
视觉
-
中国电信在 ACM MM 发表突破性论文:推动视觉智能
近日,中国电信在边缘视觉感知技术方面实现了重大突破。其科研团队创新性地提出了一种名为 hdcfn(haze distribution-aware cross-modal fusion network)的雾浓度感知跨模态融合算法,该项研究成果得到了国际学术界的广泛认可,并被多媒体领域最具影响力的会议之…
-
更深层的理解视觉Transformer, 对视觉Transformer的剖析

本文为经过自动驾驶之心公众号授权转载,请在转载时与出处联系 写在前面&&笔者的个人理解 目前,基于Transformer结构的算法模型已经在计算机视觉(CV)领域产生了极大的影响。它们在许多基本的计算机视觉任务上超越了以前的卷积神经网络(CNN)算法模型。以下是我找到的最新的不同基础…
-
借助独特2D材料和机器学习,CV像人一样「看见」数百万种颜色




人的眼睛可以看见数百万种颜色,现在人工智能也可以。 近日,来自美国东北大学的一个跨学科研究团队使用新的人工智能技术构建了一种可以识别数百万种颜色的新设备 A-Eye,这让机器视觉领域迈出了一大步,将被广泛应用于自动驾驶汽车、农业分拣和远程卫星成像等一系列技术。 研究论文发表在了《Materials …
-
USB:首个将视觉、语言和音频分类任务进行统一的半监督分类学习基准


当前,半监督学习的发展如火如荼。但是现有的半监督学习基准大多局限于计算机视觉分类任务,排除了对自然语言处理、音频处理等分类任务的一致和多样化评估。此外,大部分半监督论文由大型机构发表,学术界的实验室往往由于计算资源的限制而很难参与到推动该领域的发展中。 为此,微软亚洲研究院的研究员们联合西湖大学、东…
-
北大具身智能新成果:无需训练,听指令就能灵活走位




北京大学董豪团队具身导航最新成果来了: 无需额外建图和训练,只需说出导航指令,如: Walk forward across the room and walk through the panty followed by the kitchen. Stand at the end of the kit…
