答案:实现PHP文件下载需设置正确HTTP头并流式传输文件。首先验证文件存在且可读,使用basename()防止路径遍历,设置Content-Disposition: attachment强制下载,推荐用readfile()或fpassthru()避免内存溢出,大文件需调用set_time_limit(0)并考虑Nginx的X-Accel-Redirect优化性能,文件名含非ASCII字符时应遵循RFC 5987编码,同时校验MIME类型、权限及路径安全,防止安全漏洞。

在PHP在线环境中实现文件下载,核心在于正确配置HTTP响应头,并高效地将文件内容传输给用户。这通常涉及确认文件存在、设置正确的MIME类型、指定下载文件名和文件大小,最后通过流式传输文件数据。这是一个看似简单但细节颇多的过程,处理不当可能会引发安全漏洞或性能问题。
解决方案
要实现文件下载功能,我们首先需要一个PHP脚本来处理下载请求。这个脚本的核心任务是读取服务器上的文件,然后将其作为HTTP响应体发送给客户端浏览器。这里有几个关键的HTTP头需要设置,它们告诉浏览器如何处理接收到的数据。
最基础的下载逻辑大致如下:
这段代码展示了基本流程。
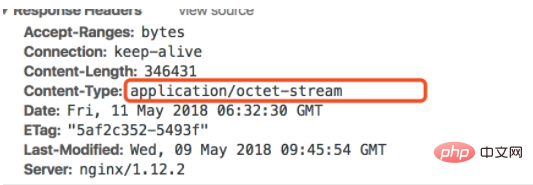
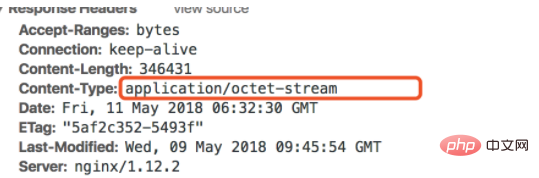
Content-Type
头告诉浏览器文件类型,
application/octet-stream
是一个通用的二进制流类型,适用于大多数未知文件类型或强制下载。如果你明确知道文件类型,比如PDF文件,使用
application/pdf
会更好。
Content-Disposition: attachment; filename="..."
是强制浏览器下载而不是在浏览器中打开的关键。这里还需要注意文件名编码,尤其是当文件名包含非ASCII字符时,可能需要对
filename
参数进行URL编码或使用RFC 5987的编码方式,但通常现代浏览器处理得还不错。
立即学习“PHP免费学习笔记(深入)”;
readfile()
函数是一个非常方便的PHP内置函数,它直接将文件内容输出到输出缓冲区。对于非常大的文件,它通常比
file_get_contents()
然后
echo
更高效,因为它不会一次性将整个文件读入内存。不过,对于超大文件,或者需要更精细控制(比如限速)的场景,我们可能需要使用
fopen()
和
fpassthru()
或者循环读取文件块的方式。
确保文件下载安全性的最佳实践有哪些?
