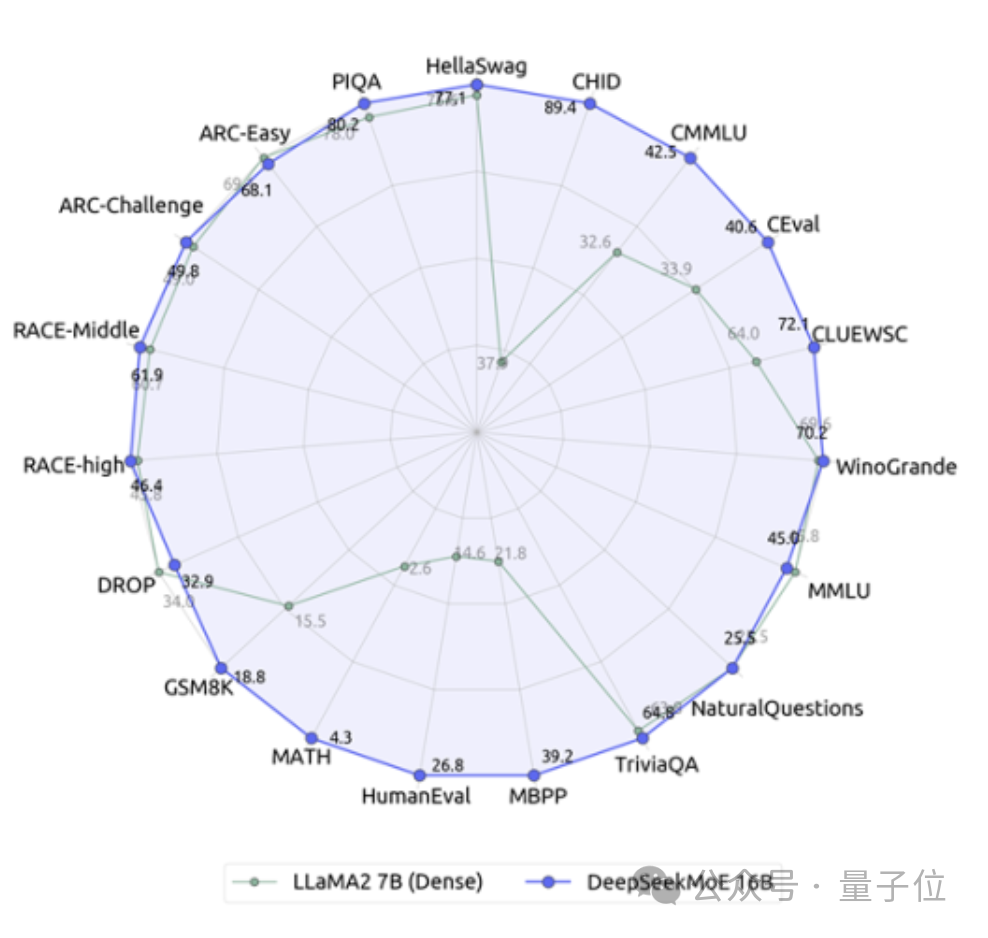
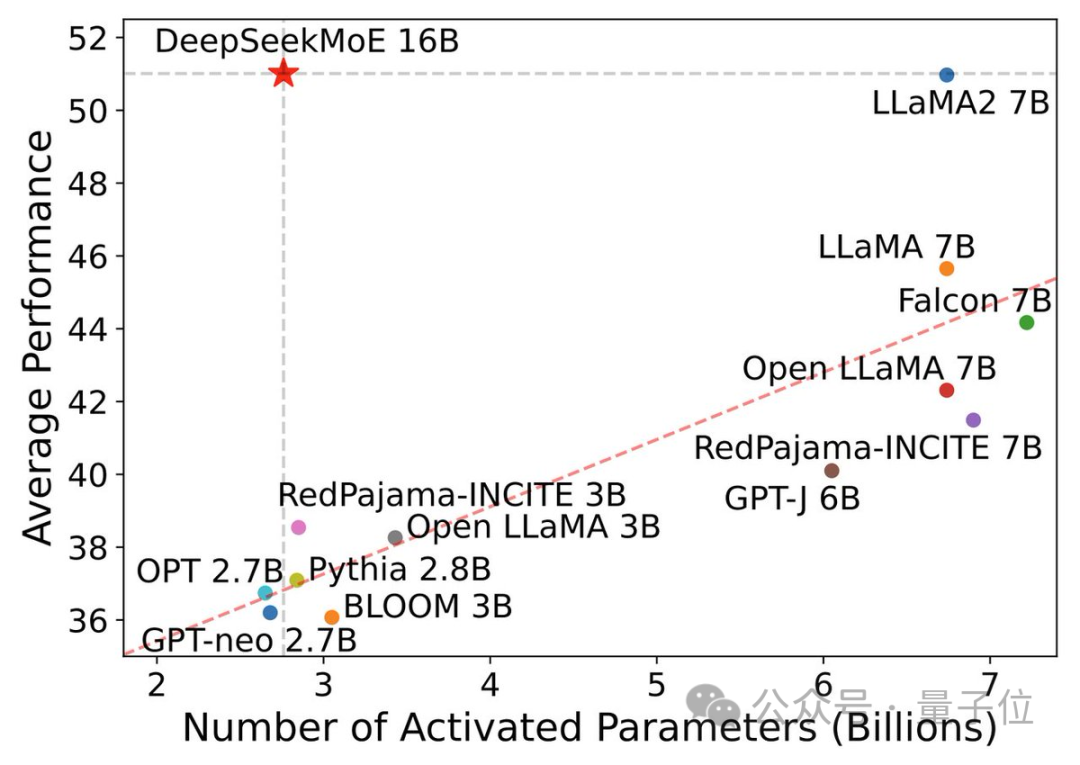
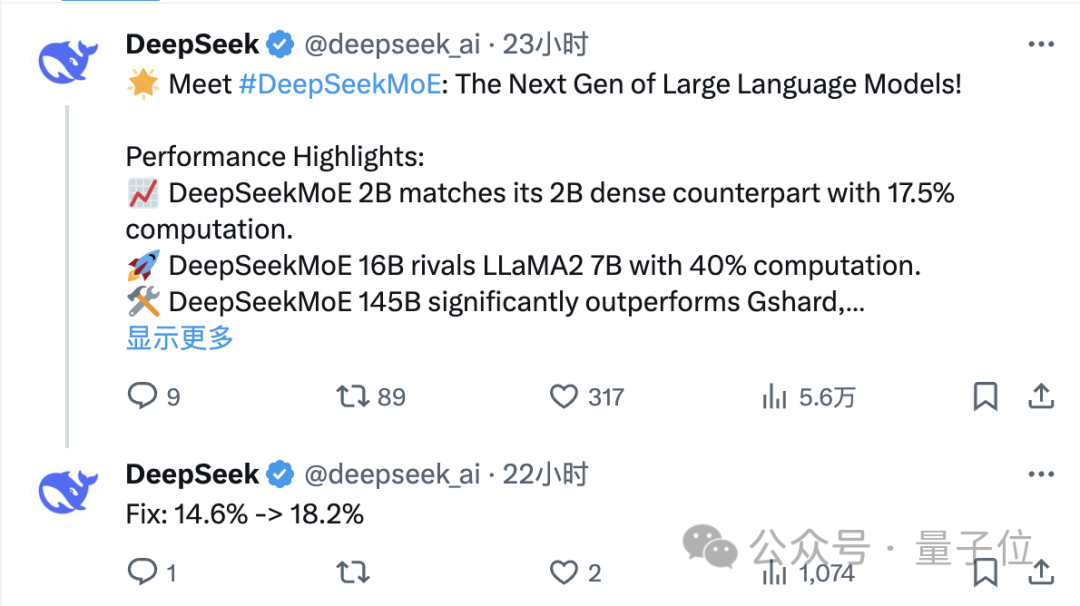
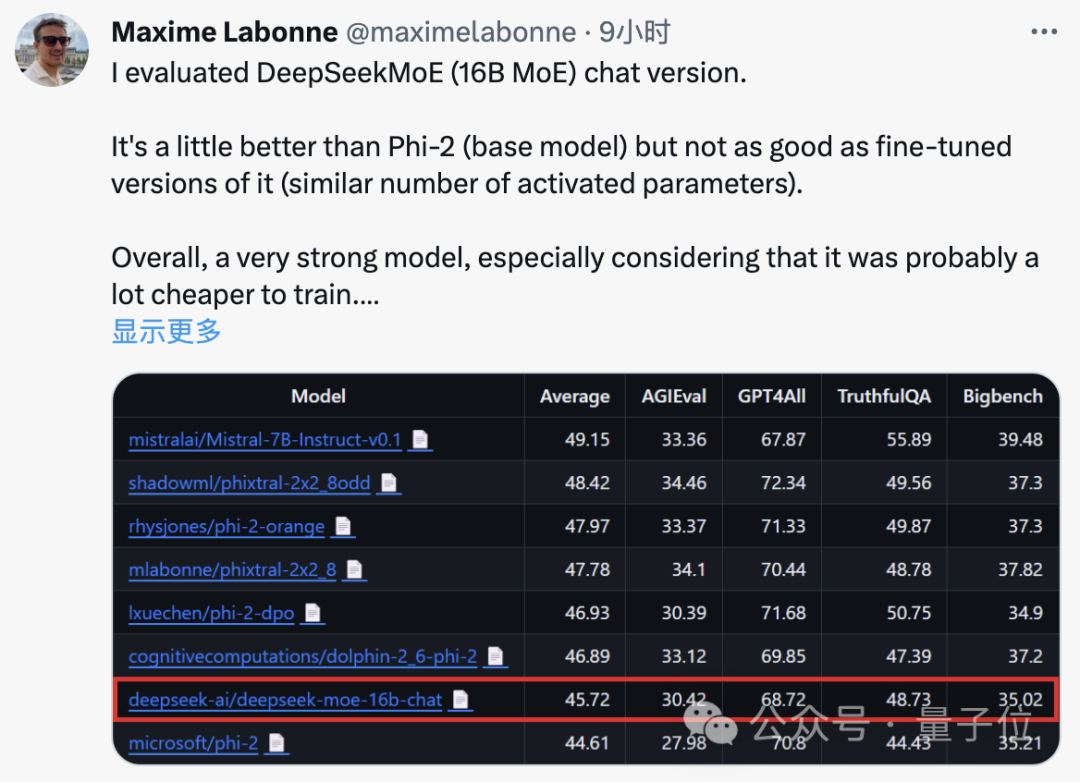
开源moe模型,终于迎来首位国产选手! 它的表现完全不输给密集的Llama 2-7B模型,计算量却仅有40%。 这个模型堪称19边形战士,特别是在数学和代码能力上对Llama形成了碾压。 ☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜ 它就是…
