
peech
-
如何用紧凑型语音表征打造高性能语音合成系统
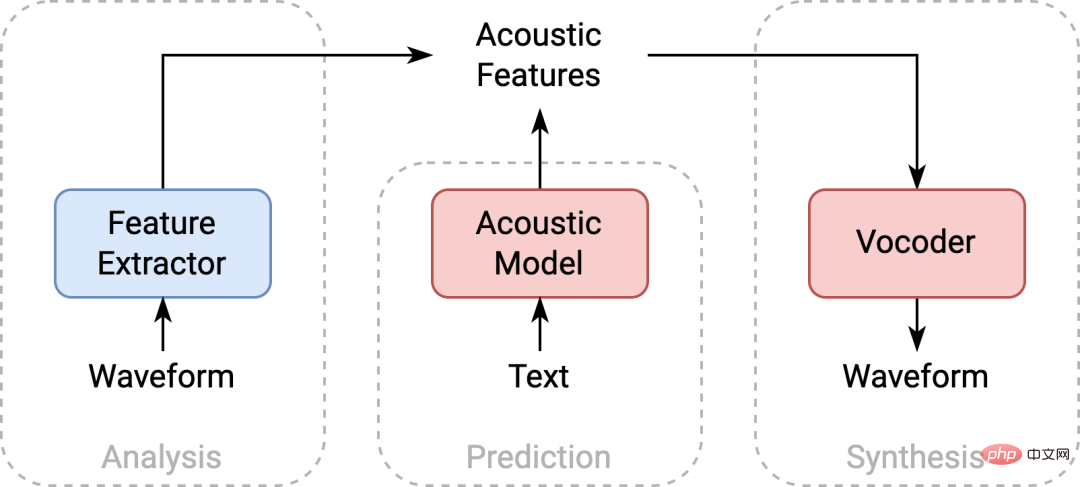
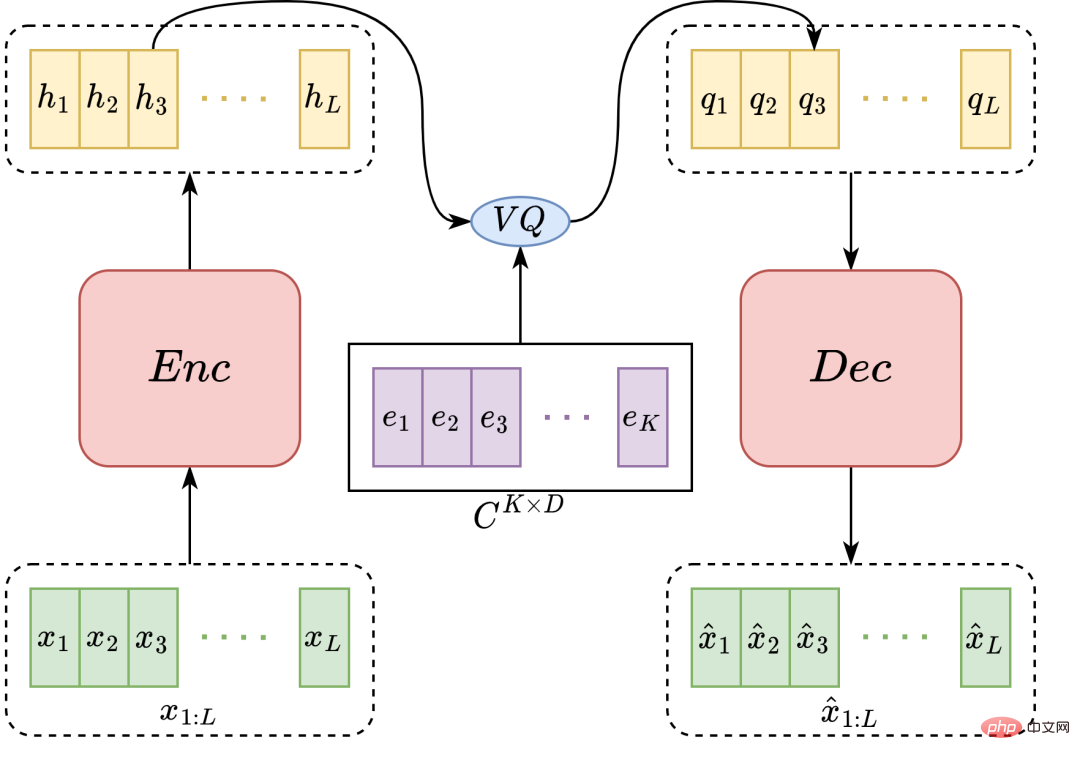
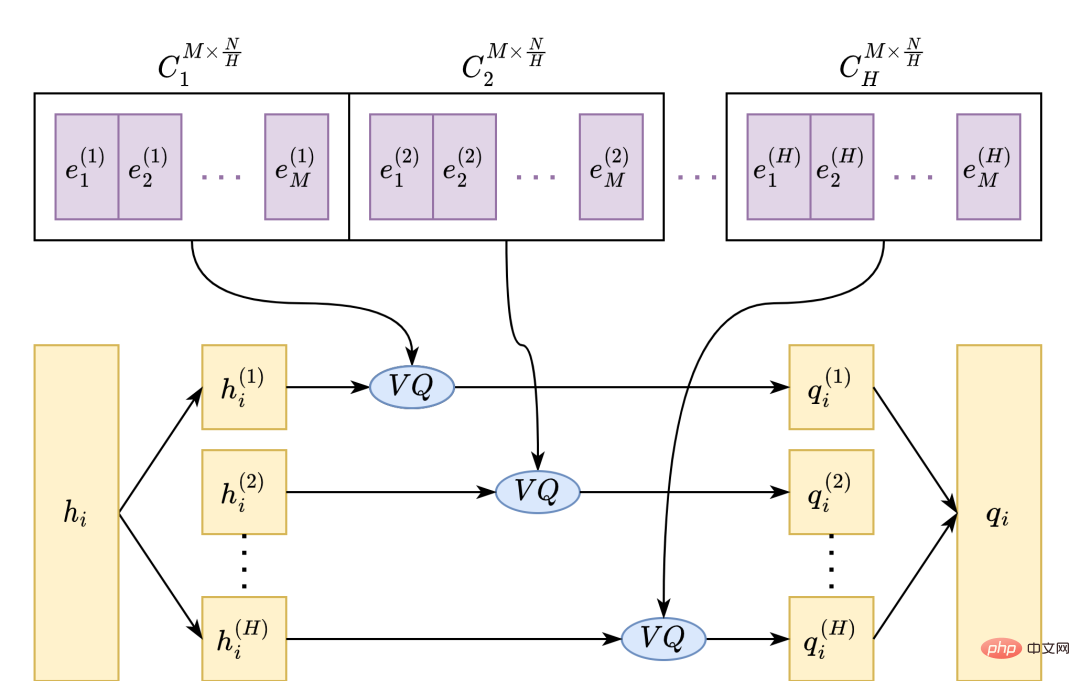
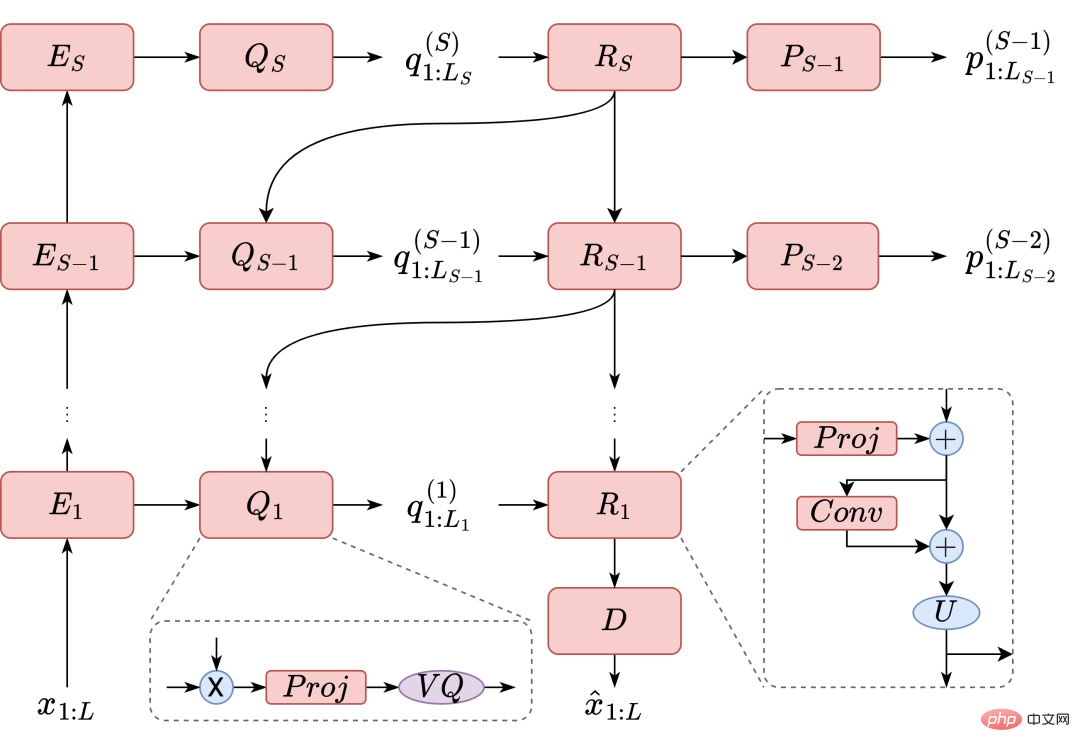
小红书多媒体智能算法团队和香港中文大学首次联合提出了基于多阶段多码本紧凑型语音表征的高性能语音合成方案 MSMC-TTS。基于矢量量化变分自编码器(VQ-VAE)的特征分析器采用若干码本对声学特征进行阶段式编码,形成一组具有不同时间分辨率的隐序列集合。这些隐序列可以由多阶段预测器从文本中预测获得,并…
