
微调
-
大规模语言模型高效参数微调–BitFit/Prefix/Prompt 微调系列
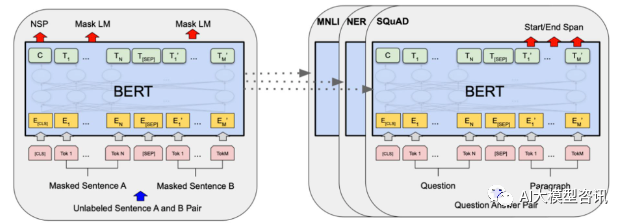
2018 年谷歌发布了 bert,一经面世便一举击败 11 个 nlp 任务的 state-of-the-art (sota) 结果,成为了 nlp 界新的里程碑; bert 的结构如下图所示, 左边是 bert 模型预训练过程, 右边是对于具体任务的微调过程。其中, 微调 阶段是后续用于一些下游任…
-
Code Llama代码能力飙升,微调版HumanEval得分超越GPT-4,一天发布
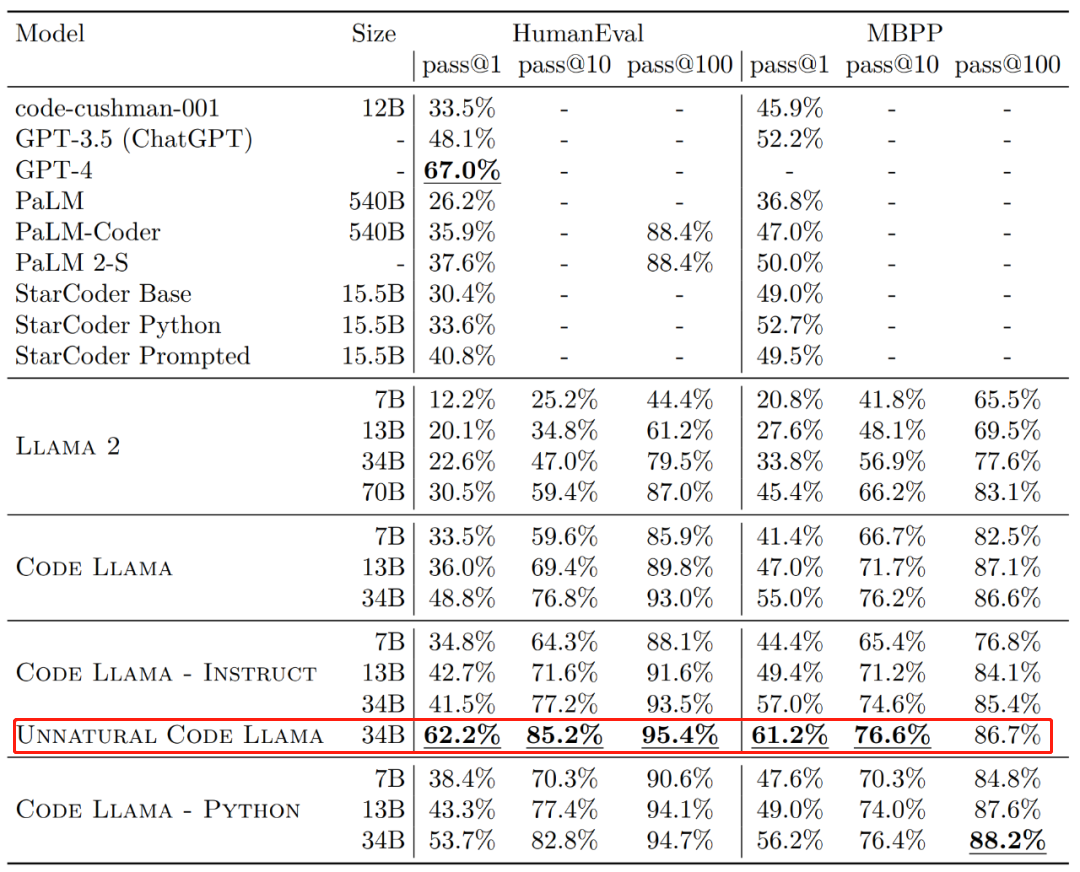

