大数据平台概述
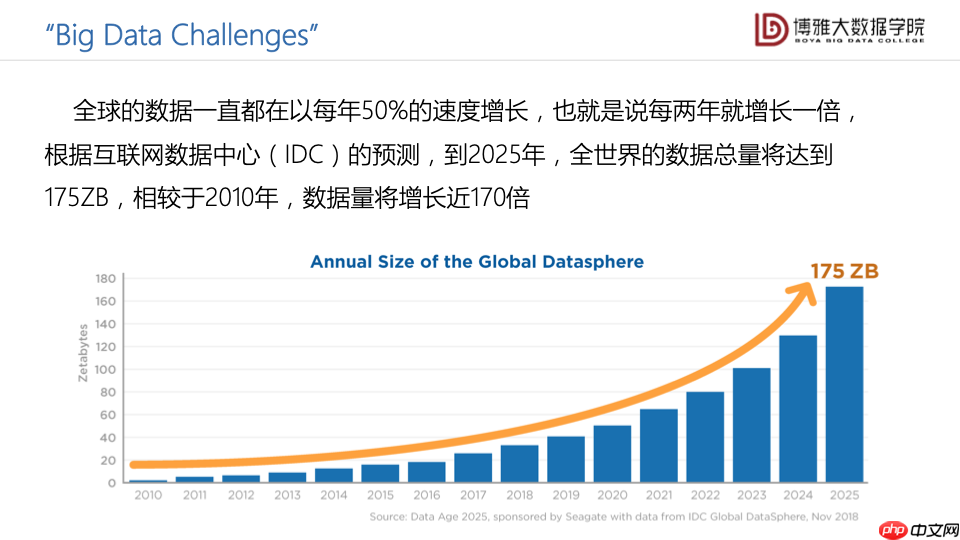
随着互联网技术的发展和智能传感设备的普及,我们来到了一个数据爆炸的时代。全球的数据以每年50%的速度在增长,也就是说两年就增长了一倍。根据互联网数据中心(idc)的预测,到2025年,全球数据总量将达到175zb,与2010年相比,数据量增长了近170倍。
面对如此庞大且随时还在不断增长的海量数据,如何对数据进行有效的存储、管理和分析,是目前大数据所面临的关键性挑战。

提升计算机处理能力的两种方式
针对日益增加的数据存储与分析的需要,有两种方式来提升计算机的处理能力:一种称作垂直扩展,另一种称作水平扩展。垂直扩展是指采用更快的CPU或者更大的内存、外存来提升计算机的性能。

而水平扩展也称作分布式计算,它是指通过添加更多的计算机一起协同工作,进而提升计算机的总体能力,这样的一组计算机通常是被看作一个整体。新添加的计算机通常应该与当前的计算机具有相似或相同的配置,这样它们才能够更好地协同工作。

从扩展方式来看,垂直扩展通过购买和使用更高配置的计算机配件或者通过更换计算机来实现,而水平扩展是指在已有的计算机群体中再添加计算机;从扩展成本来看,当垂直扩展到一定的阶段时,我们购置更好的配件或是更换更好计算机的成本就会变得十分昂贵,而水平扩展扩展到一定阶段,通过添加计算机来提升整体性能的成本相对较低。