在实现文件下载功能时,安全性绝对是重中之重,一个不小心就可能给服务器留下巨大的漏洞。我个人在处理这类功能时,最先考虑的就是如何防止恶意用户通过下载路径访问到不该访问的文件,比如系统配置文件或者其他用户的私密数据。
首先,也是最关键的,是防止路径遍历(Path Traversal)攻击。这意味着绝不能直接将用户提供的文件名或路径拼接起来去访问文件。例如,如果用户请求下载
../etc/passwd
,而你的代码直接使用了这个路径,那后果不堪设想。我的做法通常是:
限制文件存放目录:所有可供下载的文件都应该放在一个专门的、与Web根目录隔离的目录中。
使用
basename()
或
realpath()
:在处理用户提供的文件名时,始终使用
basename()
来只获取文件名部分,丢弃任何路径信息。如果文件路径是基于一个安全基目录构建的,
realpath()
可以用来验证最终解析的路径是否仍在允许的基目录内。例如:
$baseDir = '/path/to/secure/downloads/';$userRequestedFile = $_GET['file']; // 用户可能传入 'report.pdf' 或 '../config.ini'$safeFileName = basename($userRequestedFile); // 确保只剩下 'report.pdf' 或 'config.ini'$filePath = $baseDir . $safeFileName;// 更严格的检查:确保解析后的路径确实在允许的目录内$realPath = realpath($filePath);if (strpos($realPath, realpath($baseDir)) !== 0) { // 路径不在允许的范围内,拒绝访问 http_response_code(403); die('非法文件请求。');}
白名单验证:如果可下载的文件数量有限且已知,可以维护一个允许下载的文件名白名单。用户请求的文件名必须在这个白名单中。
权限验证:在下载任何文件之前,务必验证当前用户是否有权限下载该文件。这通常涉及到用户会话、数据库查询等。比如,如果是一个用户上传的文件,确保只有上传者或管理员才能下载。
其次,文件类型验证也很重要。虽然
Content-Type
头可以告知浏览器文件类型,但这并不意味着服务器就不需要验证。恶意用户可能会上传一个伪装成图片的可执行脚本,然后试图通过某种方式诱导下载并执行。在文件上传时就应该进行严格的MIME类型和文件内容检查,确保只有允许的文件类型才能被上传和下载。
最后,错误处理和日志记录也不可忽视。当文件不存在、权限不足或发生其他错误时,应该返回恰当的HTTP状态码(如404 Not Found, 403 Forbidden),并避免向用户暴露过多的服务器内部信息。同时,将下载请求、成功与失败记录到日志中,这对于审计和发现潜在的攻击行为非常有帮助。
如何处理大文件下载以避免内存溢出或超时?
处理大文件下载确实是个挑战,尤其是在PHP这种默认会限制脚本执行时间和内存使用的环境中。我记得有一次尝试直接用
file_get_contents()
读取一个几百MB的文件,结果直接内存溢出,服务器也卡死了。所以,对于大文件,常规思路是行不通的,需要一些特殊处理。
核心思想是流式传输(Streaming),而不是一次性将整个文件加载到内存。PHP提供了几个函数来帮助我们实现这一点:
readfile()
函数:前面提到的
readfile()
其实就是为流式传输设计的。它直接将文件内容从磁盘读取并写入输出缓冲区,而不会将整个文件加载到PHP脚本的内存中。对于大多数情况,它是一个非常高效且内存友好的选择。
fopen()
配合
fpassthru()
或循环读取:如果需要更细粒度的控制,比如在传输过程中加入进度条、限速或加密等,
fopen()
打开文件句柄,然后使用
fpassthru()
是另一个好选择。
fpassthru()
会从文件指针开始,将所有剩余的数据直接输出到输出缓冲区,同样不会将整个文件加载到内存。
$fileHandle = fopen($filePath, 'rb');if ($fileHandle) { // 清除输出缓冲区,确保文件内容直接发送 ob_clean(); flush(); fpassthru($fileHandle); fclose($fileHandle);} else { http_response_code(500); die('无法打开文件。');}
或者,如果需要更灵活的控制(例如,分块读取并处理),可以使用循环:
$fileHandle = fopen($filePath, 'rb');if ($fileHandle) { ob_clean(); flush(); $bufferSize = 4096; // 每次读取4KB while (!feof($fileHandle)) { echo fread($fileHandle, $bufferSize); // 每次读取并输出后,可以flush缓冲区,防止浏览器长时间等待 flush(); } fclose($fileHandle);}
这种循环读取的方式可以让你在每次发送数据块后执行其他操作,比如更新下载进度。
处理脚本执行时间限制:PHP默认的
max_execution_time
通常是30秒或60秒。对于大文件下载,这显然不够。你需要通过
set_time_limit(0)
来取消时间限制,或者设置一个足够大的值。同时,
ignore_user_abort(true)
可以确保即使客户端断开连接,脚本也能继续执行,这在某些清理或日志记录场景下很有用,尽管对于直接下载可能不是必须的。
set_time_limit(0); // 取消脚本执行时间限制ignore_user_abort(true); // 即使客户端中断连接,脚本也继续执行
当然,这些设置需要在脚本的开头进行。
服务器层面的优化:除了PHP脚本,Web服务器(如Apache或Nginx)的配置也至关重要。Nginx在处理静态文件下载方面效率极高,可以配置它直接处理大文件下载,而无需PHP介入。这通常通过
X-Accel-Redirect
或
X-Sendfile
头部实现。当PHP脚本验证完用户权限后,只需发送一个特殊的HTTP头给Nginx,Nginx就会接管文件传输,这大大减轻了PHP的负担,并提升了性能。这是一种非常推荐的大文件下载方案。
总之,处理大文件下载的关键在于避免一次性加载,利用流式传输,并合理配置PHP和Web服务器。
在不同浏览器和操作系统下,文件下载行为可能有哪些差异及应对策略?
