
在过去的几年里,变形金刚已经改变了机器学习中的 NLP 领域。 GPT 和 BERT 等模型在理解和生成人类语言方面树立了新的基准。现在同样的原理也被应用到计算机视觉领域。

在过去的几年里,变形金刚已经改变了机器学习中的 NLP 领域。 GPT 和 BERT 等模型 在理解和生成人类语言方面树立了新的基准。 现在同样的原理也被应用到计算机视觉领域。计算机视觉领域的最新发展是视觉 变压器或 ViT。正如论文“An Image is Worth 16×16 Words: Transformers for Image Recognition at Scale”中详细介绍的, ViT 和基于 Transformer 的模型旨在取代卷积 神经网络(CNN)。Vision Transformers 是解决计算机问题的全新方式 想象。而不是依赖传统的卷积神经网络 (CNN)几十年来一直是图像相关任务的支柱, ViT 使用 Transformer 架构来处理图像。他们对待 图像补丁就像句子中的单词一样,允许模型学习 这些补丁之间的关系,就像它学习上下文中的上下文一样 文本段落。
与 CNN 不同,ViT 将输入图像划分为补丁,然后将它们序列化 转化为向量,并使用矩阵降低其维度 乘法。然后,变压器编码器将这些向量处理为 令牌嵌入。在本文中,我们将探讨视觉转换器和 它们与卷积神经网络的主要区别。是什么让 他们特别有趣的是他们了解全球的能力 图像中的模式,这是 CNN 难以解决的问题。

什么是视觉转换器?
视觉转换器使用注意力和转换器的概念来 处理图像——这类似于自然语言中的转换器 处理(NLP)上下文。然而,该图像不是使用标记,而是 分成补丁并作为线性嵌入序列提供。这些 补丁的处理方式与 NLP 中处理标记或单词的方式相同。
ViT 不是同时查看整个图片,而是进行剪切 将图像分成小块,就像拼图游戏一样。每一块都经过翻转 转化为描述其特征的数字列表(向量),然后 该模型会查看所有部件并找出它们之间的关系 彼此使用变压器机制。
与 CNN 不同,ViT 的工作原理是在 用于检测特定特征的图像,例如边缘图案。这是 卷积过程非常类似于打印机扫描 图像。这些滤镜滑过整个图像并突出显示 显着特征。然后网络堆叠多层 这些过滤器逐渐识别更复杂的模式。
使用 CNN,池化层可以减小特征图的大小。这些 层分析提取的特征以使预测有用 图像识别、目标检测等。然而,CNN 有一个固定的 感受野,从而限制了远程建模的能力
CNN 如何查看图像?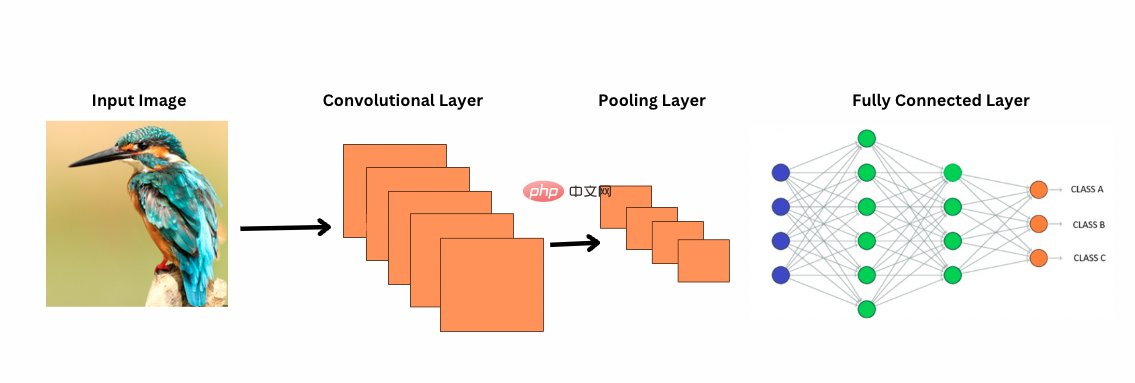
ViT,尽管有更多参数,但使用自注意力机制 为了更好的特征表示并减少对更深层次的需求。 CNN 需要更深层次的架构才能实现类似的效果 表征能力,这会导致计算成本增加。
此外,CNN 无法捕获全局级别的图像模式,因为 他们的过滤器专注于图像的局部区域。要了解 整个图像或远程关系,CNN 依赖于堆叠许多层 并汇集,扩大视野。然而,这个过程可以 在逐步聚合细节时会丢失全局信息。
ViT,另一方面,将图像划分为多个补丁 被视为单独的输入标记。使用 self-attention,ViT 进行比较 同时所有补丁并了解它们之间的关系。这让他们 捕获整个图像的模式和依赖关系,而无需 一层一层地构建它们。
什么是归纳偏差?
