
爬虫
-
Python SQLite3 动态创建子表指南




本教程详细讲解了在 python 中使用 sqlite3 动态创建子表的方法。针对数据抓取等场景中,根据主表记录动态生成关联子表的需求,文章指出了常见的sql语句格式化错误,并提供了正确的表名构建和动态创建子表的实践方法,确保数据库操作的成功与效率,同时探讨了相关的数据库设计考量。 在数据处理和爬虫…
-
Python爬虫怎样使用缓存机制_Python爬虫减少重复请求的缓存策略与实现


使用缓存机制可减少重复请求,提升爬虫效率。1. 文件系统缓存:按URL哈希命名文件,检查本地缓存是否存在且未过期,避免重复请求;2. HTTP条件请求:利用ETag和Last-Modified头发送If-None-Match或If-Modified-Since实现304响应复用;3. request…
-
mysql异常值如何监控_mysql指标告警体系


首先明确关键监控指标,包括连接数、慢查询、缓冲池命中率、TPS/QPS、主从延迟及锁等待;其次采用静态阈值、动态基线、同比环比和趋势预测等方法识别异常;最后通过Prometheus+Grafana或Zabbix搭建可视化告警体系,设置分级告警与抑制规则,并结合日志分析定位根因,定期优化策略以减少误报…
-
win7中文语言包怎么用

通过以下步骤可安装 Windows 7 中文语言包:从微软官方网站下载。运行安装程序并重启计算机。设置语言为中文(控制面板 > 时钟、语言和区域 > 语言)。应用语言并再次重启计算机。完成后,Windows 7 系统将以中文界面显示。 如何安装 Windows 7 中文语言包 步骤: 下…
-
php curl如何采集号码

使用 PHP cURL 采集号码的步骤:设置 cURL 会话,指定目标 URL。设置 HTTP 标头,包括 Host、User-Agent 和 Referer。启用 COOKIE,指定 COOKIEJAR 和 COOKIEFILE。获取响应,并解析响应以提取号码(例如,使用正则表达式)。 PHP c…
-
许多主要新闻媒体正屏蔽 OpenAI 爬虫
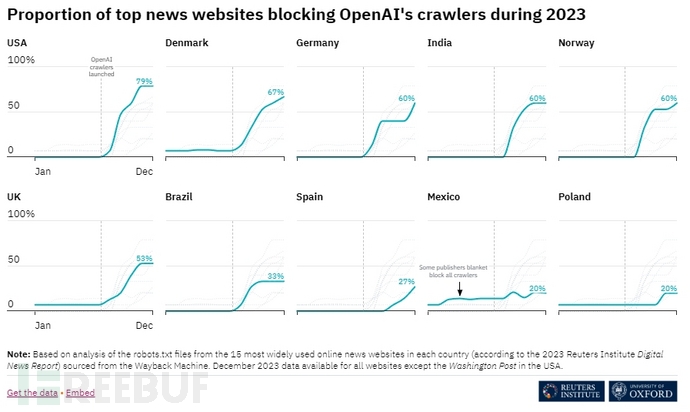

自%ign%ignore_a_1%re_a_1%推出内容生成式人工智能模型以来,网络上的数据被广泛应用于训练和改进这些模型。然而,根据路透社研究所的调查显示,越来越多的新闻媒体开始对openai的数据采集表示疑虑,甚至有超过50%的传统媒体对此持反对态度。这表明对数据隐私和使用的关注正在增加,并提醒…
-
DeepSeek提示词终极秘籍:无招胜有招的极简哲学


在ai技术飞速发展的当下,deepseek作为新一代大模型正在重新定义内容创作的方式。当人们讨论“提示词技巧”时,大多数教程都会强调参数调节、魔法关键词、复杂句式结构等所谓的“高阶秘籍”。然而,在与数万名用户的真实交互中,我们得出了一个出人意料的结论:最有效的提示词,往往是那些最自然、最贴近日常对话…
-
深入理解 Nginx 限流:背景、原理、能力边界与实战示例


☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜ 在现代互联网系统中,“限流”已经是一个绕不开的话题。随着用户规模增长、业务场景复杂化、恶意流量与突发流量不断出现,限流成为保障系统稳定性的关键手段。而作为最广泛使用的 web 服务器和反向代理组…
-
python爬虫和java爬虫性能比较


Java爬虫在性能上优于Python爬虫,尤其是在大规模或复杂爬取任务中。原因包括Java的编译执行更快,成熟的垃圾收集器减少内存开销,高效的多线程模型提高并发性,明确的内存管理降低内存泄漏风险,以及在分布式系统中强大的扩展性。 Python 与 Java 爬虫性能比较 直接回答: 一般来说,Jav…
-
Baidu引擎入口在哪里 Baidu搜索免费直链快速进入



百度提供多种网站链接提交方式,根据需求选择:快速收录适合时效性内容,需在搜索资源平台验证后使用,48小时内处理;普通收录支持API推送等方式,是稳定高效的日常方案;便捷提交无需验证,通过公开页面提交,但不保证收录,适合作为补充。优质内容和清晰结构才是收录与排名的关键。 快速收录:适合高时效性内容 如…