-
侯震宇宣布百度推出多款AI原生云产品,正致力于重塑云计算中的大模型技术




☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜ 在2023年的百度云智大会·智算大会上,百度一次性发布了ai异构计算平台“百舸3.0”、智算网络平台以及自研的云原生数据库gaiadb 4.0等新产品 其中,百舸3.0已经对AI原生应用以及大型…
-
位置编码在Transformer中的应用:探究长度外推的无限可能性
在自然语言处理领域,Transformer 模型因其卓越的序列建模性能而备受关注。然而,由于其训练时限制了上下文长度,使得它及其基于此的大语言模型都无法有效地处理超过此长度限制的序列,这被称作“有效长度外推”能力的缺失。这导致大型语言模型在处理长文本时表现较差,甚至会出现无法处理的情况。为了解决这个…
-
上交大发布推理引擎PowerInfer,其token生成速率仅比A100低18%,或将取代4090成为A100的替代品

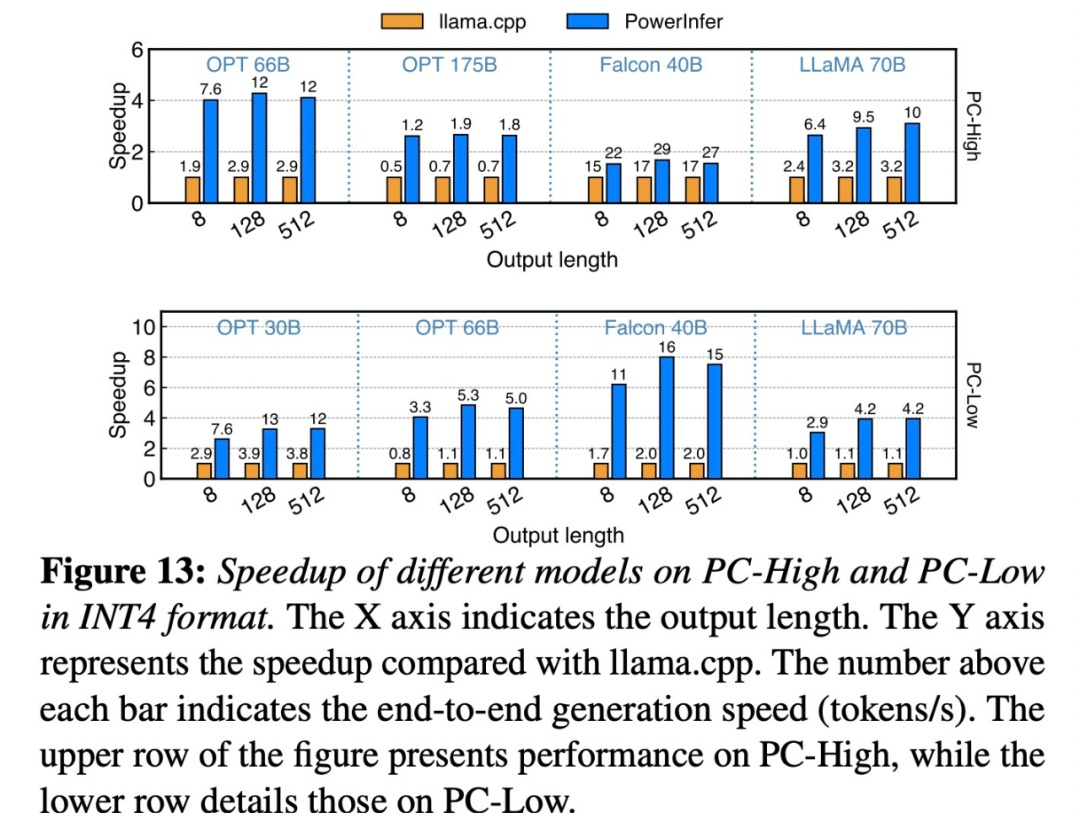
为了不改变原意而重写内容,需要将语言重写为中文,不需要出现原句 本网站的编辑部 PowerInfer 的出现使得在消费级硬件上运行 AI 变得更加高效 上海交大团队,刚刚推出超强 CPU/GPU LLM 高速推理引擎 PowerInfer。 ☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费…
-
回顾NeurIPS 2023: 清华ToT推动大型模型成为焦点



近日,作为美国前十的科技博客,Latent Space对于刚刚过去的NeurIPS 2023大会进行了精选回顾总结。 在NeurIPS会议中,共有3586篇论文被接受,其中6篇获奖。虽然这些获奖论文备受关注,但其他论文同样具备出色的质量和潜力。实际上,这些论文甚至可能预示着AI领域的下一个重大突破。…
-
无需人工标注!LLM加持文本嵌入学习:轻松支持100种语言,适配数十万下游任务


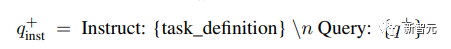
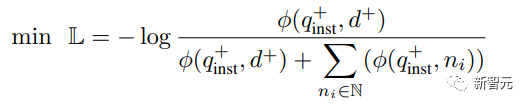
文本嵌入(word embedding)是自然语言处理(NLP)领域的基础技术,它能够将文本映射到语义空间,并转化为稠密的矢量表示。这种方法已经被广泛应用于各种NLP任务,包括信息检索(IR)、问答、文本相似度计算和推荐系统等。通过文本嵌入,我们可以更好地理解文本的含义和关系,从而提高NLP任务的效…
-
Meta官方的Prompt工程指南:Llama 2这样用更高效