-
阿里 8B 模型拿下多页文档理解新 SOTA,324 个视觉 token 表示一页,缩减 80%
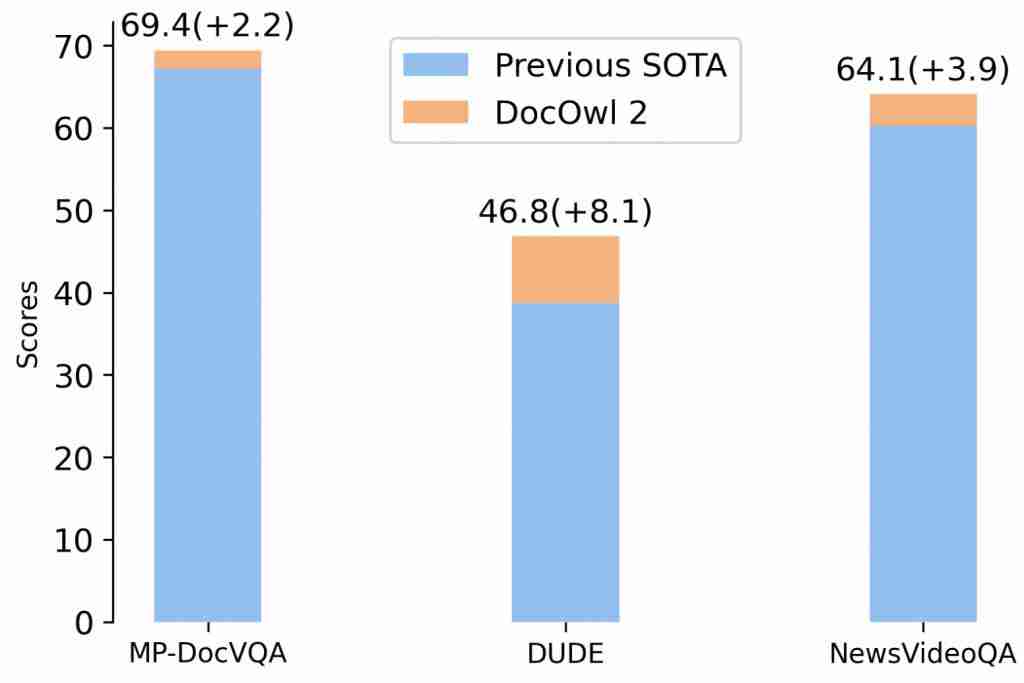
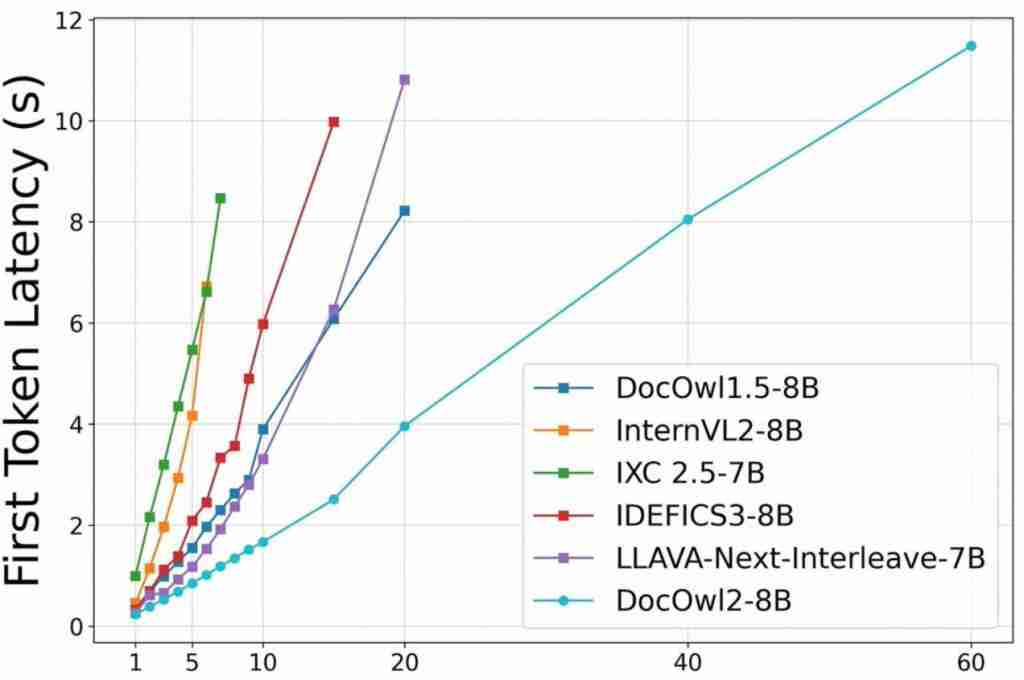
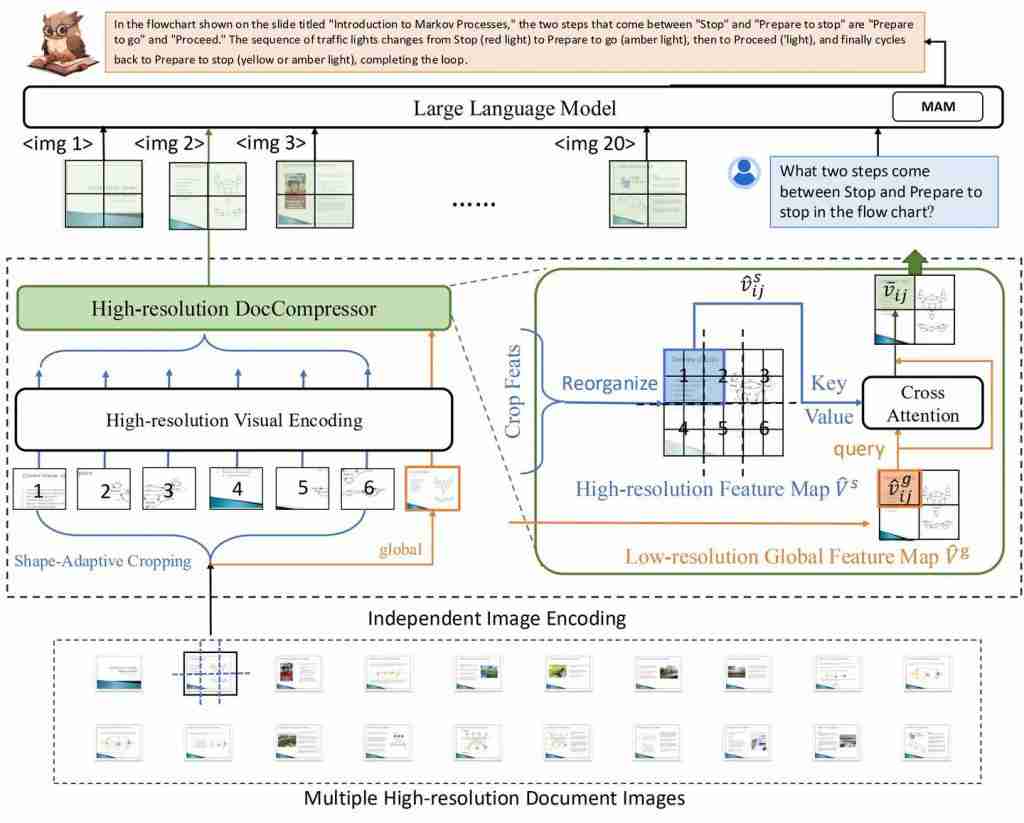
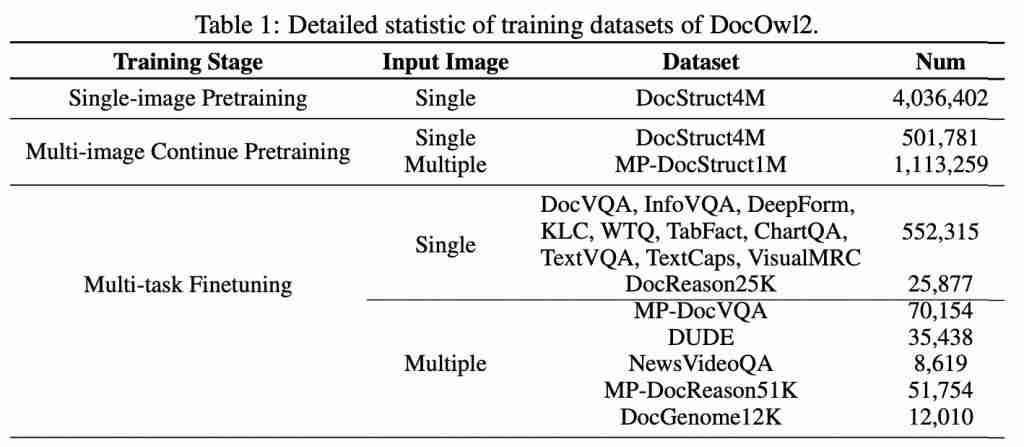
高效多页文档理解,阿里通义实验室 mplug 团队拿下新 sota。 最新多模态大模型mPLUG-DocOwl 2,仅以 324 个视觉 token 表示单个文档图片,在多个多页文档问答 Benchmark 上超越此前 SOTA 结果。 并且在 A100-80G 单卡条件下,做到分辨率为 1653&…
-
来一趟未来之旅,首个多视图预测+规划自动驾驶世界模型抵达


