
llama
-
陈丹琦团队新作:Llama-2上下文扩展至128k,10倍吞吐量仅需1/6内存
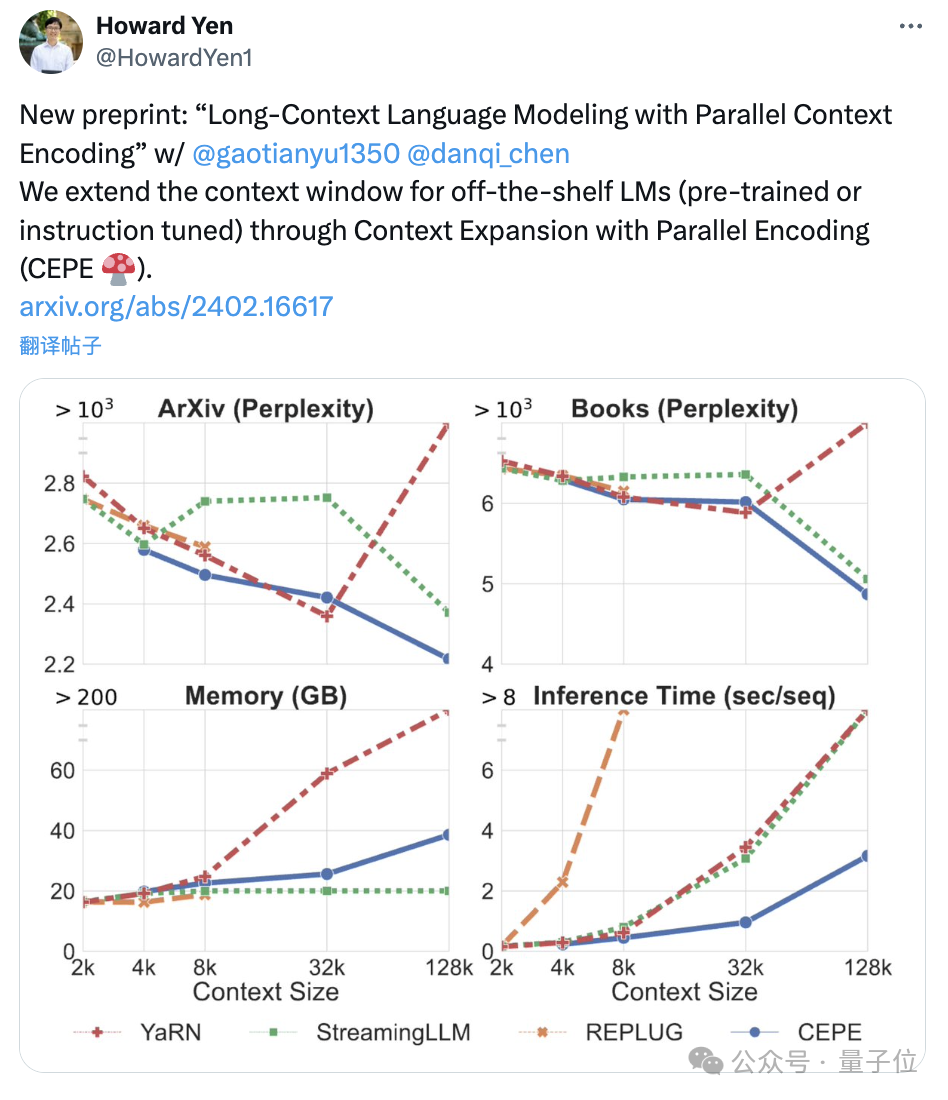
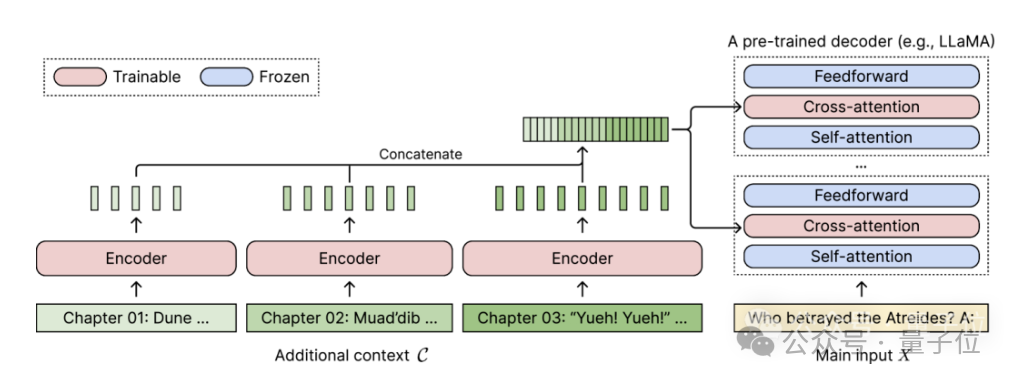

