
强化
-
首次解释 LLM 如何推理反思!西北大学谷歌新框架:引入贝叶斯自适应强化学习,数学推理全面提升


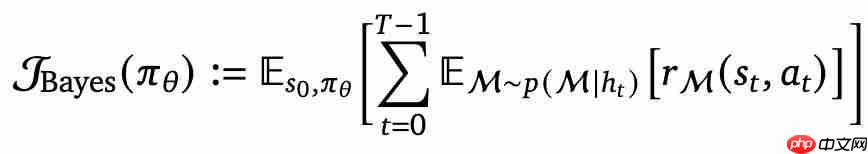
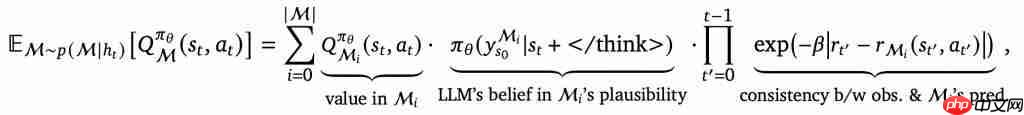
推理模型常表现出类似自我反思的行为,但它们是否真的能有效探索新策略? 对此,西北大学与 Google、谷歌 DeepMind 团队对传统强化学习与反思的关系提出质疑,并提出了贝叶斯自适应的强化学习方法,首次解释了为何、如何以及何时应进行反思和探索。 通过对比采用传统强化学习和新方法训练的模型,研究人…
-
陈丹琦新作:大模型强化学习的第三条路,8B 小模型超越 GPT-4o


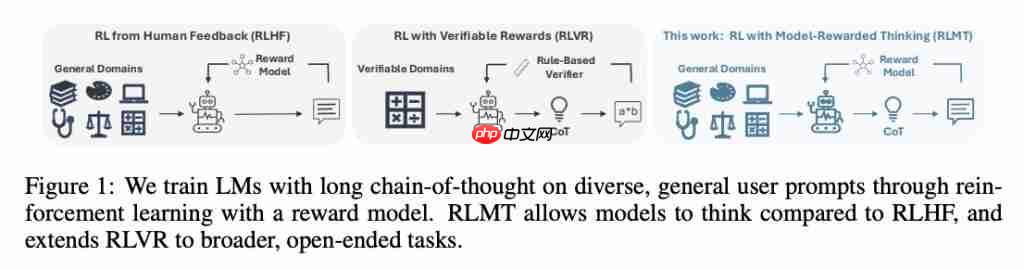
结合 RLHF 与 RLVR 的优势,仅需 8B 参数的小模型便能超越 GPT-4o,并媲美 Claude-3.7-Sonnet。 陈丹琦团队最新研究引发广泛关注。 他们提出了一种名为 RLMT(Reinforcement Learning with Model-rewarded Thinking,…