在进一步讨论之前,了解归纳偏差的概念很重要。 归纳偏差是指模型对数据做出的假设 结构;在训练过程中,这有助于模型更加泛化 减少偏见。在 CNN 中,归纳偏差包括:
局部性:图像中的特征(如边缘或纹理)位于小区域内。二维邻域结构:附近的像素更有可能出现是相关的,因此过滤器对空间相邻区域进行操作。平移等方差:在图像的一个部分中检测到的特征,例如边缘,如果它们出现在其他部分,则保留相同的含义。
这些偏差使得 CNN 对于图像任务非常高效,因为它们 本质上是为了利用图像的空间和结构 属性。
视觉变换器 (ViT) 的图像特定归纳偏差比 CNN 少得多。在 ViTs 中:
全局处理:自注意力层在 整个图像,使模型捕捉全局关系 不受局部区域限制的依赖关系。最小 2D 结构:图像的 2D 结构 仅在开始时使用(当图像被划分为补丁时) 以及在微调期间(调整不同位置的嵌入) 决议)。与 CNN 不同,ViT 不假设附近的像素是 必然相关。学习的空间关系:位置嵌入 ViT 在初始化时不编码特定的 2D 空间关系。 相反,模型从数据中学习所有空间关系
Vision Transformers 如何工作
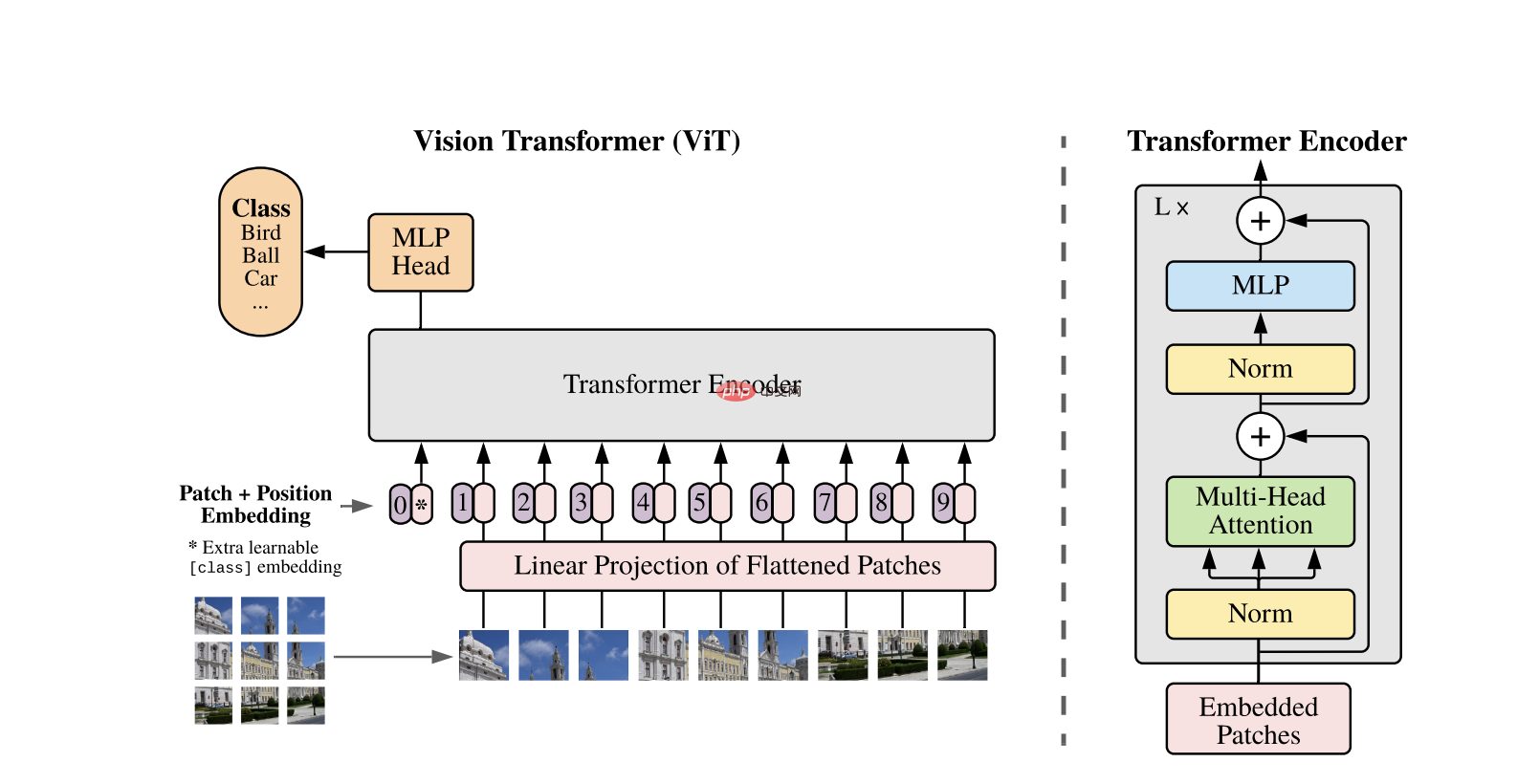
Vision Transformers 使用标准 Transformer 架构 专为一维文本序列而开发。为了处理 2D 图像,它们是 分为固定大小的较小块,例如 P P 像素,其中 被展平为向量。如果图像的尺寸为 H、W 和 C 通道,补丁总数为 N = H W / P P 有效 Transformer 的输入序列长度。这些扁平的补丁是 然后线性投影到固定维空间 D 中,称为补丁嵌入。
一个特殊的可学习令牌,类似于 BERT 中的 [CLS] 令牌,是 添加到补丁嵌入序列之前。该令牌学习一个 稍后用于分类的全局图像表示。 此外,位置嵌入被添加到补丁嵌入中以 对位置信息进行编码,帮助模型理解空间 图像的结构。
嵌入序列通过 Transformer 编码器传递,该编码器在两个主要操作之间交替:多头自注意力 (MSA) 和前馈神经网络(也称为 MLP 块)。每层都包含层归一化(LN) 在这些操作之前应用并添加剩余连接 之后要稳定训练。 Transformer 编码器的输出, 特别是 [CLS] 令牌的状态,用作图像的 表示。
将一个简单的头添加到最终的 [CLS] 标记中以进行分类 任务。在预训练期间,这个头是一个小型多层感知器 (MLP),而在微调时,它通常是单个线性层。这 架构允许 ViT 有效地建模全球关系 在补丁之间并充分利用图像自注意力的能力 理解。
在混合Vision Transformer模型中,而不是直接划分 原始图像分成补丁,输入序列来自特征图 由 CNN 生成。 CNN首先处理图像,提取 有意义的空间特征,然后用于创建补丁。 这些补丁被展平并投影到固定维度的空间中 使用与标准视觉相同的可训练线性投影 变形金刚。这种方法的一个特例是使用大小的补丁 1×1,其中每个补丁对应于单个空间位置 CNN 的特征图。
在这种情况下,特征图的空间维度为 展平,并将结果序列投影到 变压器的输入维度。与标准 ViT 一样, 添加分类标记和位置嵌入以保留 位置信息并实现全局图像理解。这 混合方法利用 CNN 的局部特征提取优势 同时将它们与全球建模能力相结合 变形金刚。
代码演示
这里是有关如何使用视觉变形金刚的代码块图片。
# Install the necessary libraries pip install -q transformers
from transformers import ViTForImageClassification from PIL import Image from transformers import ViTImageProcessor