近期,世界模型的概念引发了火热浪潮,而自动驾驶领域岂能隔岸观「火」。来自中科院自动化所的团队,首次提出了一种名为 Drive-WM 的全新多视图世界模型,旨在增强端到端自动驾驶规划的安全性。 ☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜ 网…
-
后Sora时代,CV从业者如何选择模型?卷积还是ViT,监督学习还是CLIP范式

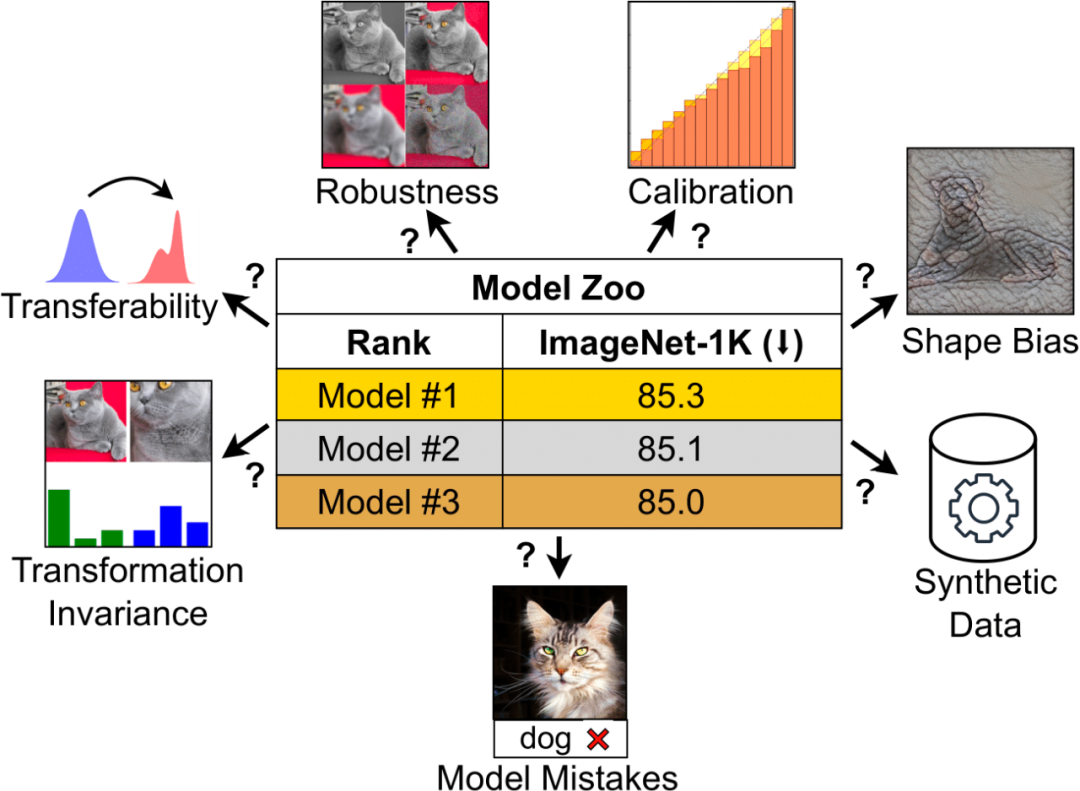


ImageNet准确率曾是评估模型性能的主要指标,但在当今计算视觉领域,这一指标逐渐显得不够完善。 随着计算机视觉模型变得更加复杂,可用模型种类已显著增加,从ConvNets到Vision Transformers。训练方法也发展到自监督学习和像CLIP这样的图像-文本对训练,不再局限于ImageN…
-
一览Occ与自动驾驶的前世今生!首篇综述全面汇总特征增强/量产部署/高效标注三大主题
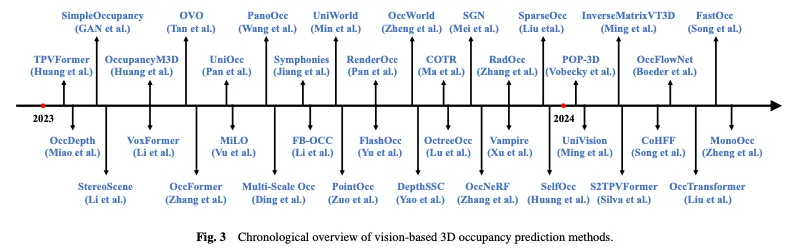
