稀疏计算
-
单卡A100实现百万token推理,速度快10倍,这是微软官方的大模型推理加速
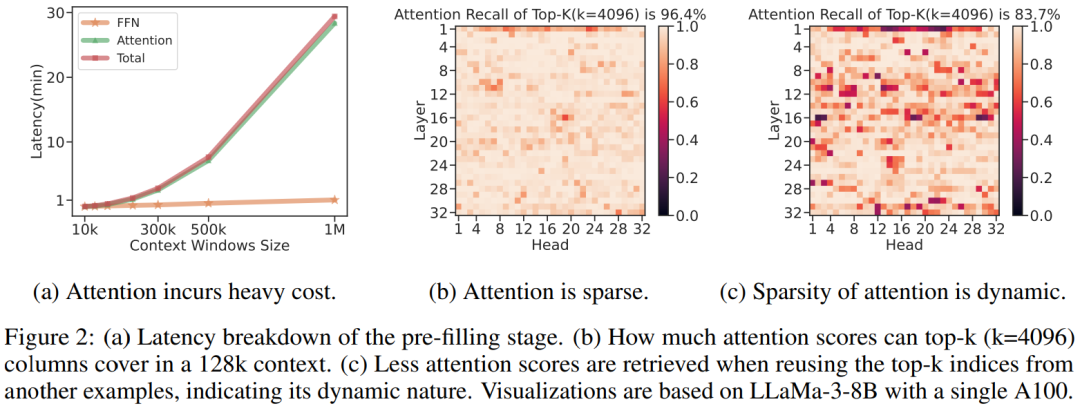

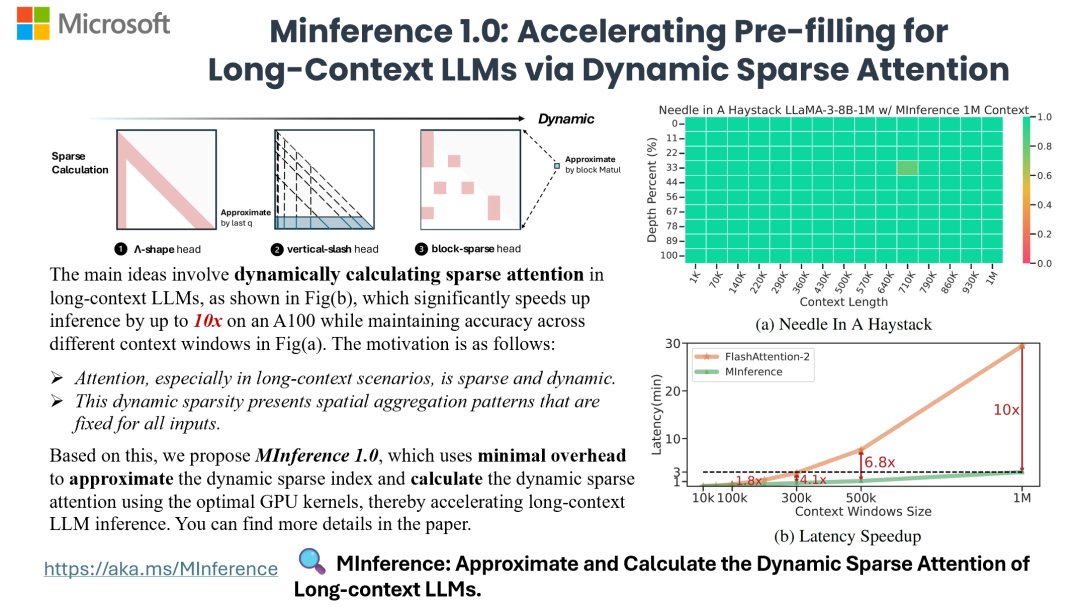

微软的这项研究让开发者可以在单卡机器上以 10 倍的速度处理超过 1m 的输入文本。 大型语言模型 (LLM) 已进入长上下文处理时代,其支持的上下文窗口从先前的 128K 猛增到 10M token 级别。 然而,由于注意力机制的二次复杂度,模型处理输入提示(即预填充阶段)并开始产生第一个 tok…

微软的这项研究让开发者可以在单卡机器上以 10 倍的速度处理超过 1m 的输入文本。 大型语言模型 (LLM) 已进入长上下文处理时代,其支持的上下文窗口从先前的 128K 猛增到 10M token 级别。 然而,由于注意力机制的二次复杂度,模型处理输入提示(即预填充阶段)并开始产生第一个 tok…