随着大型语言模型(LLM)技术日渐成熟,提示工程(Prompt Engineering)变得越来越重要。一些研究机构发布了 LLM 提示工程指南,包括微软、OpenAI 等等。 最近,Meta 提供了一份交互式提示工程指南,专门针对他们的 Llama 2 开源模型。这份指南涵盖了使用 Llama 2…
-
小扎官宣Code Llama重量级更新,新增70B版本,但还有能力限制
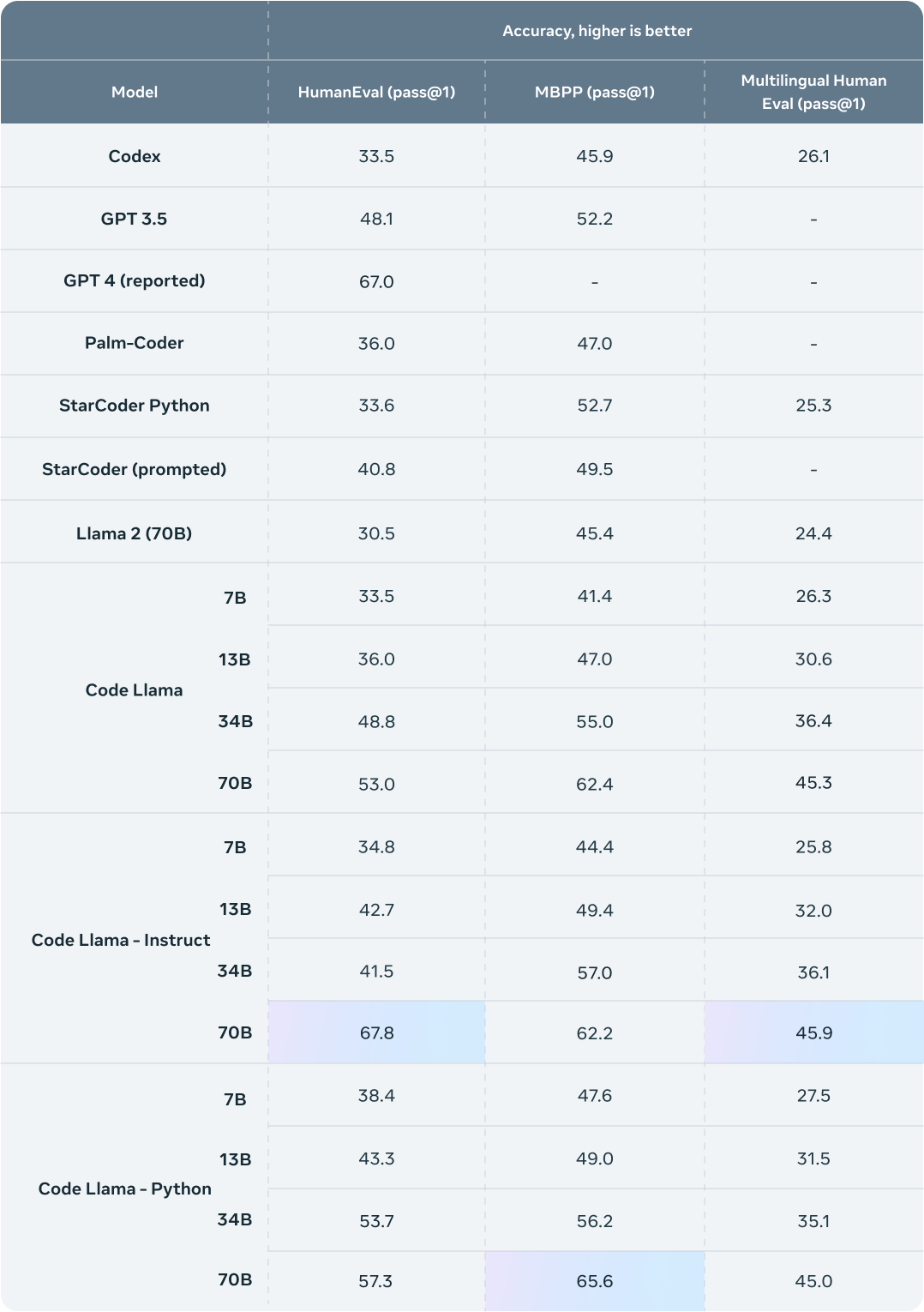
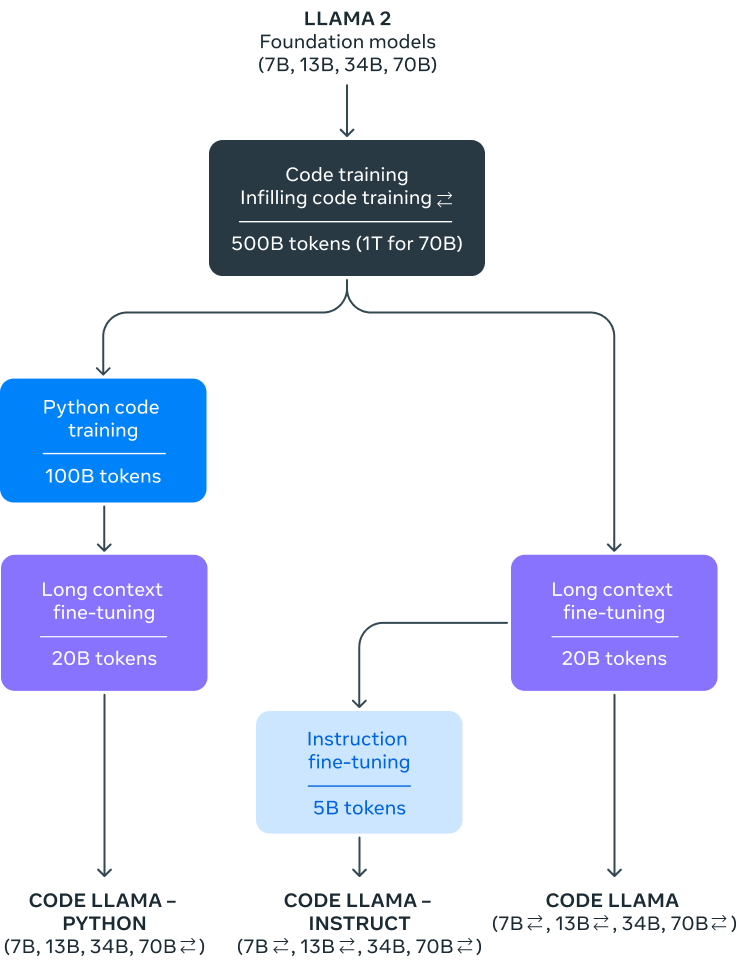

功能更强大的 Code Llama 70B 模型来了。 