从性价比来看,垂直扩展还存在着其它弊端。例如,由于超级计算机中配置的顶级处理器对应了较高要求的冷却系统,整体成本是非常高的。惠普在2013年开展了一项调查研究发现,在专用计算机上租用处理器的每小时成本,大约是水平扩展系统的2~3倍。我们可以从下面的曲线上看出,在交点之后,垂直扩展与水平扩展相比,成本呈指数级增长。

分布式计算
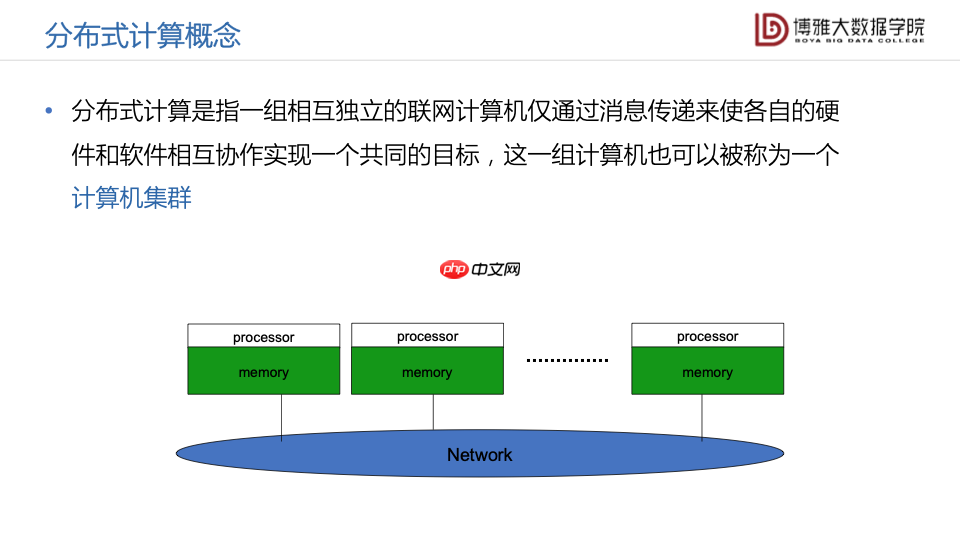
分布式计算,即水平扩展,是指一组相互独立的联网计算机,仅仅通过消息传递的方式来使各自的硬件和软件相互协作,进而实现一个共同的计算或处理目标。一组计算机被称作一个计算机集群,其中每一台计算机都有各自的处理器、各自的内存,都是独立可运行的计算机。
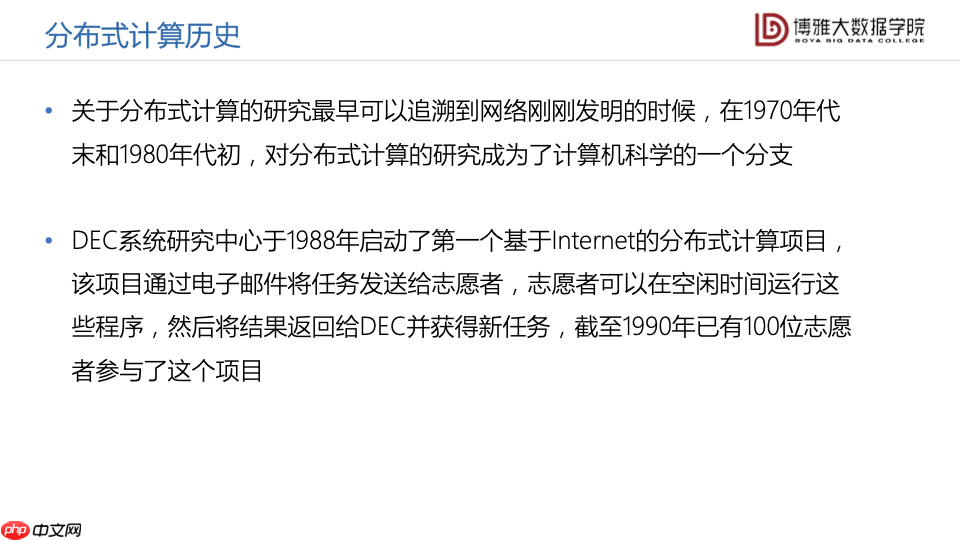
关于分布式计算的研究,最早可以追溯到网络刚刚发明的时候。在上世纪70年代末和80年代初,分布式计算就成为了计算机科学的一个新的分支。
