
qwen
-
探索跳跃式思维链:DeepSeek创造力垫底,Qwen系列接近人类顶尖水平


aixiv专栏持续关注并报道全球顶尖ai研究成果。多年来,我们已发布超过2000篇学术及技术文章,涵盖众多高校和企业实验室的领先研究。欢迎优秀研究者投稿或联系我们进行报道。投稿邮箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com 当前,大语言模型…
-
开源仅6天,阿里万相大模型登上全球开源榜首
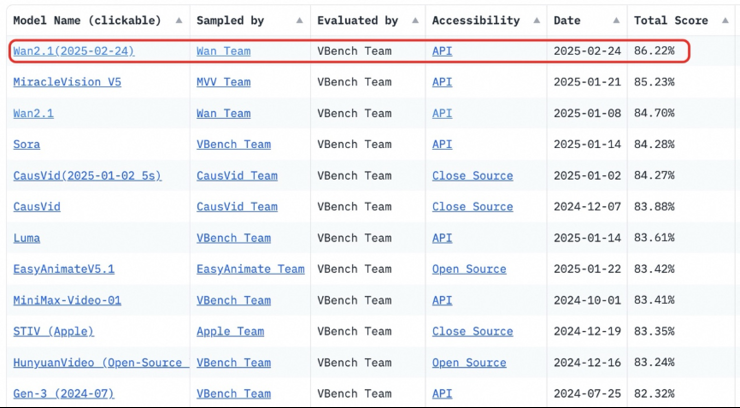


阿里万相大模型开源仅6天,便在hugging face社区力压群雄,荣登模型热榜和模型空间榜榜首,成为近期全球最受瞩目的开源大模型。其在hugging face和魔搭社区的累计下载量已突破百万,github star数更超过6000。 ☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量…
-
Qwen3 Embedding— 阿里通义开源的文本嵌入模型系列



☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜ 通义灵码 阿里云出品的一款基于通义大模型的智能编码辅助工具,提供代码智能生成、研发智能问答能力 31 查看详情 Qwen3 表征是什么 qwen3 表征是依托于 qwen3 主体模型研发的文本表…
-
Meta AI 发布 MobileLLM-R1:轻量级边缘推理模型


近日,Meta AI 推出了名为 MobileLLM-R1 的轻量级边缘推理模型系列,现已在 Hugging Face 平台上线。该系列涵盖从140M到950M参数规模的多种模型,专为高效执行数学、编程及科学推理任务而设计,在低于10亿参数的体量下展现出卓越性能。 其中最大的型号为 MobileLL…
-
行业首发!TCL华星发布显示领域首款强推理垂域模型——星智X-Intelligence 3.0