陈丹琦团队刚刚发布了一种新的llm上下文窗口扩展方法: 它仅用8k大小的token文档进行训练,就能将Llama-2窗口扩展至128k。 最重要的是,在这个过程中,只需要原来1/6的内存,模型就获得了10倍吞吐量。 ☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSee…
-
可视化FAISS矢量空间并调整RAG参数提高结果精度

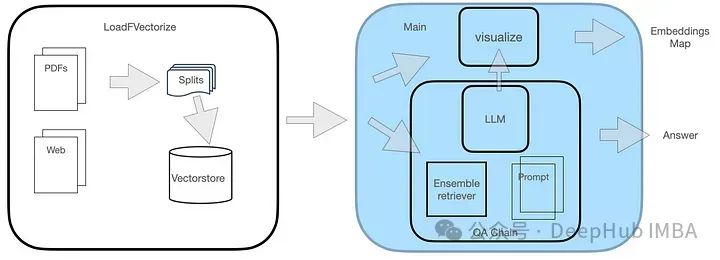


随着开源大型语言模型的性能不断提高,编写和分析代码、推荐、文本摘要和问答(qa)对的性能都有了很大的提高。但是当涉及到qa时,llm通常会在未训练数据的相关的问题上有所欠缺,很多内部文件都保存在公司内部,以确保合规性、商业秘密或隐私。当查询这些文件时,会使得llm产生幻觉,产生不相关、捏造或不一致的…
-
吞吐量提升5倍,联合设计后端系统和前端语言的LLM接口来了
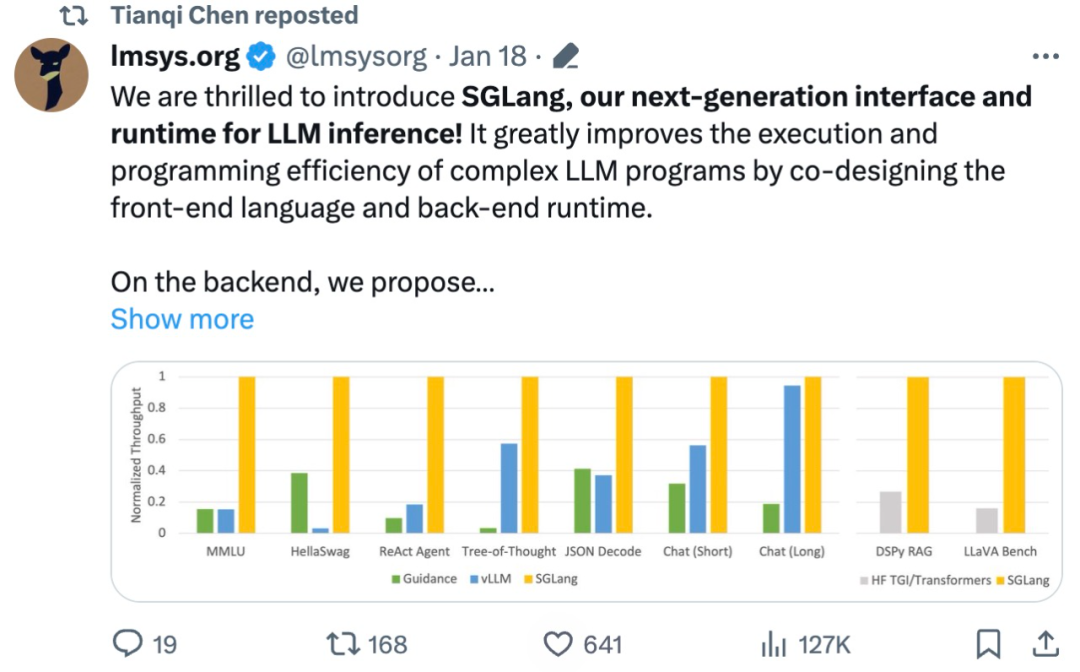