DEC系统研究中心在1988年启动了第一个基于因特网的分布式计算项目,这个项目通过给志愿者发送电子邮件,邀请志愿者在空闲的时间运行一些程序,然后将结果返回给DEC系统研究中心并获得新任务。简单来说就是很多志愿者利用计算机的空闲时间,来帮助DEC系统研究中心做一些任务。截至1990年,一共有100位志愿者参与了这个项目。
到了1999年,一个真正可以正常运行工作的分布式计算项目——SETI@Home 出现了。这个项目通过分析波多黎各的Arecibo射电望远镜收集的无线电信号,来寻找外星智能生物生存的证据。这个项目于1999年5月开始启动,面向全球招募志愿者,将SETI@Home的程序运行在这些志愿者的计算机上。这个项目得到了全球许多志愿者的支持,截至2005年,已经有超过543万的志愿者参与到了这个项目中。

分布式计算类型
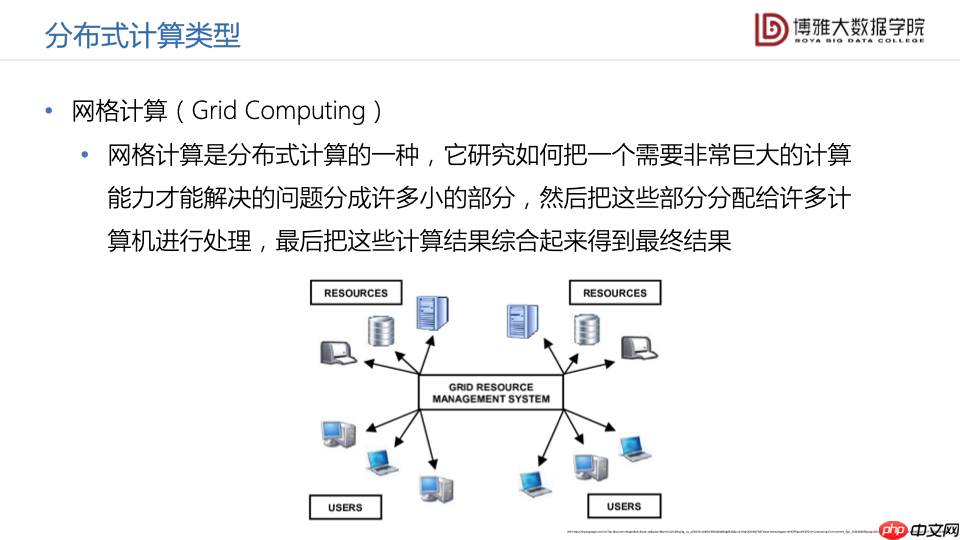
早期的网格计算是分布式计算的类型之一。网格计算主要解决如何将一个需要非常巨大计算能力才能解决的问题分成许多小的部分,然后把这些部分再分配给许多计算机进行处理,最后再把这些计算结果综合起来,得到最终的处理结果。这样网上的各种各样的计算资源、存储资源和输出设备,在统一的网格资源管理系统的管理下,就可以提供给位于多个地点的不同用户来分布式地共享和使用。