-
对着手机咳嗽一声,就能检测新冠了?还是剑桥大学出品




新冠病毒的出现,真算是打开了潘多拉的魔盒。 如今不断新出现的变种,打乱了整个地球人的生活。新冠之前那种不戴口罩的生活,也许再也回不去了。 最近,科学家们有了一个新发现,或许未来可以让我们告别捅嗓子眼儿的日子。 在西班牙巴塞罗那举行的欧洲呼吸学会国际会议上,一项研究显示,AI可通过手机应用程序收集到的…
-
谷歌机器人实现高达93.5%准确率的交互语言,开源数据量提升十倍。


注意看,眼前的这个男人正在对着一个机器人不断发出自然语言指令,如「把绿色的星推到红色块之间」、「把蓝色的方块移动到左下角」,机器人对每一次输入的指令都可以实时完成。 自上世纪60年代开始,机器人专家就开始尝试让机器人听懂人的「自然语言指令」,并执行具体的行动。 理想情况下,未来的机器人将对用户能够用…
-
只需3秒就能偷走你的声音!微软发布语音合成模型VALL-E:网友惊呼「电话诈骗」门槛又拉低了

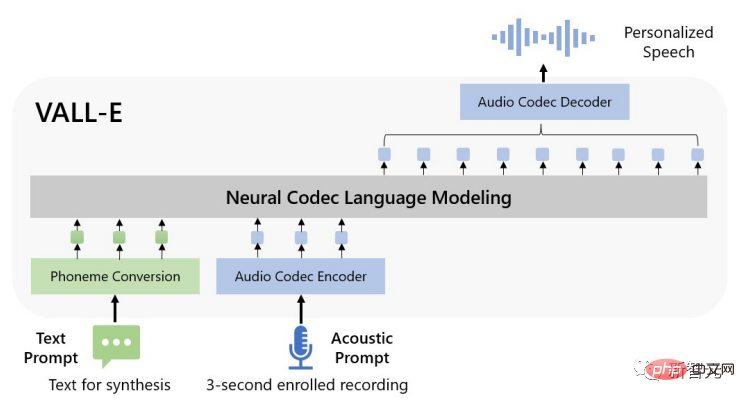


让ChatGPT帮你写剧本,Stable Diffusion生成插图,做视频就差个配音演员了?它来了! 最近来自微软的研究人员发布了一个全新的文本到语音(text-to-speech, TTS)模型VALL-E,只需要提供三秒的音频样本即可模拟输入人声,并根据输入文本合成出对应的音频,而且还可以保持…
-
AI行业研报:生成式文字后即将爆发生成式音频?