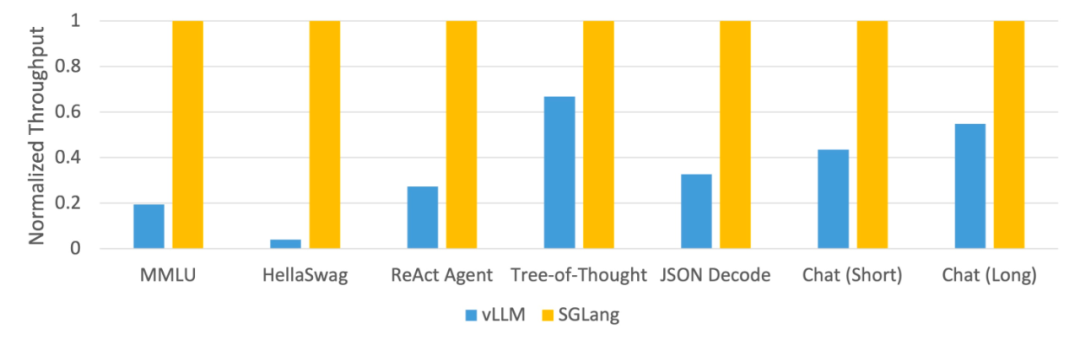
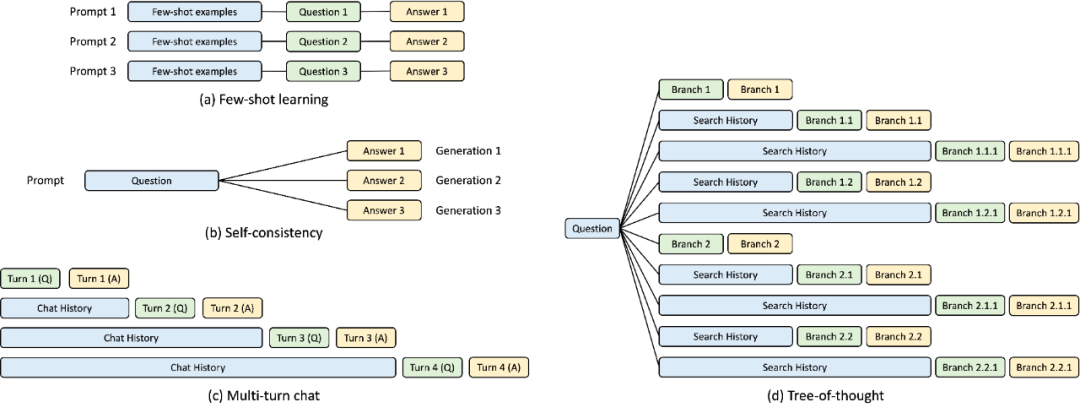
大型语言模型 (llm) 被广泛应用于需要多个链式生成调用、高级提示技术、控制流以及与外部环境交互的复杂任务。尽管如此,目前用于编程和执行这些应用程序的高效系统却存在明显的不足之处。 研究人员最近提出了一种新的结构化生成语言(Structured Generation Language),称为SGL…
-
用AI短视频「反哺」长视频理解,腾讯MovieLLM框架瞄准电影级连续帧生成