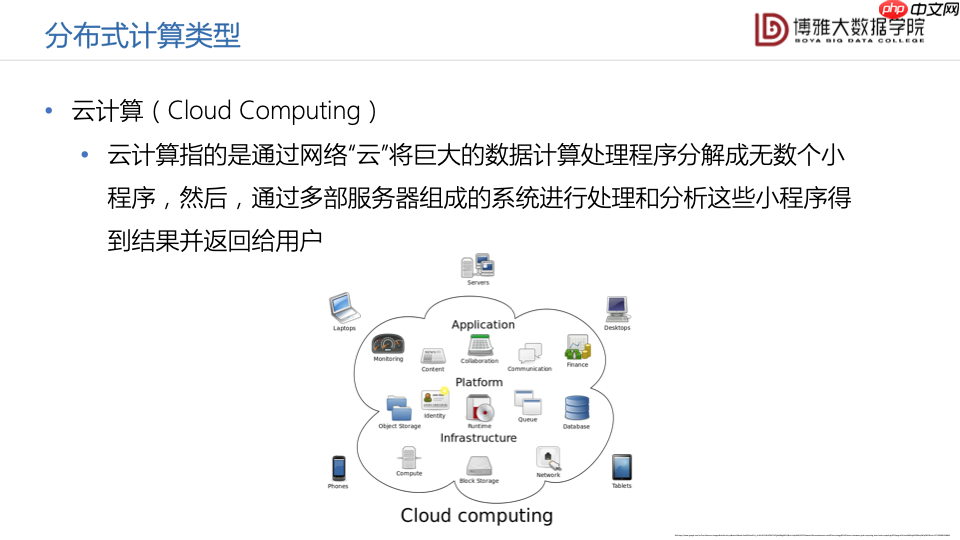
另一个分布式计算的类型是云计算。云计算实际上是通过网络构成一个“网云”,进而将巨大的数据计算处理程序分解成无数个小程序,然后通过多台服务器组成的系统来处理和分析这些小程序,得到结果再返回给用户。云计算发展到今天,实际上就是我们熟知的各类云服务。
分布式计算特点
无论是网格计算还是云计算,它都具有以下几个特点:
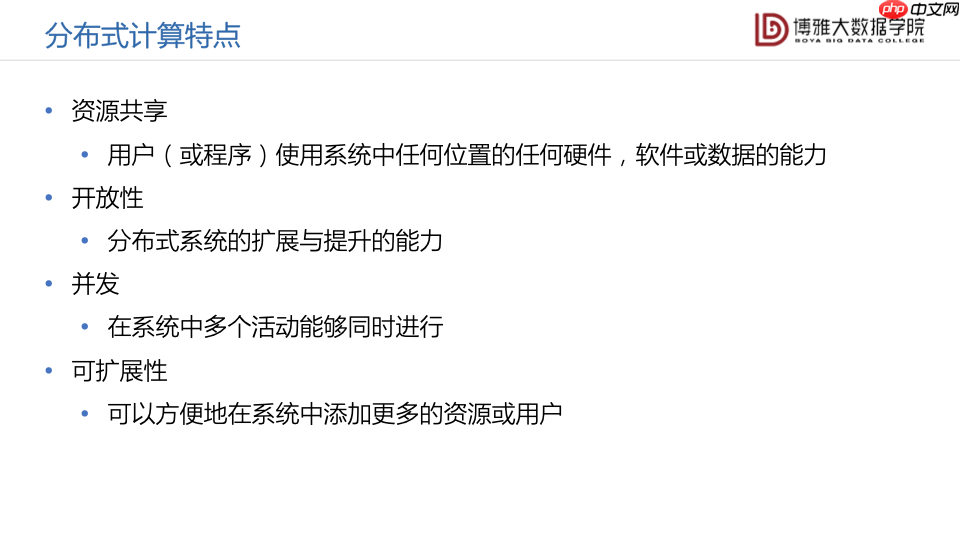
资源共享,用户或程序可以使用系统中任何位置的任何硬件、软件或数据开放性,分布式系统具有良好的扩展与提升能力并发性,在系统中多个活动可以同时进行良好的可扩展性,用户可以方便地在系统中添加更多的资源,系统也可以方便地支持更多的用户
容错性也是分布式计算所独有的一个特性。对于分布式系统来说,某一台计算机或某一个局部网络发生故障,不会影响整个系统的正常运行。

实现方式
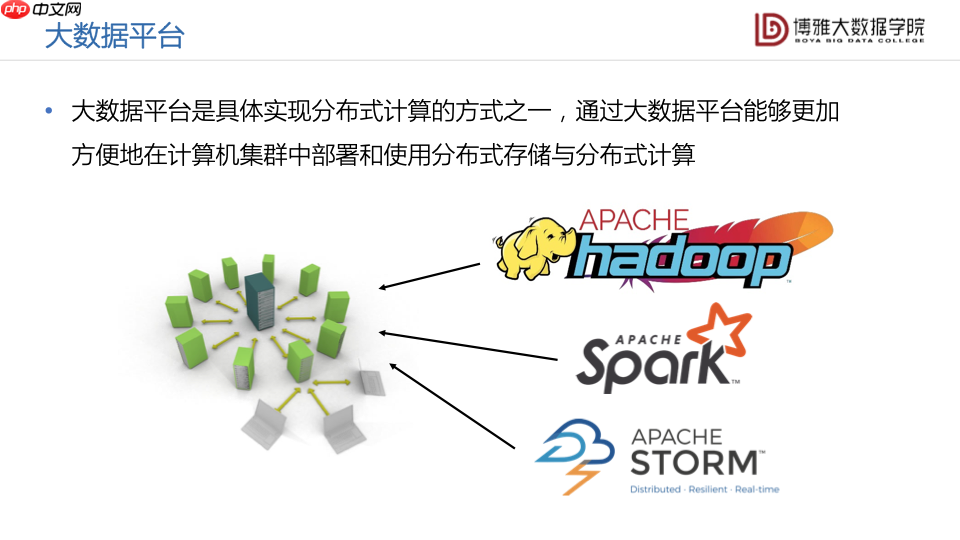
大数据平台是具体实现分布式计算的方式之一。通过大数据平台,用户能够更方便地在计算机集群中部署和使用分布式存储与分布式计算能力。例如,Hadoop、Spark和Storm都是非常好的大数据平台。
