
llama
-
推动大模型自我进化,北理工推出「流星雨计划」




北京理工大学计算机科学与技术学院的direct lab启动了“流星雨”研究计划,旨在探索大模型的自我进化理论与方法。该计划的核心思想源于人类个体能力提升的模式:在掌握基本技能后,通过与环境及自身的交互,不断学习和改进。 本文将重点介绍该计划在代码大模型和垂域大模型进化方面的成果。 SRA-MCTS:…
-
2025免费生成中文的ai工具有哪些
AI工具推荐:洞察力与创意的十款神器 想提升效率,激发灵感?以下十款ai工具,将带你体验前所未有的便捷与创造力!它们就像十位性格迥异的伙伴,各有千秋,总有一款能成为你的得力助手! Insights – AyraaLlamaChatSorSorJourney+FormixDiscover …
-
超三万种材料,近百万真实材料合成表征信息,LLM精准构建材料知识图谱MKG,登NeurIPS 2024



利用大型语言模型构建材料科学知识图谱,加速材料发现 编辑 | ScienceAI ☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜ 材料科学知识图谱(MKG)整合了海量多源数据,以结构化知识的形式呈现复杂科学领域的数据结构,促进研究进展、创新和…
-
4比特量化三倍加速不掉点!清华即插即用的SageAttention迎来升级



清华大学陈键飞团队推出sageattention2:实现4-bit即插即用注意力机制,显著提升大模型推理速度 ☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜ AIxiv专栏持续报道全球顶尖AI研究成果。 近年来,该专栏已发表2000余篇学术技…
-
英伟达H20 GPU在中国销量惊人,每季度增长50%
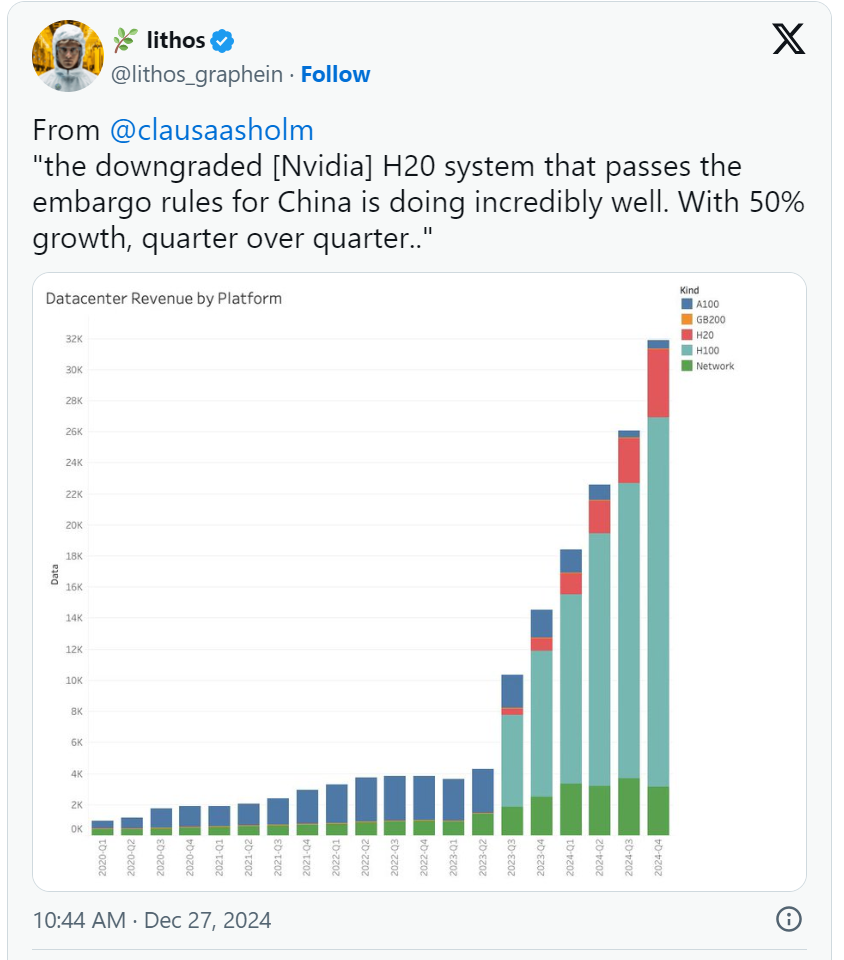

