sft
-
显著超越 SFT,o1/DeepSeek-R1 背后秘诀也能用于多模态大模型了
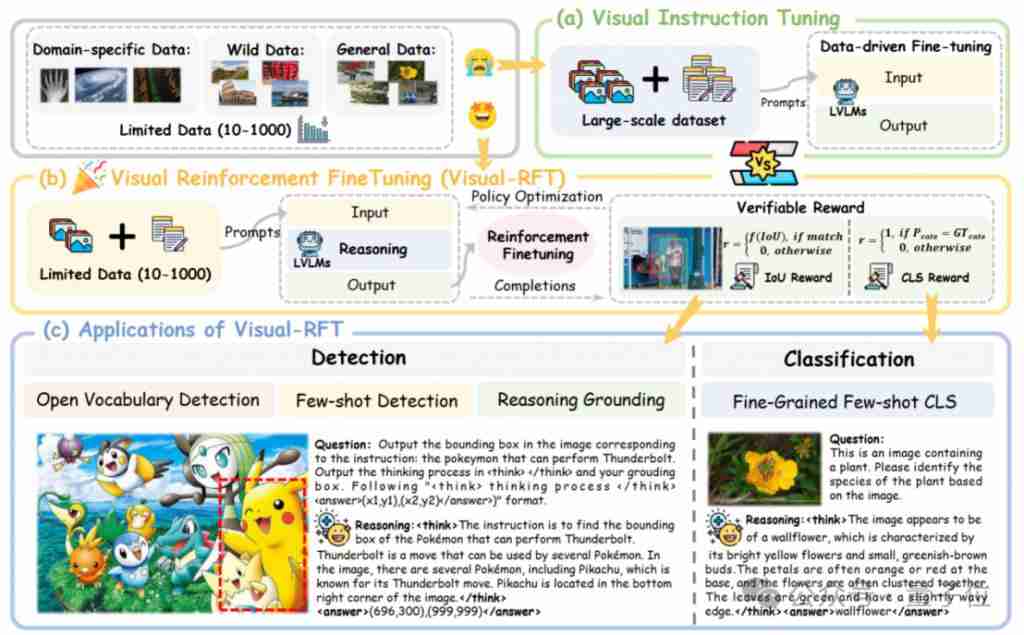

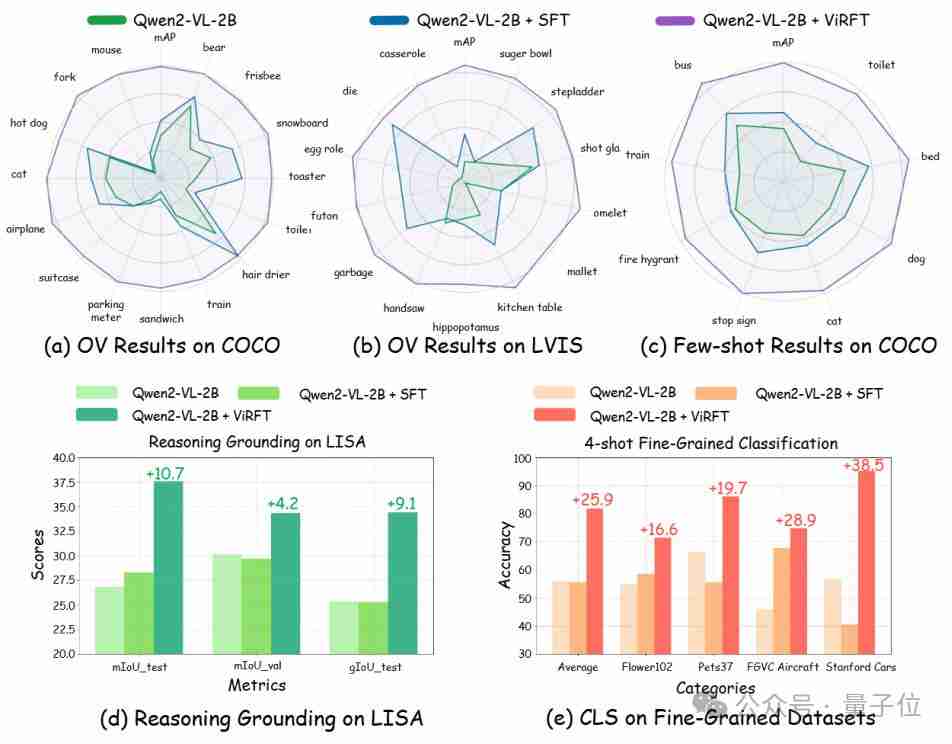
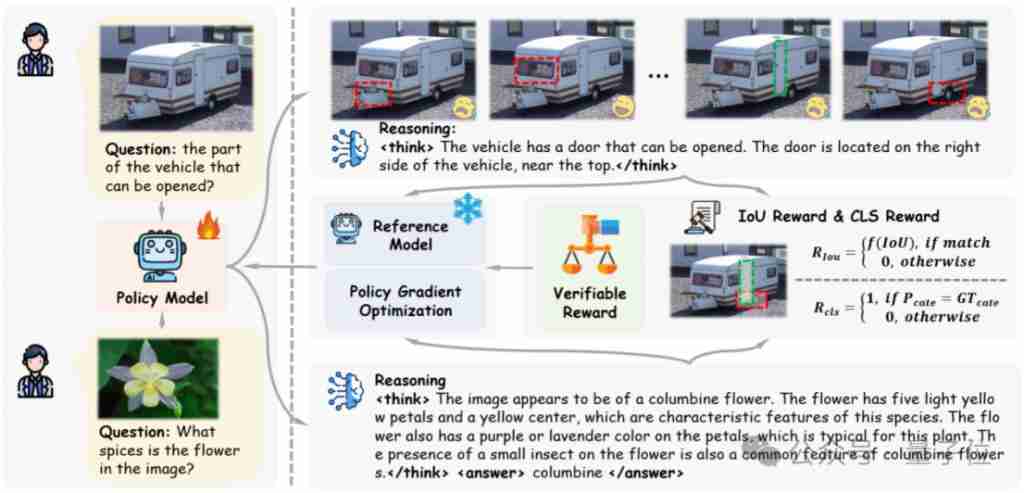
上海交大、上海ai lab和港中文大学的研究人员推出visual-rft(视觉强化微调)开源项目,该项目仅需少量数据即可显著提升视觉语言大模型(lvlm)性能。visual-rft巧妙地将deepseek-r1的基于规则奖励的强化学习方法与openai的强化微调(rft)范式相结合,成功地将这一方法…

上海交大、上海ai lab和港中文大学的研究人员推出visual-rft(视觉强化微调)开源项目,该项目仅需少量数据即可显著提升视觉语言大模型(lvlm)性能。visual-rft巧妙地将deepseek-r1的基于规则奖励的强化学习方法与openai的强化微调(rft)范式相结合,成功地将这一方法…