import requests import torch
# Load the model and move it to ‘GPU’ device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')model = ViTForImageClassification.from_pretrained('google/vit-base-patch16-224') model.to(device)
# Load the image to perform predictions url = 'link to your image' image = Image.open(requests.get(url, stream=True).raw)processor = ViTImageProcessor.from_pretrained('google/vit-base-patch16-224') inputs = processor(images=image, return_tensors="pt").to(device) pixel_values = inputs.pixel_values # print(pixel_values.shape)
ViT 模型处理图像。它包括一个类似 BERT 的编码器和一个 线性分类头位于最终隐藏状态的顶部 [CLS] 令牌。
with torch.no_grad(): outputs = model(pixel_values) logits = outputs.logits# logits.shapeprediction = logits.argmax(-1) print("Predicted class:", model.config.id2label[prediction.item()])
这里是 使用 PyTorch 的基本 Vision Transformer (ViT) 实现。这 代码包括核心组件:补丁嵌入、位置编码、 和 Transformer 编码器。这可以用于简单分类 任务。
import torchimport torch.nn as nnimport torch.nn.functional as Fclass VisionTransformer(nn.Module): def __init__(self, img_size=224, patch_size=16, num_classes=1000, dim=768, depth=12, heads=12, mlp_dim=3072, dropout=0.1): super(VisionTransformer, self).__init__() # Image and patch dimensions assert img_size % patch_size == 0, "Image size must be divisible by patch size" self.num_patches = (img_size // patch_size) ** 2 self.patch_dim = (3 * patch_size ** 2) # Assuming 3 channels (RGB) # Layers self.patch_embeddings = nn.Linear(self.patch_dim, dim) self.position_embeddings = nn.Parameter(torch.randn(1, self.num_patches 