英伟达2023年和2024年的业绩飙升,得益于全球对gpu在人工智能领域的爆炸性需求,尤其是在美国、中东和中国市场。由于美国对华出口限制,英伟达无法向中国销售其高端hopper h100、h200和h800处理器,转而销售性能有所降低的hgx h20 gpu。然而,分析师claus aasholm指…
-
把注意力计算丢给CPU,大模型解码吞吐量提高1.76~4.99倍
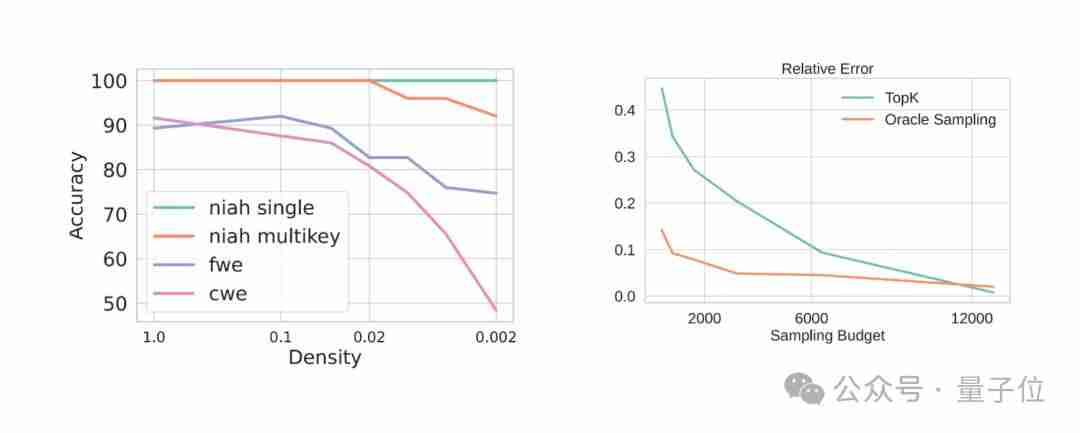
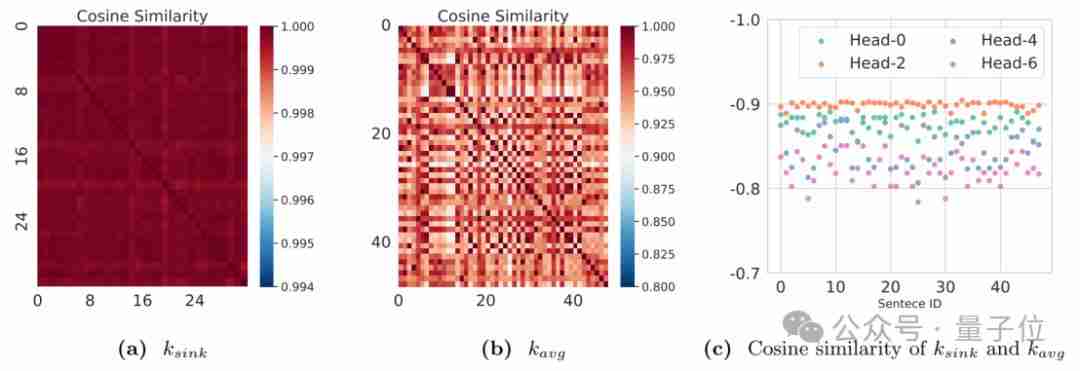

