稀疏模型
-
将多模态大模型稀疏化,3B模型MoE-LLaVA媲美LLaVA-1.5-7B

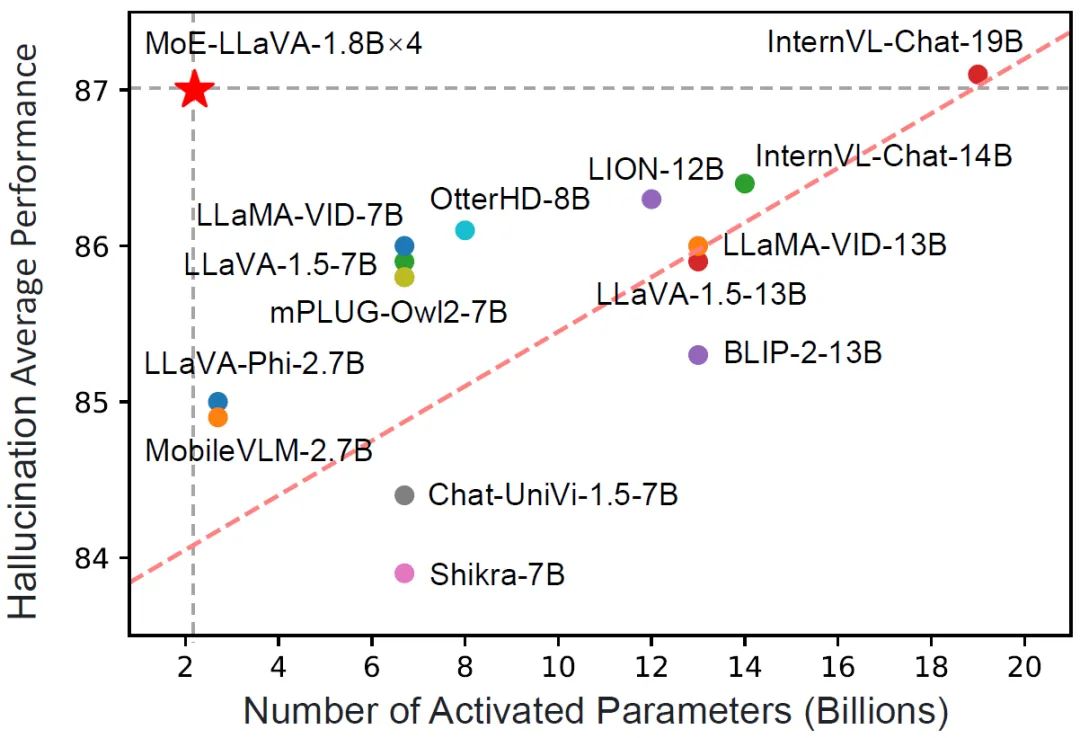
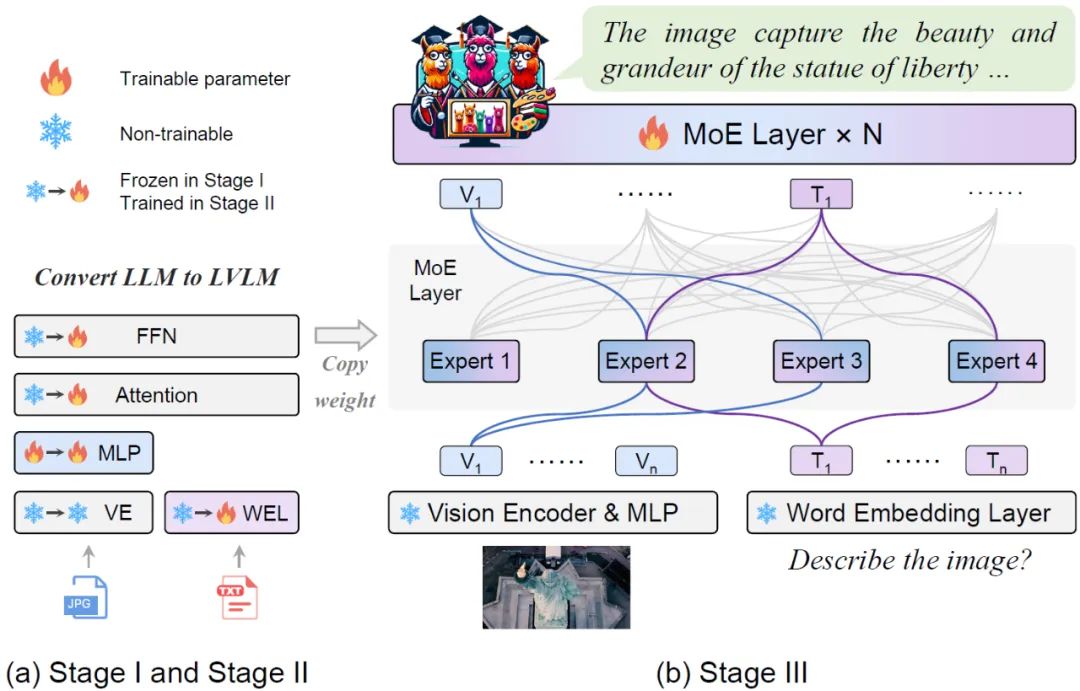

大型视觉语言模型(lvlm)可以通过扩展模型来提高性能。然而,扩大参数规模会增加训练和推理成本,因为每个token的计算都会激活所有模型参数。 来自北京大学、中山大学等机构的研究者联合提出了一种新的训练策略,名为MoE-Tuning,用于解决多模态学习和模型稀疏性相关的性能下降问题。MoE-Tuni…

大型视觉语言模型(lvlm)可以通过扩展模型来提高性能。然而,扩大参数规模会增加训练和推理成本,因为每个token的计算都会激活所有模型参数。 来自北京大学、中山大学等机构的研究者联合提出了一种新的训练策略,名为MoE-Tuning,用于解决多模态学习和模型稀疏性相关的性能下降问题。MoE-Tuni…
