
为什么 spark 慢?
从一个引人注目的标题“spark 为什么这么慢?”开始,值得注意的是,称 spark“慢”可能意味着多种含义。聚合速度慢吗?数据加载?存在不同的情况。此外,“spark”是一个广泛的术语,其性能取决于编程语言和使用上下文等因素。因此,在深入讨论之前,让我们将标题改进得更加精确。
由于我主要在 databricks 上使用 spark 和 python,因此我将进一步缩小范围。
优化后的标题将是:
“spark 的第一印象:‘听说它很快,但为什么感觉很慢?’初学者的视角”
写作动机(随意的想法)
作为广泛使用 pandas、numpy 和机器学习库的人,我钦佩 spark 通过并行和分布式处理处理大数据的能力。当我最终在工作中使用 spark 时,我对它看起来比 pandas 慢的场景感到困惑。不确定出了什么问题,我发现了一些见解并想与大家分享。
你的火花什么时候会变慢?
在进入主题之前
我们简单介绍一下spark的基本架构。
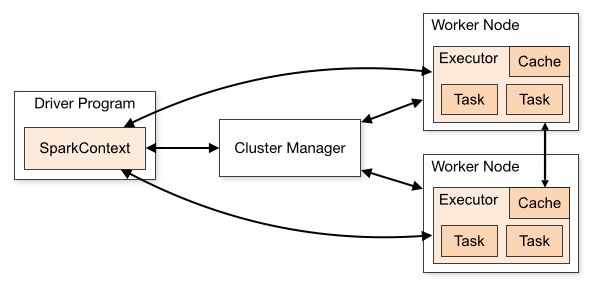
(集群模式概述)
spark 集群由执行实际处理的 工作节点和协调和计划执行的驱动程序节点组成。这种架构会影响下面讨论的所有内容,因此请记住这一点。
现在,进入要点。
1. 数据集不够大
spark 针对大规模数据处理进行了优化,但它也可以处理小型数据集。然而,看看这个基准:
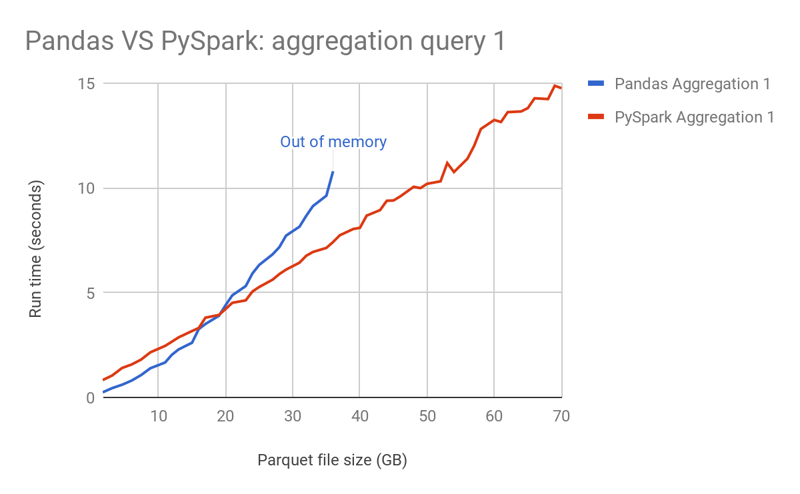
(在单节点机器上对 apache spark 进行基准测试)
结果表明,对于 15gb 以下的数据集,pandas 在聚合任务中优于 spark。为什么?简而言之,spark 优化的开销超过了小数据集的好处。
该链接显示了 spark 并不慢的情况,但这些情况通常处于本地集群模式。对于独立设置,由于节点之间的网络通信开销,较小的数据集可能是一个缺点。
pandas:在一台机器上处理内存中的所有内容,无需网络或存储 i/o。spark:使用 rdd(弹性分布式数据集),涉及 workers 之间的网络通信(如果分布式),并会在组织数据以进行并行处理时产生开销。
2. 理解惰性求值
spark 采用惰性求值,这意味着转换不会立即执行,而是推迟到某个操作(例如收集、计数、显示)触发计算为止。
示例(熊猫):
df = spark.read.table("tpch.lineitem").limit(1000).topandas()df["l_tax_percentage"] = df["l_tax"] * 100for l_orderkey, group_df in df.groupby("l_orderkey"): print(l_orderkey, group_df["l_tax_percentage"].mean())
执行时间:3.04秒
spark 中的等效项:
from pyspark.sql import functions as fsdf = spark.read.table("tpch.lineitem").limit(1000)sdf = sdf.withcolumn("l_tax_percentage", f.col("l_tax") * 100)for row in sdf.select("l_orderkey").distinct().collect(): grouped_sdf = sdf.filter(f.col("l_orderkey") == row.l_orderkey).groupby("l_orderkey").agg( f.mean("l_tax_percentage").alias("avg_l_tax_percentage") ) print(grouped_sdf.show())
执行时间:3分钟后仍在运行。
为什么?
惰性求值:所有转换都会排队,并且仅在表演等动作期间执行。driver 到 worker 的通信:收集和显示等操作涉及从 workers 到 driver 的数据传输,导致延迟。
spark 代码在 pandas 中有效地执行了此操作:
for l_orderkey, group_df in df.groupby("l_orderkey"): df["l_tax_percentage"] = df["l_tax"] * 100 print(l_orderkey, group_df["l_tax_percentage"].mean())
通过使用 spark 的缓存或重构逻辑以最大程度地减少重复计算来避免此类模式。
3. 注意随机播放
https://spark.apache.org/docs/latest/rdd-programming-guide.html#shuffle-operations
随机播放 当数据在 workers 之间重新分配时发生,通常是在 groupbykey、join 或重新分区等操作期间。随机播放可能会很慢,原因是:
节点之间的网络通信。跨分区数据的全局排序和聚合。
例如,拥有更多 worker 并不总能提高洗牌期间的性能。
32gb x 8 workers 可能比 64gb x 4 workers 慢,因为较少的 workers 会减少节点间通信。
结论
您觉得这有帮助吗?如果有效使用,spark 是一个出色的工具。除了加速大规模数据处理之外,spark 还以其可扩展的资源管理而大放异彩,尤其是在云中。
尝试 spark 来优化您的数据运营和管理!
以上就是为什么 Spark 慢?的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/1354566.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 
























