
下面是关于zookeeper-3.4.10的安装和配置的详细指南:
环境准备
我使用了4台虚拟机,主机名分别为hadoop01、hadoop02、hadoop03和hadoop04。要准备好虚拟机集群,可以参考以下文章:在Windows中安装一台Linux虚拟机,以及通过已有的虚拟机克隆四台虚拟机。zookeeper安装包的下载地址为:https://www.php.cn/link/371783b1f48b7a4bf47375ec0e7e3aac。
角色说明
hadoop01:可以是leader或followerhadoop02:可以是leader或followerhadoop03:可以是leader或followerhadoop04:observer
leader:可以接受所有读写请求,并处理所有读写请求。集群中的所有写数据请求由leader处理。
follower:可以接受所有读写请求,但只处理读数据请求,写数据请求则转发给leader。
observer:与follower唯一的区别是没有选举权和被选举权。
由于hadoop01、hadoop02和hadoop03具有选举权,它们的角色会根据情况变化。如果leader宕机,会重新选举新的leader。hadoop04作为observer,没有选举和被选举权,只负责处理请求。
注意:zookeeper集群中可以参与选举的节点数量应为奇数,因为zookeeper使用半数机制进行选举,即超过半数的节点投票给某个节点,该节点成为新的leader。
步骤
(1) 上传到服务器并解压
tar -zxvf zookeeper-3.4.10.tar.gz
(2) 配置环境变量,添加ZOOKEEPER_HOME
vim ~/.bash_profile# 添加以下内容export ZOOKEEPER_HOME=/home/hadoop/apps/zookeeper-3.4.10export PATH=$PATH:$ZOOKEEPER_HOME/bin# 别忘了sourcesource ~/.bash_profile
(3) 配置zoo.cfg文件
进入ZOOKEEPER_HOME/conf目录,复制zoo_sample.cfg文件为zoo.cfg:
cp zoo_sample.cfg zoo.cfg
编辑zoo.cfg文件,如下:
vim zoo.cfg# 集群各节点的心跳时间间隔,保持默认即可(2s)tickTime=2000# 此配置表示,允许follower连接并同步到leader的初始化连接时间# 它以tickTime的倍数来表示# 当超过设置倍数的tickTime时间,则连接失败# 保持默认即可(10次心跳的时间,即20s)initLimit=10# follower与leader通信,从发送请求到接收到响应的等待时间的最大值,保持默认即可,即10s# 如果10s内没有收到响应,本次请求就失败syncLimit=5# zookeeper的数据存放的位置,默认是/tmp/zookeeper,一定要改,因为tmp目录会不定时清空dataDir=/home/hadoop/zkdata# 客户端连接的端口号,保持默认即可clientPort=2181# 以下内容手动添加# server.id=主机名:心跳端口:选举端口# 注意:这里给每个节点定义了id,这些id写到配置文件中# id为1-255之间的任意的不重复的数字,一定要记得每个节点的id的对应关系server.1=hadoop01:2888:3888server.2=hadoop02:2888:3888server.3=hadoop03:2888:3888server.4=hadoop04:2888:3888:observer
(4) 同步配置
我是在hadoop01节点中进行解压配置的,所以将配置文件分发给其他3个节点:
scp -r /home/hadoop/apps/zookeeper-3.4.10 hadoop02:/home/hadoop/apps/scp -r /home/hadoop/apps/zookeeper-3.4.10 hadoop03:/home/hadoop/apps/scp -r /home/hadoop/apps/zookeeper-3.4.10 hadoop04:/home/hadoop/apps/
给其他节点配置ZOOKEEPER_HOME环境变量。
(5) 在配置的dataDir目录下新建myid文件,并写入id
我配置的dataDir=/home/hadoop/zkdata,所以:
mkdir -p /home/hadoop/zkdatacd /home/hadoop/zkdata# echo 命令会先创建文件再写入echo 1 > myid
注意:我配置的集群id信息为:
server.1=hadoop01:2888:3888server.2=hadoop02:2888:3888server.3=hadoop03:2888:3888server.4=hadoop04:2888:3888:observer
因此,在hadoop01的dataDir下的myid文件中的id就是1,hadoop02的dataDir下的myid文件中的id就是2,以此类推,一定要与配置文件中的配置相对应!