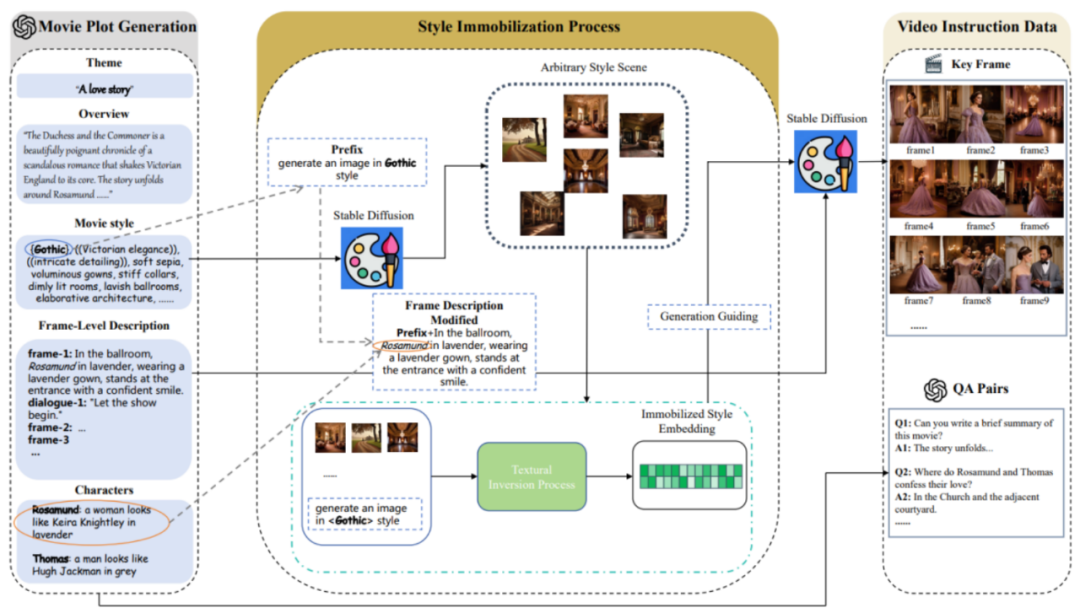

在视频理解这一领域,尽管多模态模型在短视频分析上取得了突破性进展,展现出了较强的理解能力,但当它们面对电影级别的长视频时,却显得力不从心。因而,长视频的分析与理解,特别是对于长达数小时电影内容的理解,成为了当前的一个巨大挑战。 模型在理解长视频方面的困难主要源自于长视频%ignore_a_1%资源的…
-
我们一起聊聊大模型的模型融合方法
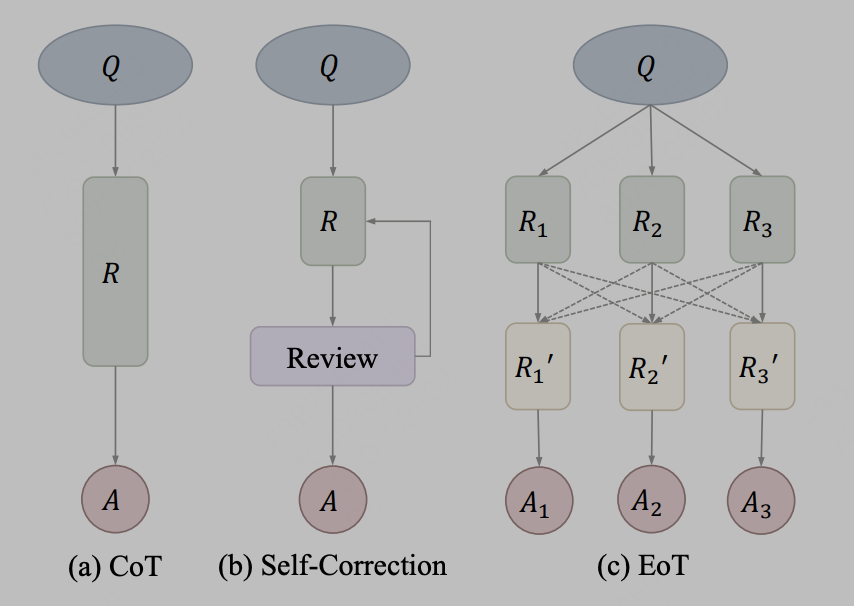