1, dim)) self.cls_token = nn.Parameter(torch.randn(1, 1, dim)) self.dropout = nn.Dropout(dropout) # Transformer Encoder self.transformer = nn.TransformerEncoder( nn.TransformerEncoderLayer(d_model=dim, nhead=heads, dim_feedforward=mlp_dim, dropout=dropout), num_layers=depth ) # MLP Head for classification self.mlp_head = nn.Sequential( nn.LayerNorm(dim), nn.Linear(dim, num_classes) ) def forward(self, x): # Flatten patches and embed batch_size, channels, height, width = x.shape patch_size = height // int(self.num_patches ** 0.5) x = x.unfold(2, patch_size, patch_size).unfold(3, patch_size, patch_size) x = x.contiguous().view(batch_size, 3, patch_size, patch_size, -1) x = x.permute(0, 4, 1, 2, 3).flatten(2).permute(0, 2, 1) x = self.patch_embeddings(x) # Add positional embeddings cls_tokens = self.cls_token.expand(batch_size, -1, -1) x = torch.cat((cls_tokens, x), dim=1) x = x self.position_embeddings x = self.dropout(x) # Transformer Encoder x = self.transformer(x) # Classification Head x = x[:, 0] # CLS token return self.mlp_head(x)# Example usageif __name__ == "__main__": model = VisionTransformer(img_size=224, patch_size=16, num_classes=10, dim=768, depth=12, heads=12, mlp_dim=3072) print(model) dummy_img = torch.randn(8, 3, 224, 224) # Batch of 8 images, 3 channels, 224x224 size preds = model(dummy_img) print(preds.shape) # Output: [8, 10] (Batch size, Number of classes)
以上就是Vision Transformers (ViTs):使用 Transformer 模型的计算机视觉的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/1355715.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 




