基于批处理的大数据平台
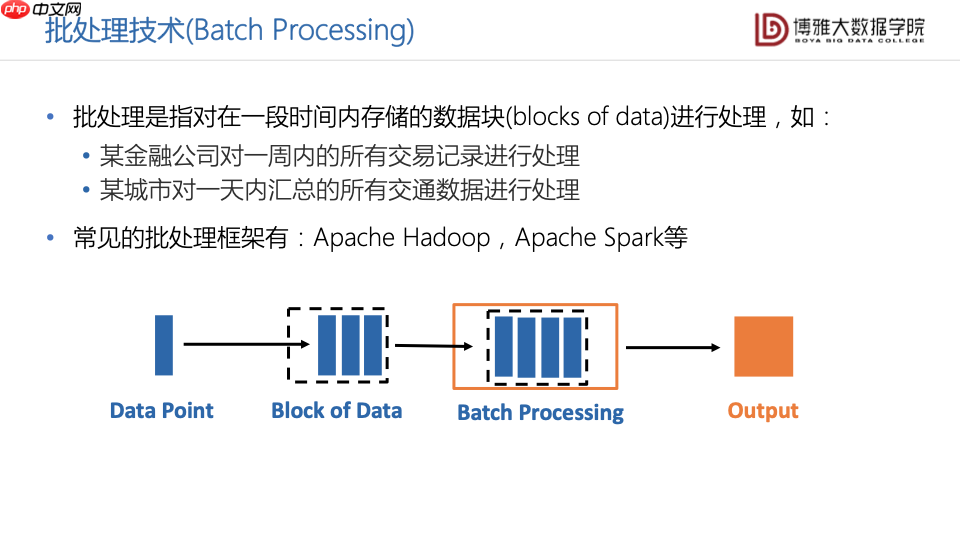
批处理技术适用于对时间要求不高的大规模数据处理场景。批处理技术是对一段时间内存储的数据块进行统一地集中处理。比如,某个金融公司一周内所有的交易记录可以被看作是一个数据块,某个城市一天内汇总的所有的交通数据也可以被看作是一个数据块。简单来说,数据攒了一周、一天或是固定一段时间后再来进行处理,这样的批处理框架包括,Apache Hadoop,Apache Spark等。
Hadoop是Apache软件基金会旗下的一个开源分布式计算平台,为用户提供了系统底层细节透明的分布式基础架构。它是用Java编写的开源的、可伸缩的、有着良好容错性的一个大数据处理框架,并且它可以部署在廉价的计算机集群中。也就是说,我们用几台普通的台式机就可以组成一个小型的Hadoop集群。
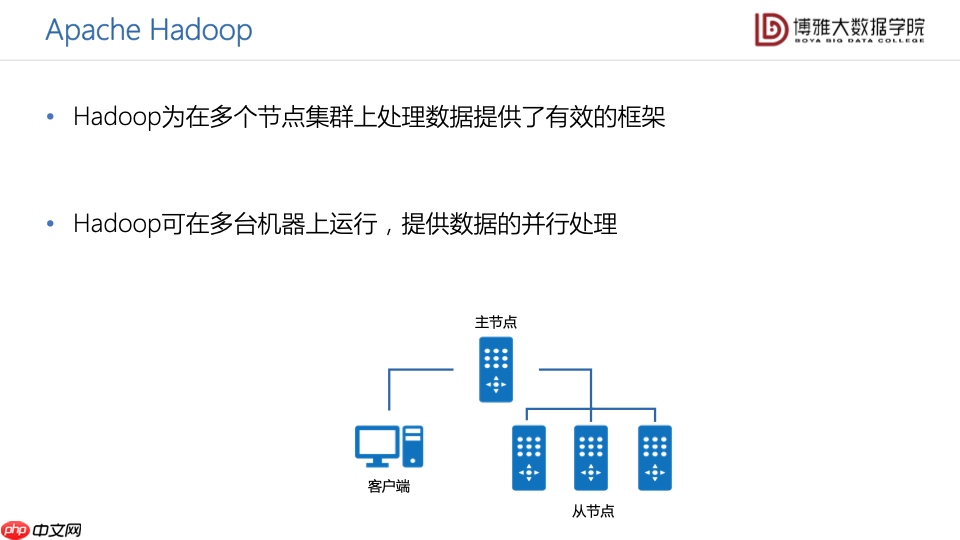
Hadoop为在多个机器上处理数据提供了一个有效的框架,它可以在多台机器上运行,来提供数据的并行处理。如下图所示,我们可以把一台机器设置为主节点,把其它的机器设置为从节点,这样的多台计算机就构成一个小型的Hadoop集群。