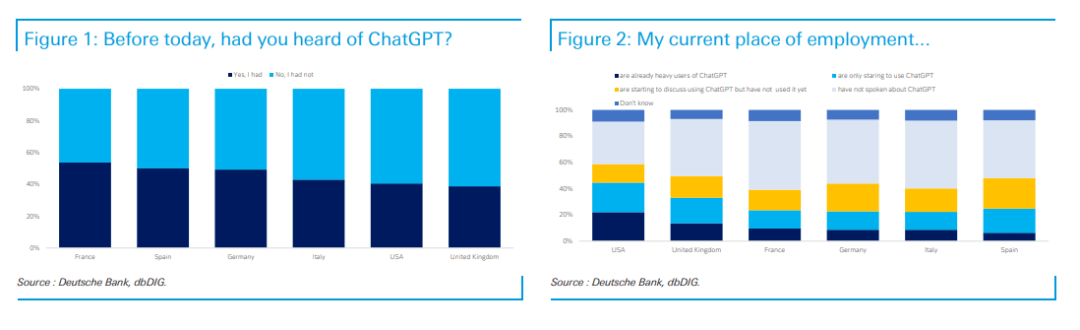
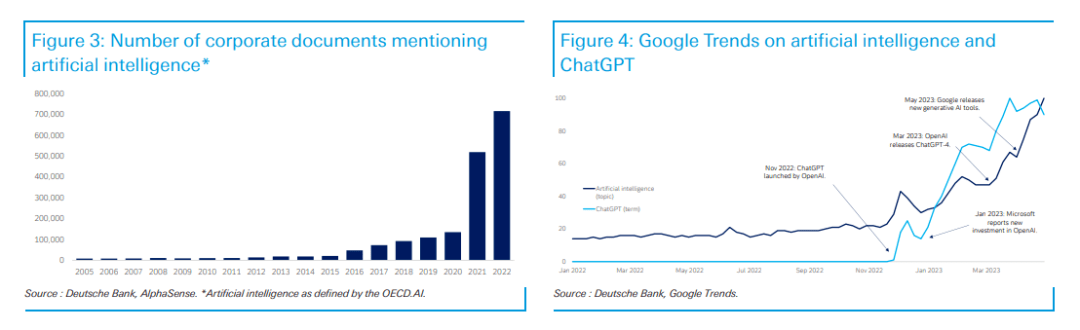
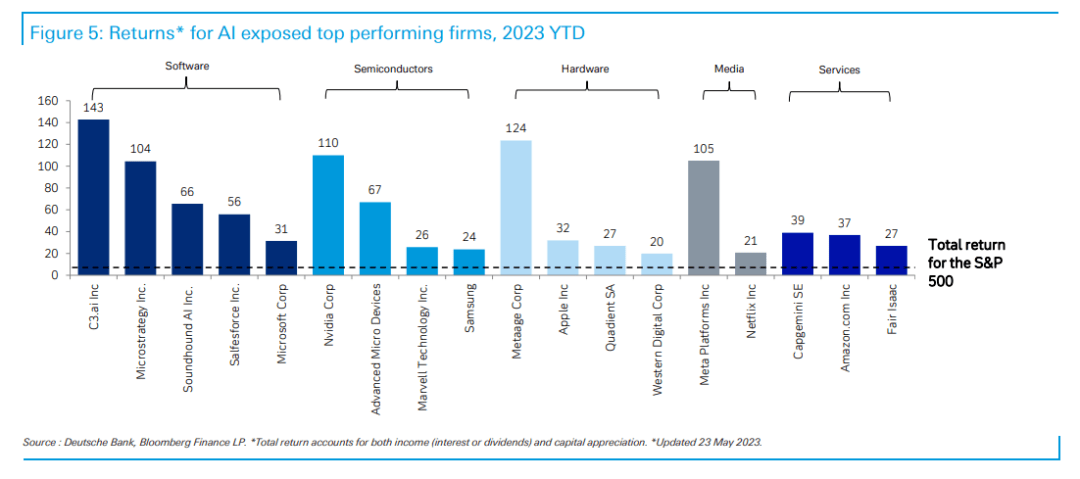
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜ 在爆发全球热潮前,人工智能是经过了多年酝酿的。为了正确预测未来的人工智能创新,我们回到源头,研究了人工智能应用的专利和风险投资交易活动。 我们收集了193个世界知识产权组织(WIPO)成员在20…
-
豆包AI的「语音识别」不灵敏如何优化?灵敏度调整与引擎选择




豆包ai语音识别不灵敏的优化方法主要包括调整灵敏度和更换语音识别引擎。1. 环境噪音评估:确保使用环境安静,或使用降噪设备;2. 麦克风设置:合理调整音量与增益;3. 提高语音清晰度,避免语速过快或口音过重;4. 软件内调整灵敏度参数;5. 更换语音识别引擎,如科大讯飞、google cloud等;…
-
微软大牛加入ZOOM,AI人才大战打响

ai大战越演越烈,“人才争夺战”也开始白热化。稀缺的ai顶尖人才,成为各大公司争相邀请加入的对象。 ZOOM公司已聘请微软Azure云服务全球人工智能首席技术官黄学东出任CTO,他将离开微软。 ☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜ …
-
哪些AI剪辑平台支持中文语音识别和智能字幕?