今天,Meta 正式发布 Code Llama 70B,这是 Code Llama 系列有史以来最大、性能最好的型号。 ☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜ 我们正在开源一个改…
-
Mistral-Medium意外泄露?冲上榜单的这个神秘模型让AI社区讨论爆了
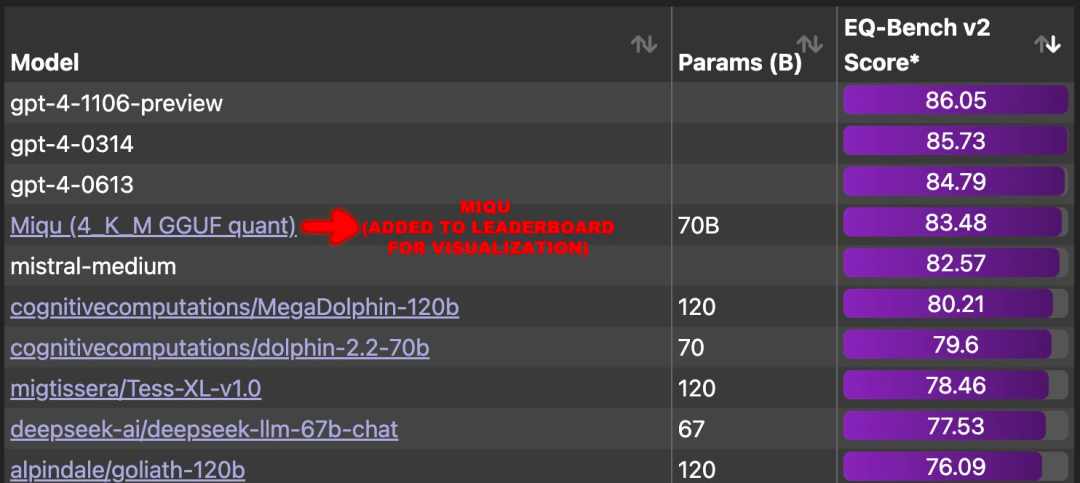
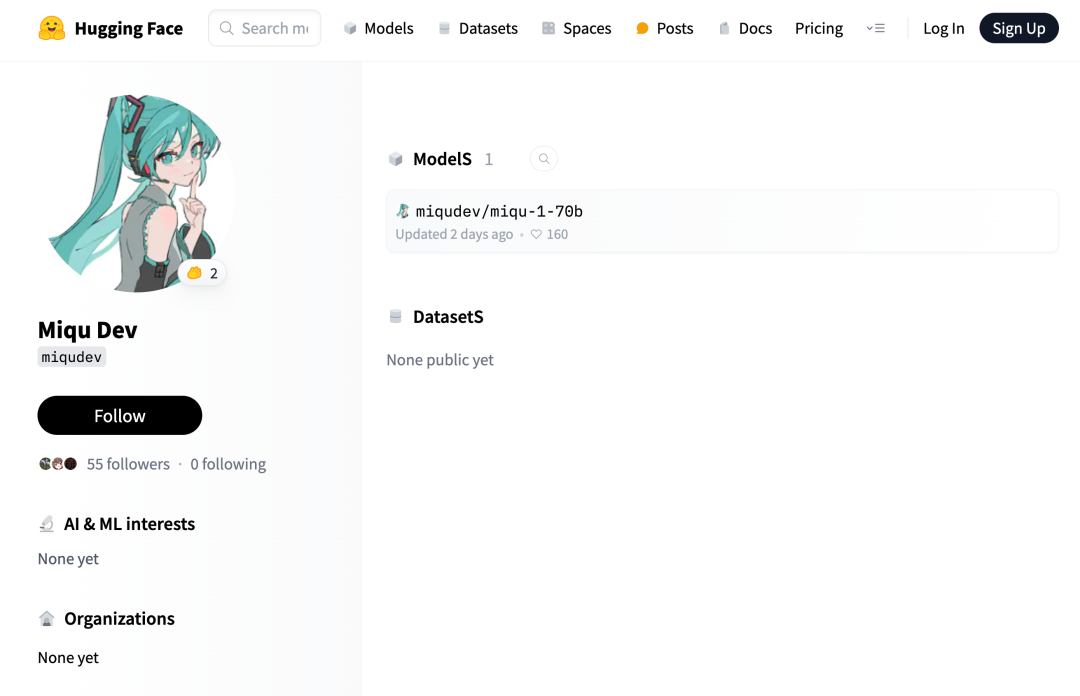
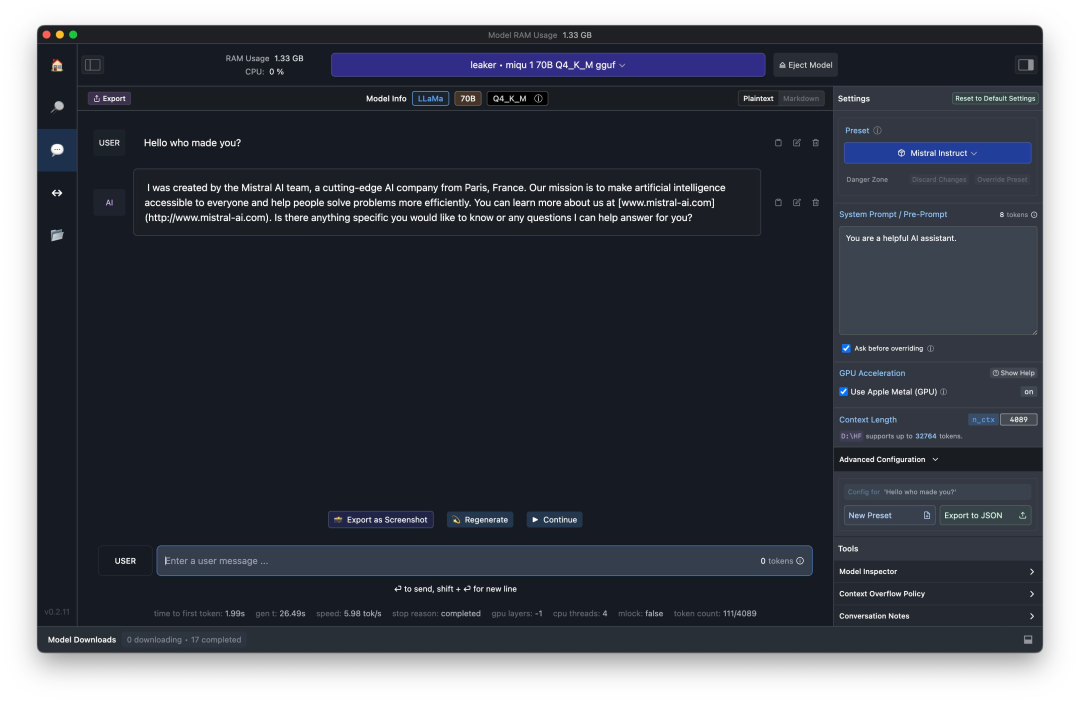
「我现在 100% 确信 miqu 与 perplexity labs 上的 mistral-medium 是同一个模型。」 近日,一则关于「Mistral-Medium 模型泄露」的消息引起了大家的关注。 据传闻,有关一个名为「Miqu」的新模型的泄露消息与评估语言模型情商的基准EQ-Bench有…
-
揭秘NVIDIA大模型推理框架:TensorRT-LLM




一、TensorRT-LLM 的产品定位 TensorRT-LLM是NVIDIA为大型语言模型(LLM)开发的可扩展推理方案。它基于TensorRT深度学习编译框架构建、编译和执行计算图,并借鉴了FastTransformer中高效的Kernels实现。此外,它还利用NCCL实现设备间的通信。开发者…