虽然现代浏览器在处理文件下载方面已经相当标准化,但偶尔还是会遇到一些“历史遗留问题”或者平台特有的行为差异。我曾遇到过因为文件名编码问题导致在某些浏览器下文件名乱码的情况,或者在移动端下载时体验不佳的问题。
文件名编码问题:
问题:当文件名包含非ASCII字符(如中文、日文等)时,直接在
Content-Disposition
头中使用这些字符,在某些旧浏览器或特定编码环境下可能会出现乱码。策略:最稳妥的方式是遵循RFC 5987标准,为
filename
参数提供多语言支持。这通常意味着提供一个UTF-8编码的版本,并可选地提供一个ASCII编码的版本作为备用。
$fileName = "我的文件.pdf"; // 假设这是UTF-8文件名$encodedFileName = rawurlencode($fileName); // URL编码header('Content-Disposition: attachment; filename="' . $fileName . '"; filename*=UTF-8'''. $encodedFileName . '"');
filename*
部分是RFC 5987的扩展,它允许指定字符集。现代浏览器通常会优先使用
filename*
。如果你的目标用户群体可能使用非常老的浏览器,你甚至可以考虑将文件名限制为ASCII字符,或者在服务器端对文件名进行转译。
MIME类型识别:
问题:虽然我们通常使用
application/octet-stream
作为通用MIME类型,但有时浏览器会根据文件扩展名尝试“猜测”实际类型,这可能导致一些不一致。如果服务器提供的MIME类型不准确,浏览器可能会错误地处理文件(例如,尝试在浏览器中打开本应下载的文件)。策略:尽可能提供准确的
Content-Type
。PHP的
mime_content_type()
或
finfo_open()
可以帮助你根据文件内容而不是扩展名来确定MIME类型,这更为可靠。
// 使用 Fileinfo 扩展获取 MIME 类型if (class_exists('finfo')) { $finfo = new finfo(FILEINFO_MIME_TYPE); $mimeType = $finfo->file($filePath);} else { // 备用方案,可能不那么准确 $mimeType = mime_content_type($filePath);}if ($mimeType) { header('Content-Type: ' . $mimeType);} else { header('Content-Type: application/octet-stream');}
移动端浏览器的行为:
问题:在某些移动浏览器上,下载行为可能与桌面浏览器有所不同。例如,一些移动浏览器可能会在下载完成后自动打开文件,或者需要用户手动确认下载。有时,直接点击下载链接可能会导致浏览器崩溃或无响应,尤其是在处理大文件时。策略:这更多是用户体验而非技术实现的问题。确保你的下载链接在移动端UI中清晰可见。对于大文件,可以考虑提供下载进度指示,或者引导用户使用支持断点续传的下载管理器(虽然这通常超出了PHP直接下载的范畴)。在某些极端情况下,为了兼容性,可能需要根据
User-Agent
头来调整某些响应行为,但这通常不推荐,因为它增加了复杂性且容易出错。
HTTPS与HTTP混合内容警告:
问题:如果你的网站是HTTPS,但下载链接指向HTTP资源,浏览器可能会发出混合内容警告,甚至阻止下载。策略:确保所有下载链接都使用HTTPS,或者至少与网站的协议保持一致。
总的来说,虽然我们不能控制浏览器或操作系统的所有行为,但通过遵循标准、提供准确的HTTP头信息以及进行充分的测试,可以最大程度地确保文件下载功能在各种环境下都能正常工作。
以上就是如何在在线PHP环境中实现文件下载功能?有哪些关键步骤?的详细内容,更多请关注php中文网其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/1293187.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