目前市面上支持中文语音识别和智能字幕功能的ai剪辑平台有:1. 网易见外,支持普通话及部分方言识别,可导出srt、ass字幕,适合教育和内容创作;2. adobe express,在线工具支持中文语音识别与字幕样式自定义,适合vlog和短视频创作者;3. 蜜蜂剪辑,集成语音转文字功能,支持多语种识别…
-
谷歌AudioPaLM实现「文本+音频」双模态解决,说听两用大模型

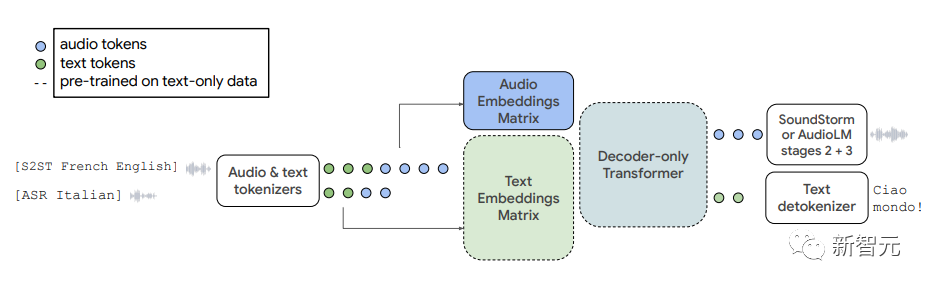
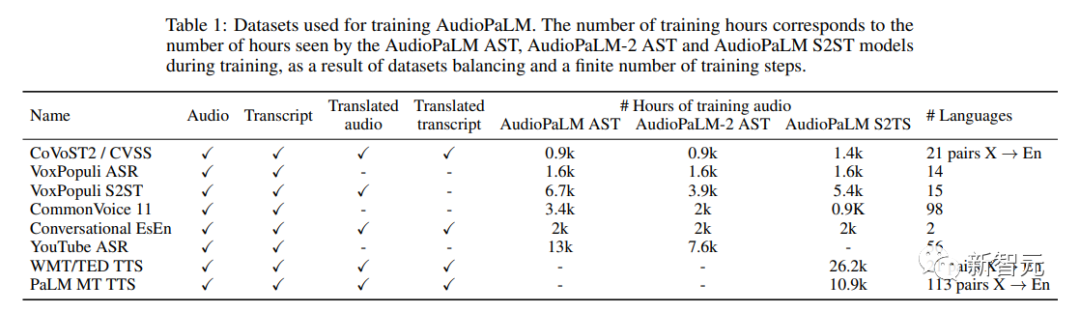
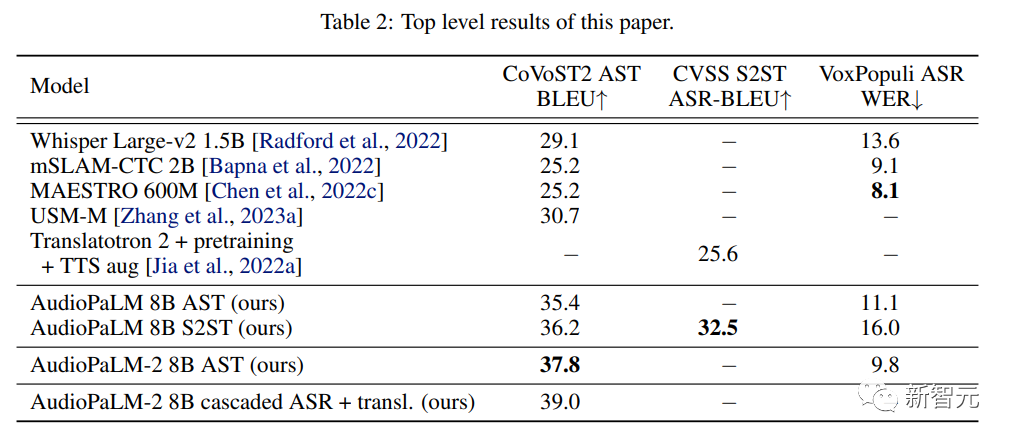
大型语言模型以其强大的性能及通用性,带动了一批多模态的大模型开发,如音频、视频等。 语言模型的底层架构大多是基于Transformer,且以解码器为主,所以无需过多调整模型架构即可适应其他序列模态。 最近,谷歌发布了一个统一的语音-文本模型AudioPaLM,将文本和音频的token合并为一个多模态…