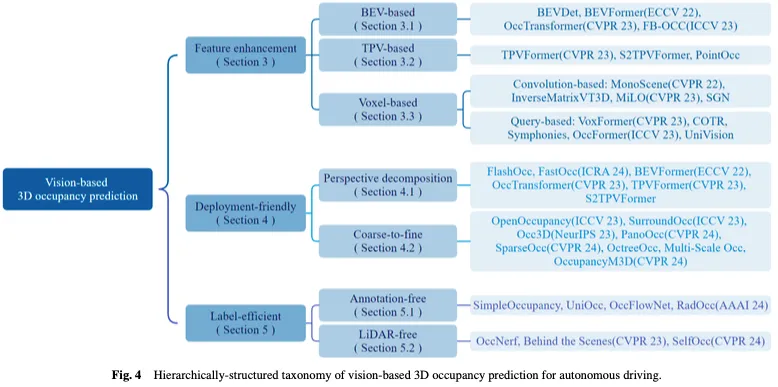
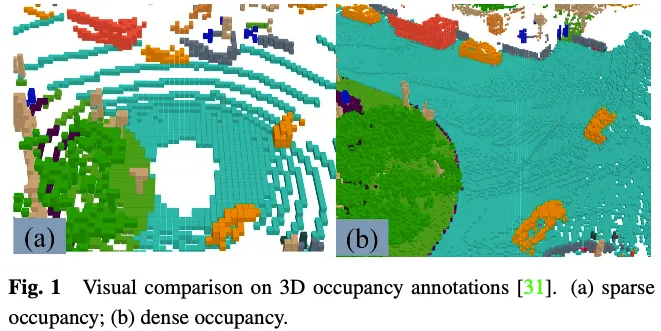
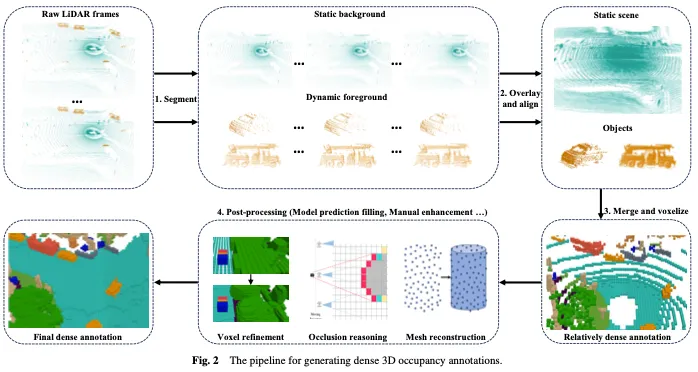
写在前面&笔者的个人理解 近年来,自动驾驶因其在减轻驾驶员负担和提高驾驶安全方面的潜力而越来越受到关注。基于视觉的三维占用预测是一种新兴的感知任务,适用于具有成本效益且对自动驾驶安全全面调查的任务。尽管许多研究已经证明,与基于物体为中心的感知任务相比,3D占用预测工具具有更大的优势,但仍存在…
-
揭秘DeDoDe v2:如何革新关键点检测技术,让AI“眼”更明亮?


☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜ 一、技术革新,DeDoDe v2应运而生 在图像处理和计算机视觉领域,关键点检测是许多应用的基础,如目标识别、图像匹配、三维重建等。然而,传统的关键点检测技术往往存在着在检测不准确、易受噪声干扰…