(6) 启动集群并验证
启动集群(每个节点都要启动):
zkServer.sh start
查看每个节点的状态:
zkServer.sh status
hadoop01、hadoop02、hadoop03的角色一定是leader或者follower,hadoop04一定是observer。
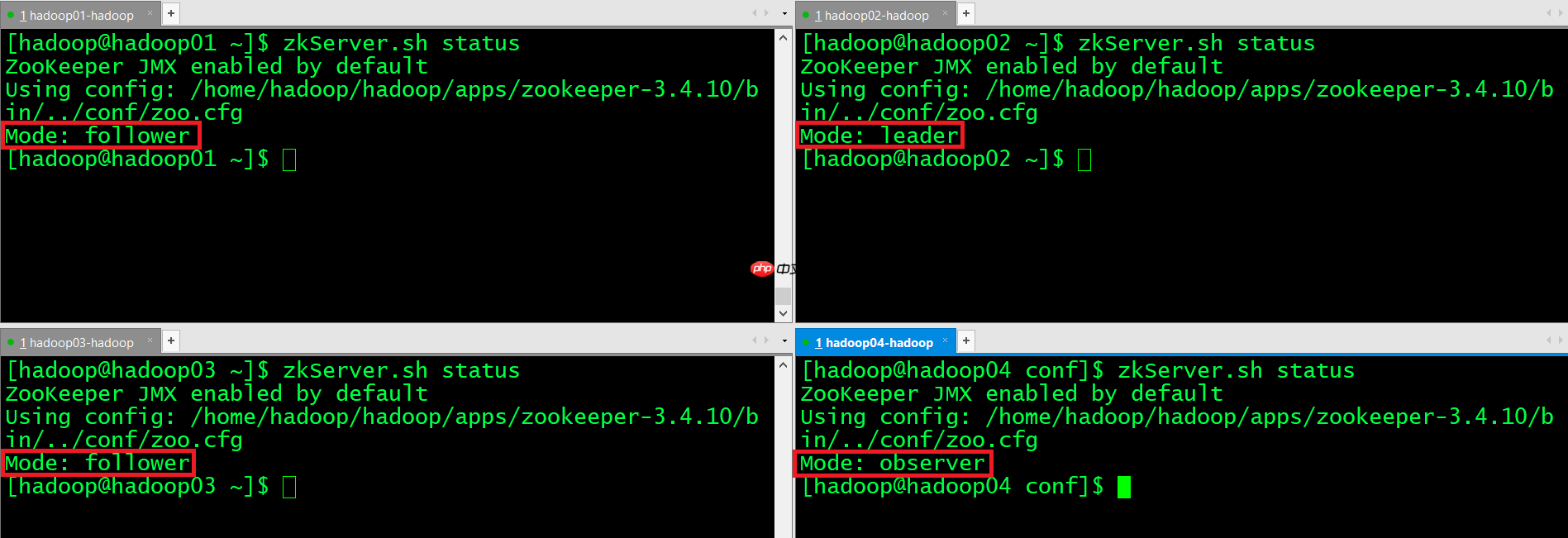
zookeeper集群安装配置成功。
至此,zookeeper集群安装配置成功!
说明
给节点配置的id为1-255之间的一个数字,那么当zookeeper集群的数量超过255怎么办?
答:zookeeper集群的性能会随着节点数的增多达到峰值,再增加节点数量,性能会急剧下降,通常来说,超过20多台节点后性能就会下降,所以,即使可以一直给节点编号,也不建议在zookeeper集群中配置太多的节点。
以上就是zookeeper-3.4.10的安装配置的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/146077.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 















![Go语言接口与切片:如何识别和操作[]interface{}](https://cdn.chuangxiangniao.com/www/2025/12/176369856569294-1.jpg?imageMogr2/crop/480x300/gravity/center)