Apache Spark是由美国加州伯克利大学的AMP实验室开发的,是专为大规模数据处理而设计的快速通用的计算引擎。用户使用Spark,可以构建大型的、低延迟的数据分析应用程序。

Spark的特点,简单来说就是如闪电般快速。这是因为它在调度上采用了先进的DAG(Directed Acyclic Graph)调度程序,查询上则利用了查询优化器和物理执行引擎等技术。
与Hadoop相比,对100TB的数据进行排序,Hadoop需要2100台机器运行72分钟,而Spark使用207台机器,只需运行23分钟就做完了。再看逻辑回归算法的表现,在Hadoop上,运行需要110秒,而在Spark上只需要0.9秒。由这些数据,我们就可以更直观地看出Spark快如闪电的特点。

基于流处理的大数据平台
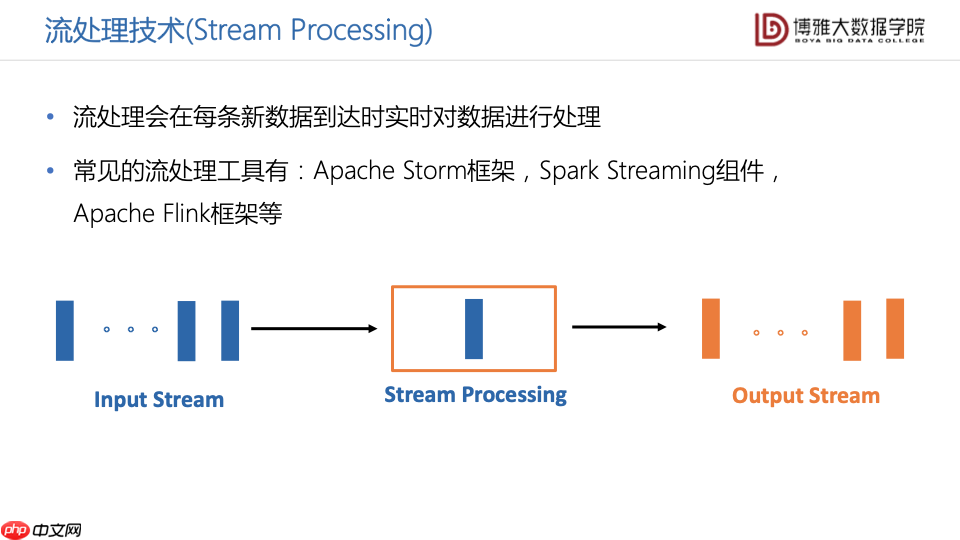
流处理技术指能够在每条新数据到达时,实时地对数据进行处理。与批处理技术不同,在流处理的过程中到达的每一条新数据都不会存储,而是直接进行处理并输出结果,因此这样的技术特别适用于对实时数据处理要求很高的大数据应用场景。常见的流处理工具包括Apache Storm框架,Spark Streaming组件,Apache Flink框架等。