在以前的实践中,模型融合被广泛运用,尤其在判别模型中,它被认为是一种能够稳定提升性能的方法。然而,对于生成语言模型而言,由于其涉及解码过程,其运作方式并不像判别模型那样直截了当。 另外,由于大模型的参数量增大,在参数规模更大的场景,简单的集成学习可以考量的方法相比低参数的机器学习更受限制,比如经典的…
-
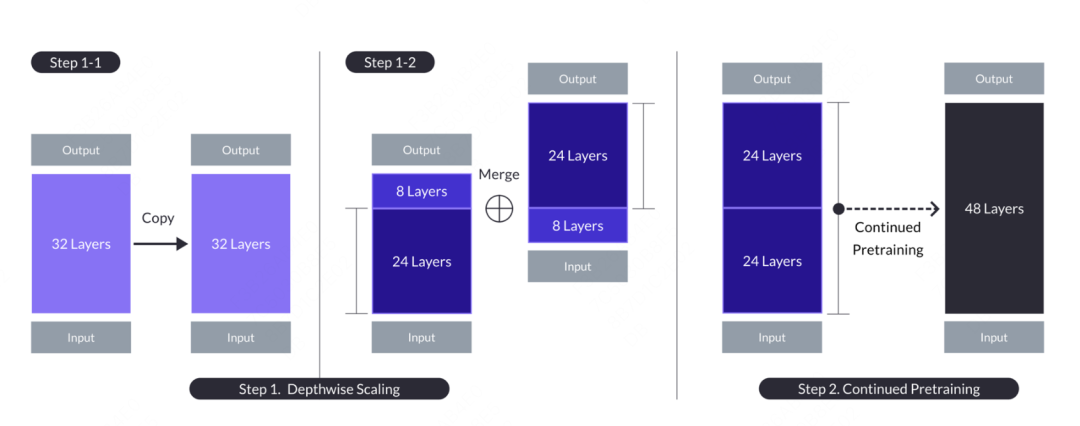
Mamba超强进化体一举颠覆Transformer!单张A100跑140K上下文

