
llms
-
LLM | 偏好学习算法并不学习偏好排序

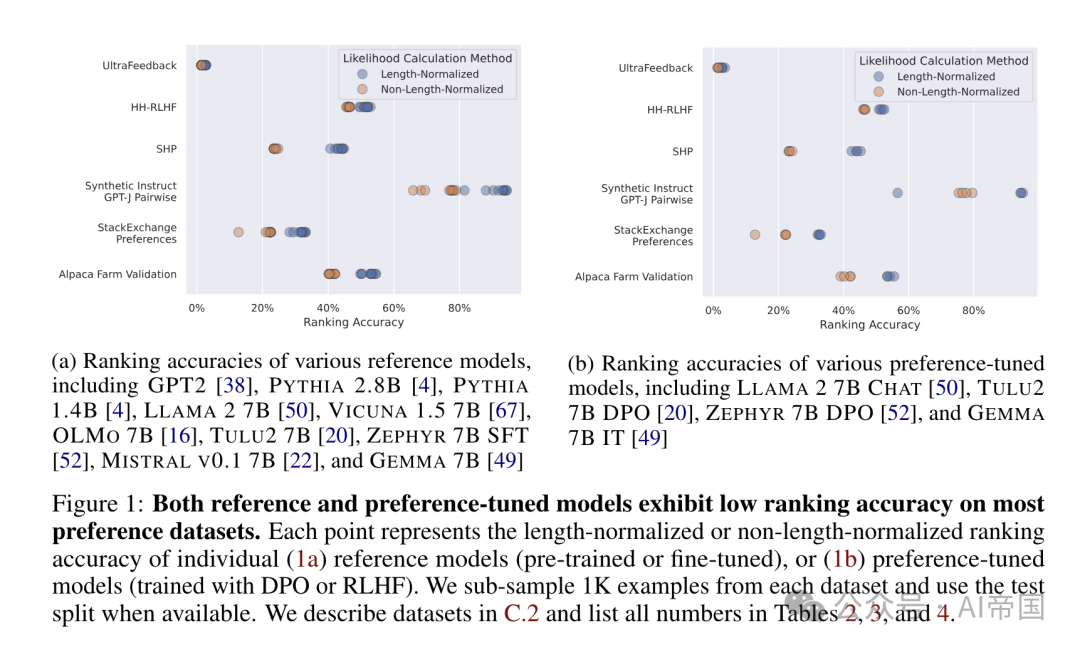

☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜ 图片 一、结论写在前面 偏好学习算法(preference learning algorithms)如rlhf和dpo)常用于引导大型语言模型(llms)生成更符合人类偏好的内容。但是,文献对其…
-
大模型知识Out该怎么办?浙大团队探索大模型参数更新的方法—模型编辑
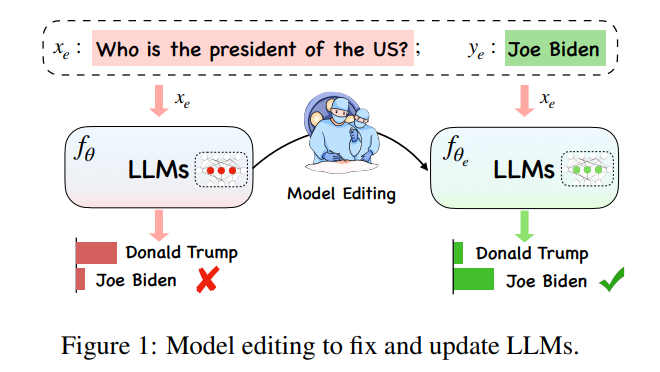