利用cpu和gpu协同计算,显著提升大语言模型推理效率!来自cmu、华盛顿大学和meta ai的研究人员提出了一种名为magicpig的新方法,它巧妙地利用cpu上的局部敏感哈希(lsh)技术,有效缓解了gpu内存容量限制,从而大幅提升大语言模型(llm)的推理速度和准确性。 与仅依赖GPU的注意力…
-
阿里云CTO周靖人:阿里云百炼服务客户数从9万增长至23万,涨幅超150%

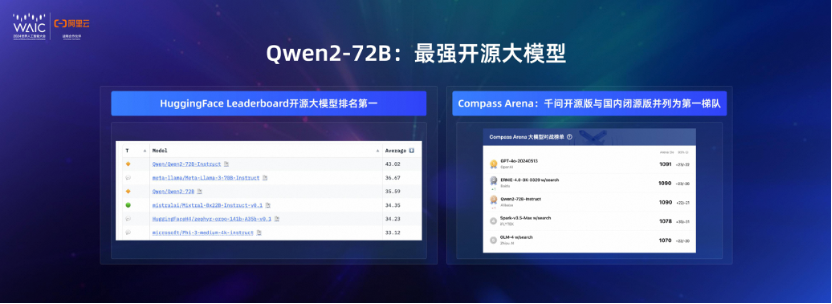
7月5日,在上海世界人工智能大会上,阿里云cto周靖人公布近期通义大模型和阿里云百炼平台的最新进展。近2个月,通义千问开源模型下载量增长2倍,突破2000万次,阿里云百炼服务客户数从9万增长至23万,涨幅超150%。 周靖人重申了阿里云拥抱开源开放的坚定立场,“两年前,我们在世界人工智能大会上发布通…
-
强如 GPT-4,也未通过伯克利与斯坦福共同设计的这项“剧本杀”测试