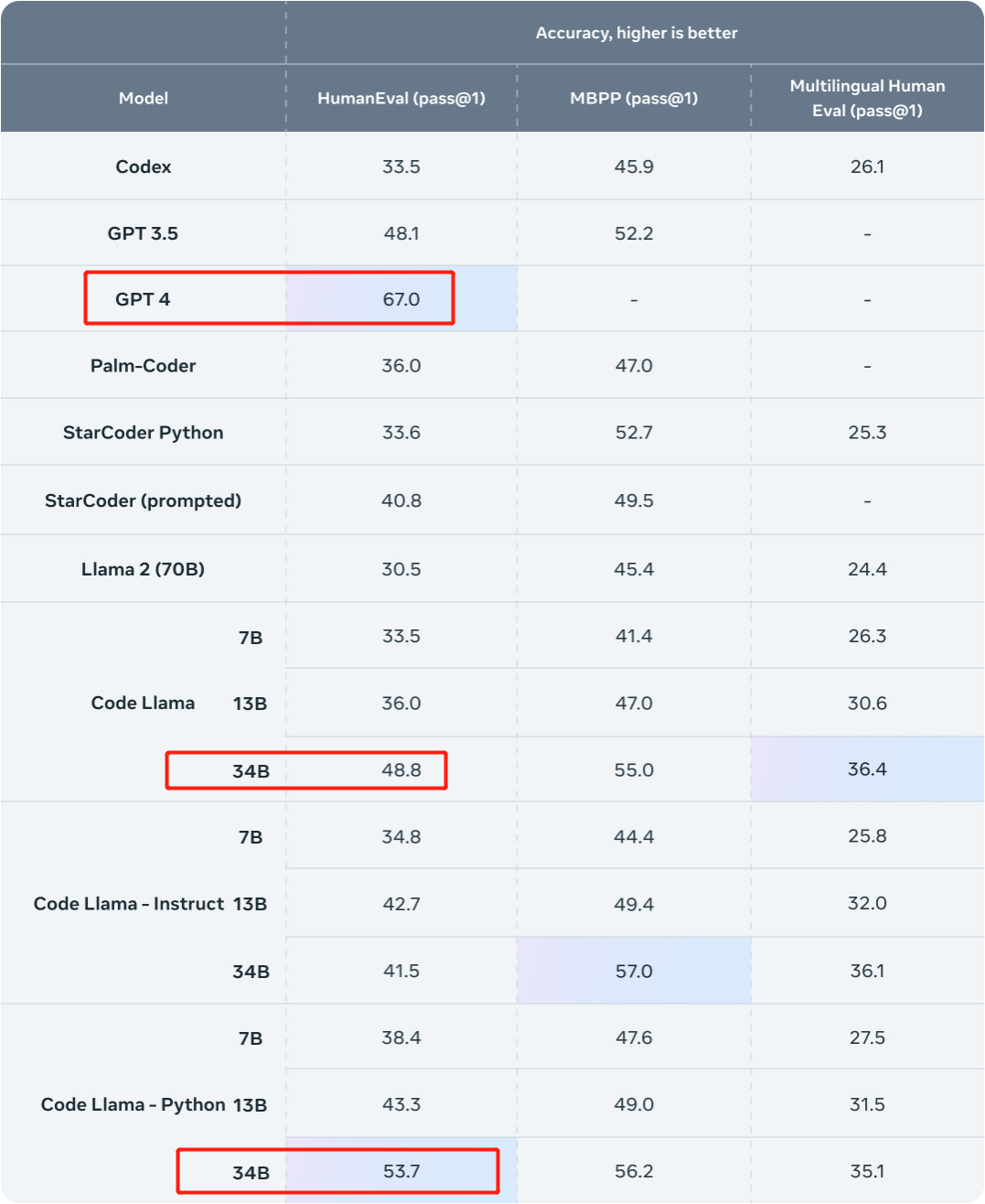
昨天,Meta 开源专攻代码生成的基础模型 Code Llama,可免费用于研究以及商用目的。 Code Llama 系列模型有三个参数版本,参数量分别为 7B、13B 和 34B。并且支持多种编程语言,包括 Python、C++、Java、PHP、Typescript (Javascript)、C…
-
Thinking Machine 新研究刷屏!结合 RL+ 微调优势,小模型训练更具性价比了
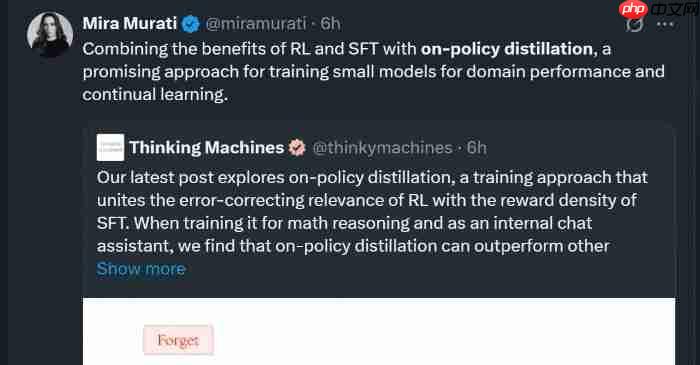

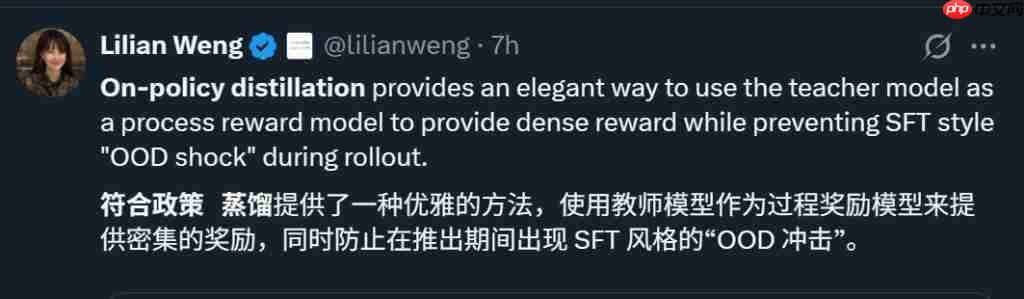

thinking %ignore_a_2% 最新研究正在被热议! 创始人、OpenAI 前 CTO Mira Murati 亲自转发后,一众围观大佬开始惊叹其研究价值(截不完、根本截不完): 根据 Mira Murati 的提炼,原来他们提出了一种让小模型更懂专业领域的 LLM(大语言模型)后训练方…