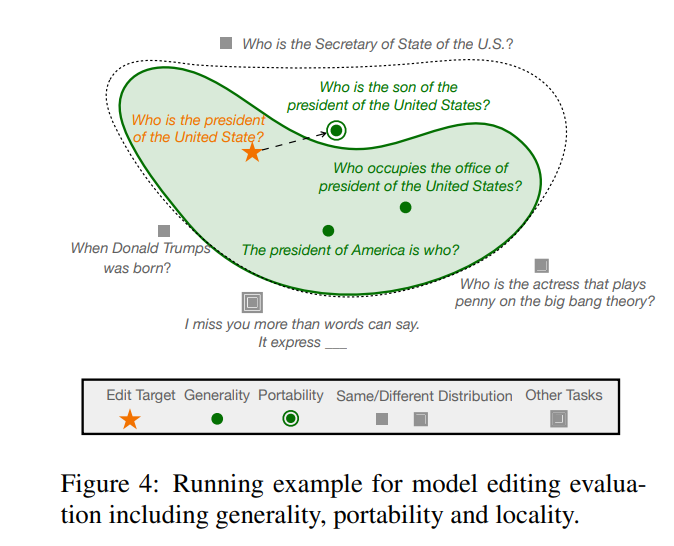

夕小瑶科技说 原创 作者 | 小戏、python 大模型在其巨大体量背后蕴藏着一个直观的问题:“大模型应该怎么更新?” 在大模型极其巨大的计算开销下,大模型知识的更新并不是一件简单的“学习任务”,理想情况下,随着世界各种形势的纷繁复杂的变换,大模型也应该随时随地跟上时代的脚步,但是训练全新大模型的计…
-
一文读懂大型语言模型微调技术挑战与优化策略

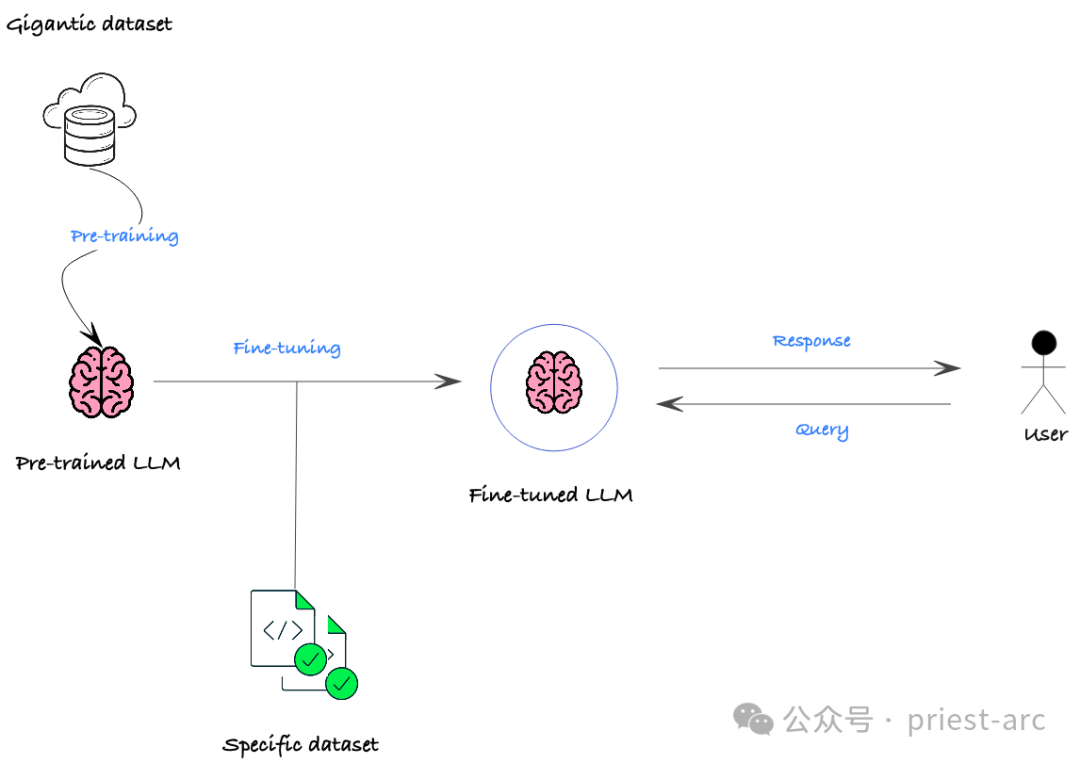


大家好,我是luga。今天我们将继续探讨人工智能生态领域中的技术,特别是llm fine-tuning。本文将继续深入剖析llm fine-tuning技术,帮助大家更好地理解其实现机制,以便更好地应用于市场开发和其他领域。 ☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 De…
-
革新LLM微调之道:全方位解读PyTorch原生库torchtune的创新力量与应用价值



☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜ 在人工智能领域,大语言模型(LLMs)正日益成为研究和应用的新热点。然而,如何高效、精准地对这些庞然大物进行调优,一直是业界和学术界面临的重要挑战。近期,PyTorch官方博客发布了一篇关于To…