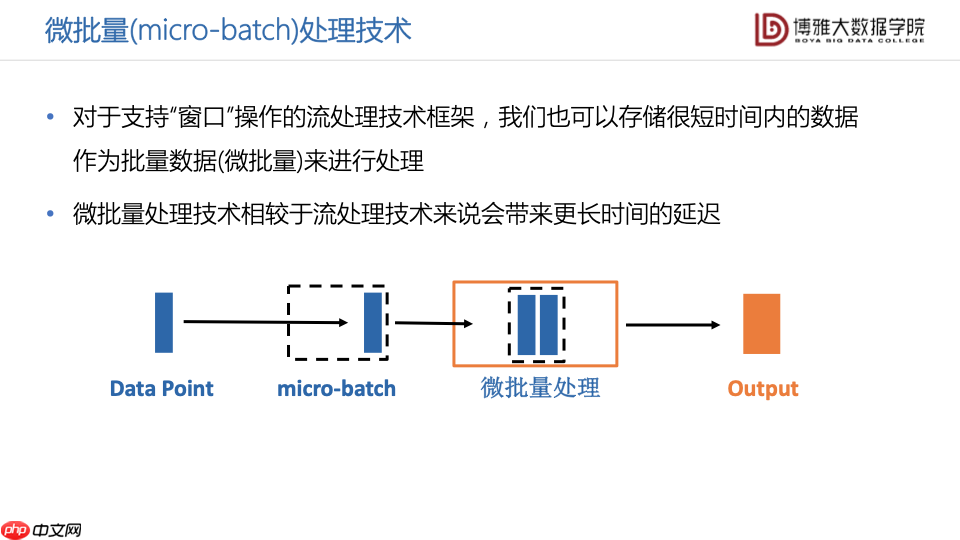
流处理技术的其中一种被称为微批量处理技术。对于需要支持窗口操作的流处理技术框架,我们也可以存储很短时间内的数据,作为批量数据(微批量数据)来进行处理,我们也可以把这里的“微批量”理解为一个很小的数据块。与流处理技术相比,微批量处理技术会带来一定时间的延迟。
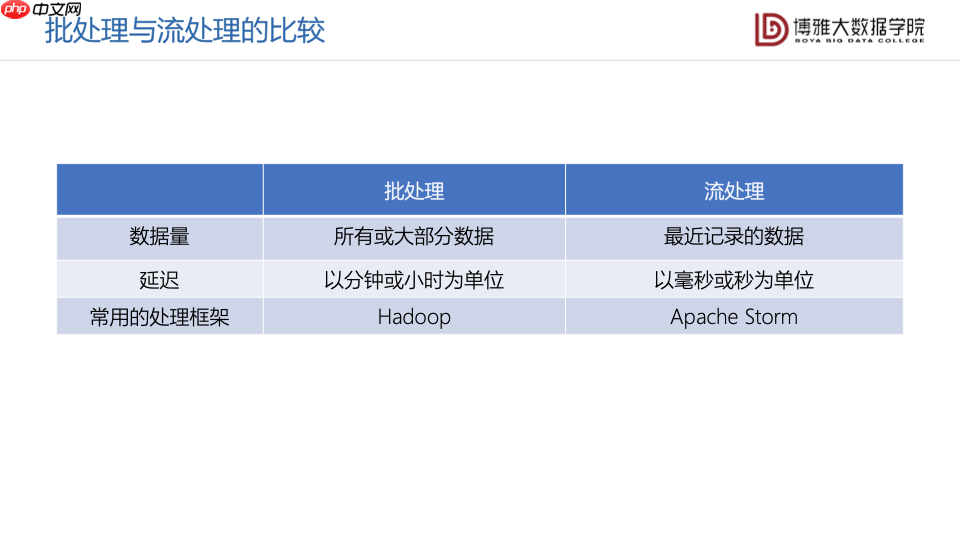
将流处理技术与批处理技术二者相比较:在数据量上,流处理技术处理的是最近记录的数据,而批处理处理的是所有或大部分的数据;在处理延迟上,批处理通常有着以分钟或者小时为单位的延迟,而流处理技术的延迟通常是以毫秒或者秒为单位的;二者的常用处理框架也不相同。
以上就是数据科学通识第九讲:大数据平台的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/127106.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