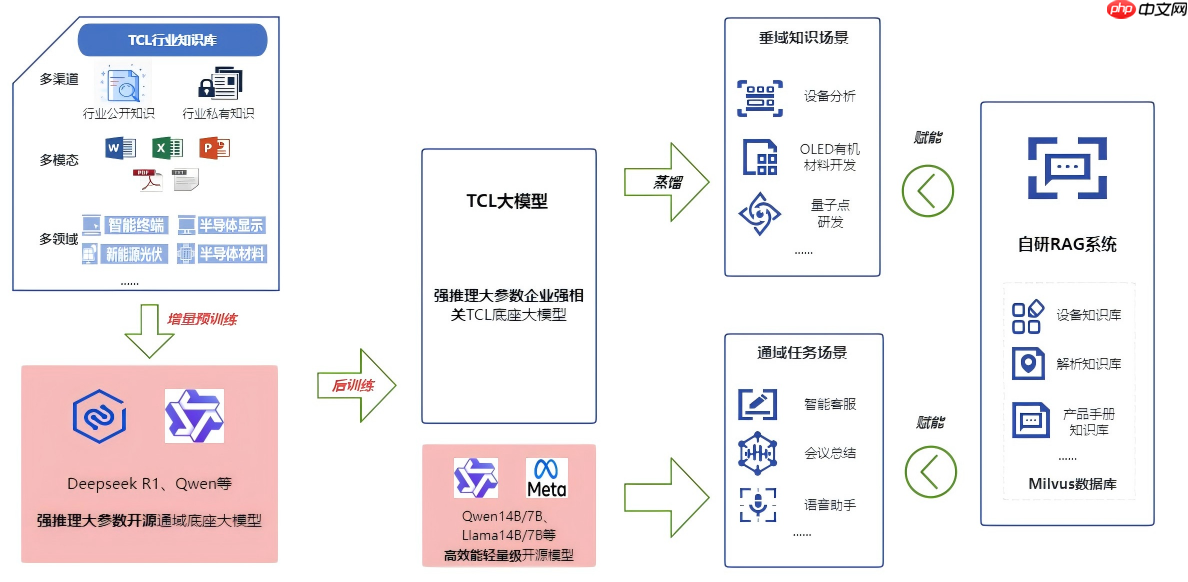
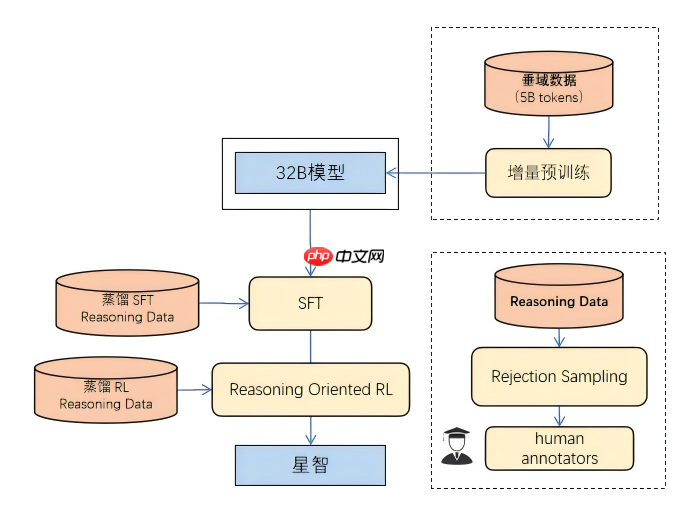

ai技术不仅推动了生产工具的升级,更成为重塑产业格局、重构生产体系的关键力量。随着新一轮科技革命和产业变革的加速推进,以chatgpt、deepseek等为代表的大模型技术迅猛发展,如何将大模型有效应用于工业场景,满足智能化需求,已成为各企业积极探索的方向。作为全球半导体显示行业的领军者,tcl华星…
-
Qwen-MT— 阿里通义千问推出的机器翻译模型


Qwen-MT是什么 qwen-mt 是由阿里通义千问团队研发的专用机器翻译模型,依托先进的 qwen3 架构构建。该模型支持多达 92 种语言之间的高质量互译,覆盖全球超过 95% 的人口,适用于各类跨语言沟通场景。采用轻量级 moe(mixture of experts)架构设计,具备响应迅速、…
-
魅族22新机9月15日正式发布 配5000万像素旗舰四主摄
9月8日,魅族官方发布消息,宣布魅族22将于9月15日14:30正式亮相,届时将召开魅族22旗舰手机及flyme aios生态新品发布会。本次发布会除了主角魅族22外,还将带来ai拍摄眼镜、flyme auto 2智能车机系统以及pΛndΛer等多款全新产品。 魅族22 据官方透露,魅族22将搭载第…
-
ScreenCoder— 开源的智能UI截图生成前端代码工具


ScreenCoder是什么 screencoder 是一个开源的智能 ui 图像转代码系统,能够将任意设计截图高效转换为结构清晰、可编辑的 html/css 前端代码。该系统采用模块化多智能体架构,融合视觉理解、布局解析与代码生成技术,输出语义准确、布局精准的代码结果。用户可轻松调整生成的界面结构…
-
Liquid AI 发布 LFM2-8B-A1B:8B 参数仅激活 1.5B

高效moe架构重塑边缘计算边界——liquid ai推出全新lfm2-8b-a1b模型,作为lfm2系列首款混合专家(mixture-of-experts, moe)架构模型,其总参数量达8.3b,但每token仅激活约1.5b参数。得益于稀疏激活机制,该模型在维持强大表达能力的同时显著降低计算开销…
-
英伟达发布 Jet-Nemotron 系列小模型,理论最大加速比 56 倍
在最新发布的论文中,英伟达推出的 jet-nemotron 系列混合架构语言模型在多项基准测试中表现优异,精度上超越或媲美 qwen3、qwen2.5、gemma3 和 llama3.2,同时实现了最高达 53.6 倍的生成吞吐量提升和 6.1 倍的预填充加速。与当前先进的 moe 全注意力模型如 …