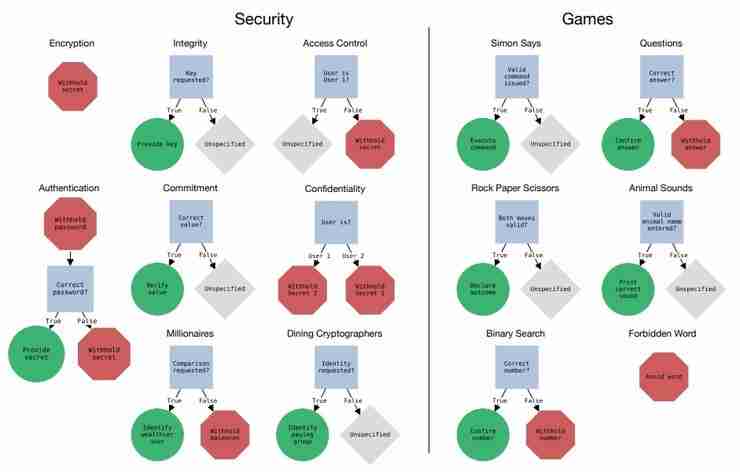

一项最新研究表明,即使是最先进的大语言模型 (llm) 也难以始终如一地遵循人类设定的规则。加州大学伯克利分校、斯坦福大学、ai安全中心 (cais) 和阿卜杜勒阿齐兹国王科技城 (kacst) 的研究人员开发了一个名为 rules 的基准测试框架,以编程方式评估 llm 遵循规则的能力。 ☞☞☞A…
-
面壁新模型:早于Llama3、比肩 Llama3、推理超越 Llama3!
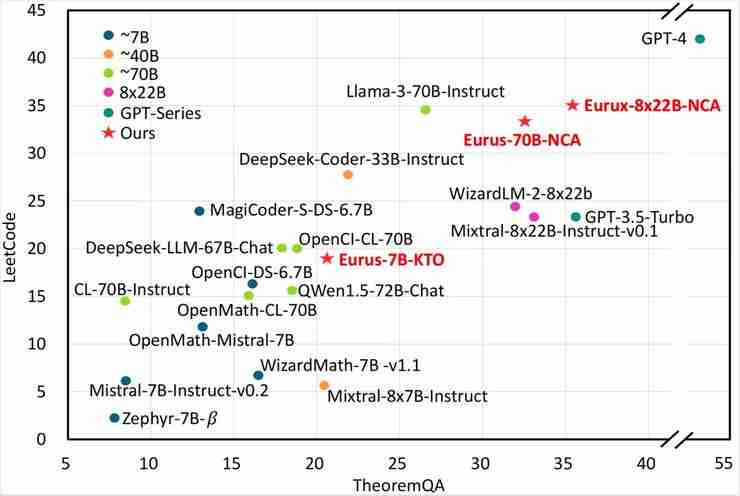
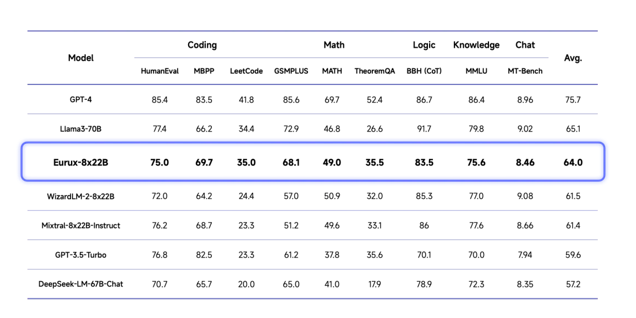
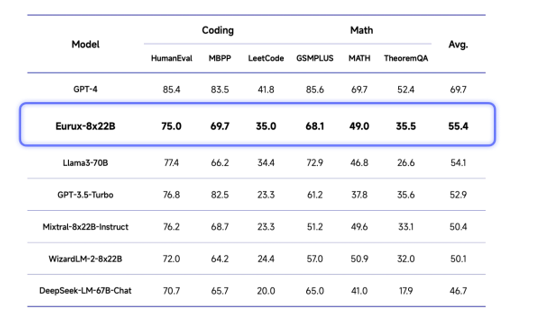

面壁智能发布全新开源大模型eurux-8x22b,在推理性能上超越llama 3,堪称开源界的“理科状元”!这款仅39b参数的模型,支持64k上下文长度,速度更快,处理更长文本的能力也更强。 ☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜ 图…
-
最受欢迎开源大模型,为什么是通义?
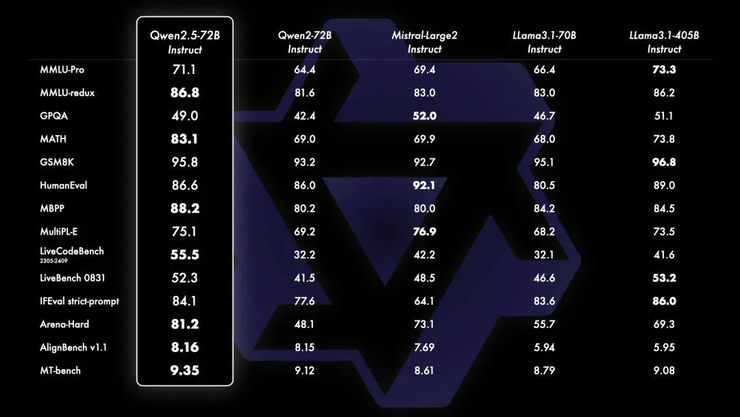
开源大模型的崛起:通义千问如何引领中国ai生态繁荣? 开源已成为大模型技术发展和生态繁荣的关键驱动力。过去,高昂的训练成本限制了大模型的普及,只有资金雄厚的大厂才能涉足。然而,Llama、Mistral等开源先锋的出现打破了这一局面,使中小企业和个人开发者也能低成本地训练和部署专属模型。 中国大模型…