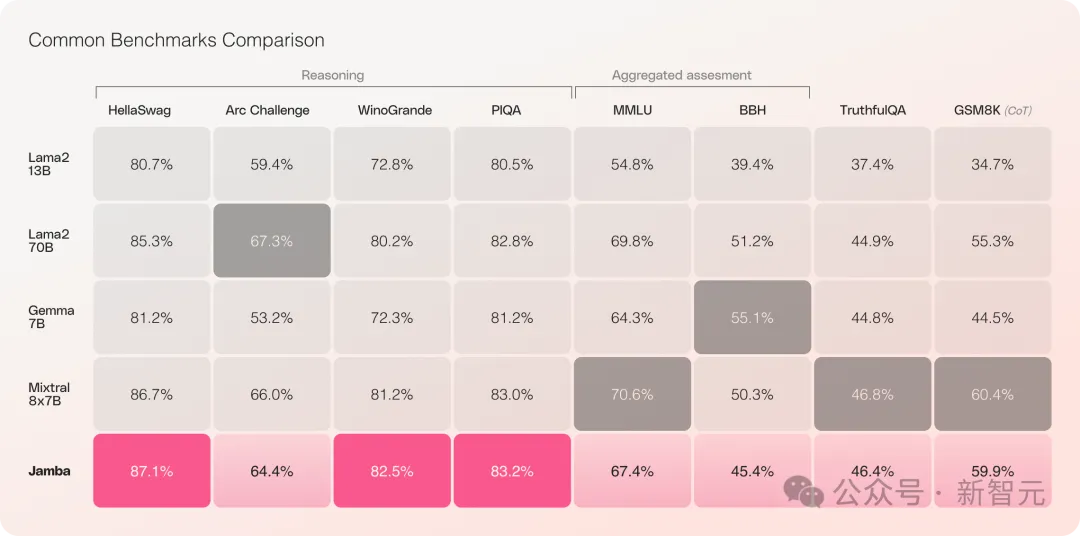

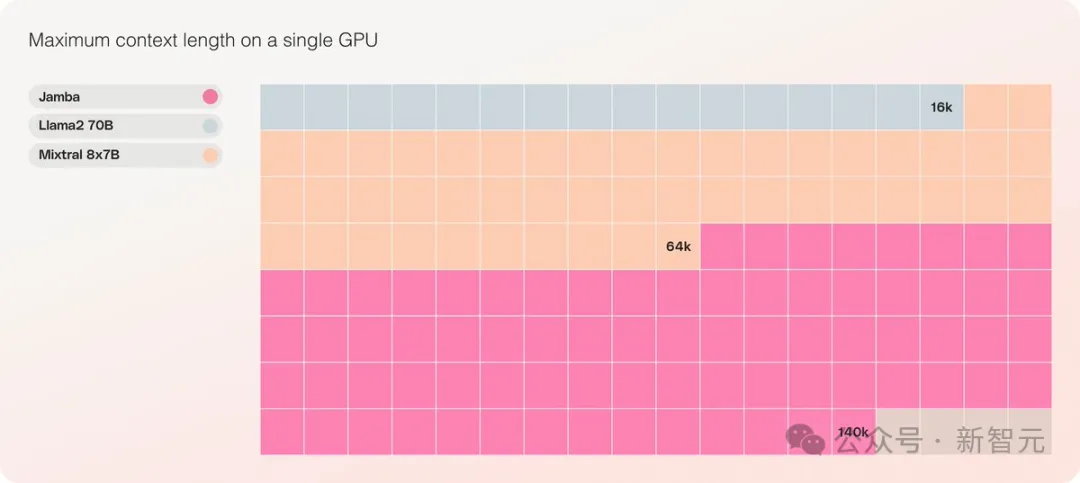
之前引爆了AI圈的Mamba架构,今天又推出了一版超强变体! 人工智能独角兽AI21 Labs刚刚开源了Jamba,世界上第一个生产级的Mamba大模型! ☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜ Jamba在多项基准测试中表现亮眼,与…
-
大佬出走后首个发布!Stability官宣代码模型Stable Code Instruct 3B



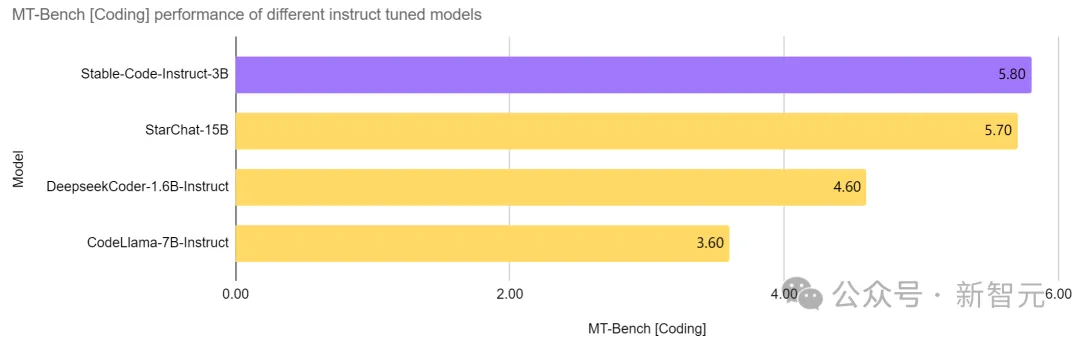
大佬出走后,第一个模型来了! 就在今天,Stability AI官宣了新的代码模型Stable Code Instruct 3B。 ☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜ 图片 Stability是非常重要的,首席执行官离职对Stab…
-
GPT-4单项仅得7.1分,揭露大模型代码能力三大短板,最新基准测试来了




首个ai软件工程师devin正式亮相,立即引爆了整个技术界。 Devin虽然不能够轻松解决编码任务,但可以自主完成软件开发的整个周期——从项目规划到部署。他尽力挖掘,但不限于构建网站、自主寻找并修复BUG、培训和微调AI模型等。 这种 “强到逆天” 的软件开发能力,让一众码农纷纷绝望,直呼:“程序员…
-
0门槛免费商用!孟子3-13B大模型正式开源,万亿token数据训练
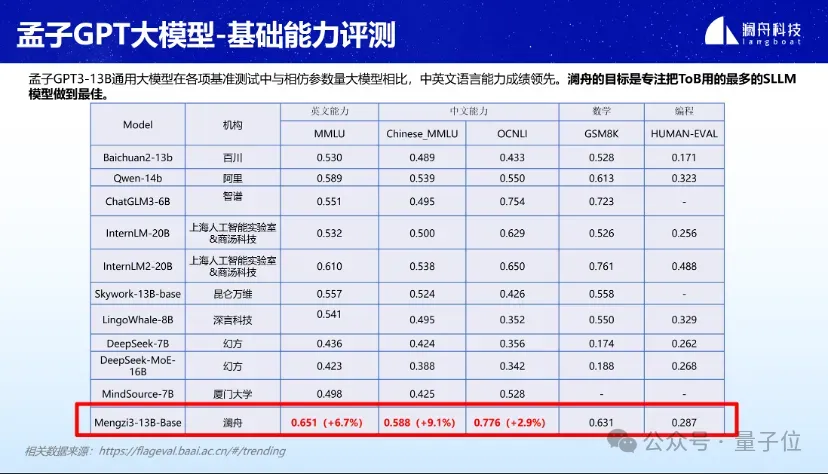

澜舟科技官宣:孟子3-13b大模型正式开源! 这一主打高性价比的轻量化大模型,面向学术研究完全开放,并支持免费商用。 在MMLU、GSM8K、HUMAN-EVAL等各项基准测评估中,孟子3-13B都表现出了不错的性能。 尤其在参量20B以内的轻量化大模型领域,中英文语言能力方面尤为突出。数学和编程能…
-
大语言模型中常用的旋转位置编码RoPE详解:为什么它比绝对或相对位置编码更好?
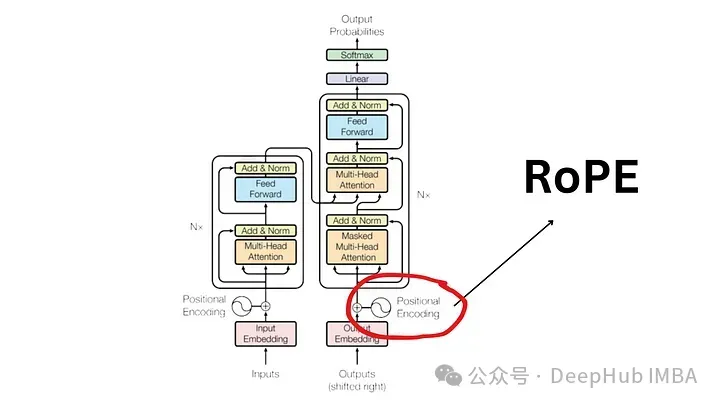
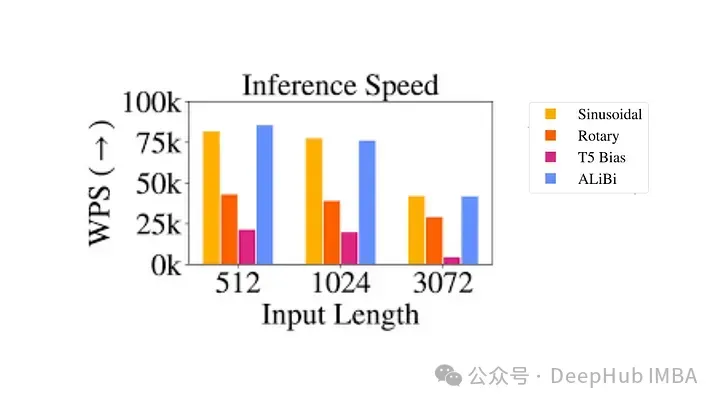

自2017年发表的“attention is all you need”论文以来,transformer架构一直是自然语言处理(nlp)领域的基石。它的设计多年来基本没有变化,随着旋转位置编码(rope)的引入,2022年标志着该领域的重大发展。 旋转位置嵌入是最先进的 NLP 位置嵌入技术。大多数…
