
环境准备
我使用的是CentOS-6.6版本的4个虚拟机,主机名为hadoop01、hadoop02、hadoop03、hadoop04。集群将由hadoop用户搭建(在生产环境中,root用户通常不可随意使用)。关于虚拟机的安装,可以参考以下两篇文章:在Windows中安装一台Linux虚拟机,以及通过已有的虚拟机克隆四台虚拟机。Zookeeper集群参考zookeeper-3.4.10的安装配置。spark安装包的下载地址为:https://www.php.cn/link/fee801ecfba08d39cd8ebed9fdcbe7e9。
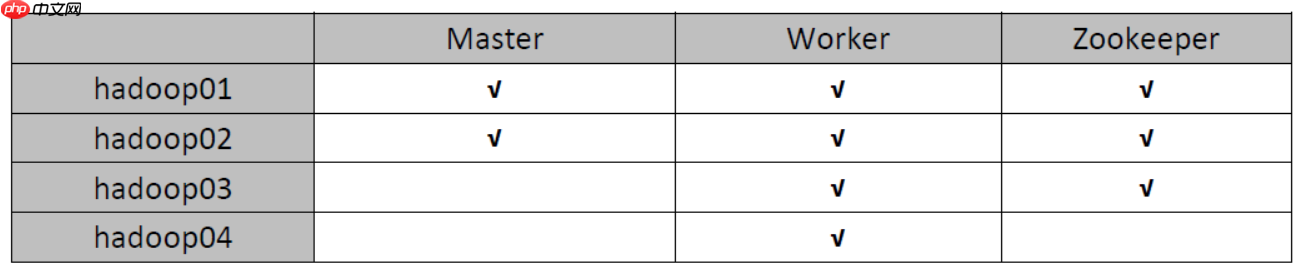
集群规划
具体步骤
(1) 将安装包上传到hadoop01服务器并解压
[hadoop@hadoop01 soft]$ tar zxvf spark-2.2.0-bin-hadoop2.7.tgz -C /home/hadoop/apps/# 解压后如果觉得安装目录名称太长,可以修改一下[hadoop@hadoop01 soft]$ cd /home/hadoop/apps/[hadoop@hadoop01 apps]$ mv spark-2.2.0-bin-hadoop2.7 spark-2.2.0
(2) 修改spark-env.sh配置文件
# 将SPARK_HOME/conf/下的spark-env.sh.template文件复制为spark-env.sh[hadoop@hadoop01 apps]$ cd spark-2.2.0/conf[hadoop@hadoop01 conf]$ mv spark-env.sh.template spark-env.sh# 修改spark-env.sh配置文件,添加如下内容[hadoop@hadoop01 conf]$ vim spark-env.sh # 配置JAVA_HOME,一般来说,不配置也可以,但可能会出现问题,还是配上吧export JAVA_HOME=/usr/local/java/jdk1.8.0_73# 一般来说,spark任务有很大可能性需要从HDFS上读取文件,所以配置上# 如果你的spark只读取本地文件,且不需yarn管理,不用配置export HADOOP_CONF_DIR=/home/hadoop/apps/hadoop-2.7.4/etc/hadoop# 每个Worker最多可以使用的cpu core的个数,我的虚拟机只有一个...# 真实服务器如果有32个,可以设置为32个export SPARK_WORKER_CORES=1# 每个Worker最多可以使用的内存,我的虚拟机只有2g# 真实服务器如果有128G,可以设置为100Gexport SPARK_WORKER_MEMORY=1g# 在非HA配置中,配置了SPARK_MASTER_HOST和SPARK_MASTER_PORT# HA就不用了,让Zookeeper来管理# 设置zookeeper集群的地址,这个配置有点长,但一定要写到一行export SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=hadoop01:2181,hadoop02:2181,hadoop03:2181 -Dspark.deploy.zookeeper.dir=/spark/ha"
(3) 修改slaves配置文件,添加Worker的主机列表
[hadoop@hadoop01 conf]$ mv slaves.template slaves[hadoop@hadoop01 conf]$ vim slaves# 里面的内容原来为localhosthadoop01hadoop02hadoop03hadoop04
(4) 将SPARK_HOME/sbin下的start-all.sh和stop-all.sh这两个文件重命名,例如分别改为start-spark-all.sh和stop-spark-all.sh
原因:
如果集群中也配置了HADOOP_HOME,那么在HADOOP_HOME/sbin目录下也有start-all.sh和stop-all.sh这两个文件,当你执行这两个文件时,系统不知道是操作hadoop集群还是spark集群。修改后就不会冲突了。当然,不修改的话,你需要进入它们的sbin目录下执行这些文件,这肯定就不会发生冲突了。我们配置SPARK_HOME主要也是为了执行其他spark命令方便。
[hadoop@hadoop01 conf]$ cd ../sbin[hadoop@hadoop01 sbin]$ mv start-all.sh start-spark-all.sh[hadoop@hadoop01 sbin]$ mv stop-all.sh stop-spark-all.sh
(5) 将spark安装包分发给其他节点
[hadoop@hadoop01 apps]$ scp -r spark-2.2.0 hadoop02:`pwd`[hadoop@hadoop01 apps]$ scp -r spark-2.2.0 hadoop03:`pwd`[hadoop@hadoop01 apps]$ scp -r spark-2.2.0 hadoop04:`pwd`
(6) 在集群所有节点中配置SPARK_HOME环境变量
[hadoop@hadoop01 conf]$ vim ~/.bash_profileexport SPARK_HOME=/home/hadoop/apps/spark-2.2.0export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin[hadoop@hadoop01 conf]$ source ~/.bash_profile# 其他节点也都配置...
(7) 启动Zookeeper集群
[hadoop@hadoop01 ~]$ zkServer.sh start# 其他zookeeper节点也要启动...# 最好也启动hadoop集群
(8) 在hadoop01节点启动master进程
[hadoop@hadoop01 conf]$ start-master.sh
(9) 在hadoop02节点启动master进程
[hadoop@hadoop02 ~]$ start-master.sh
(10) 访问WEB页面查看哪个是ALIVE MASTER
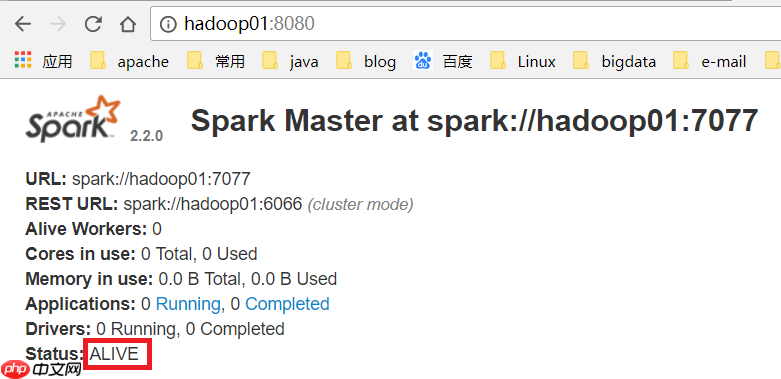
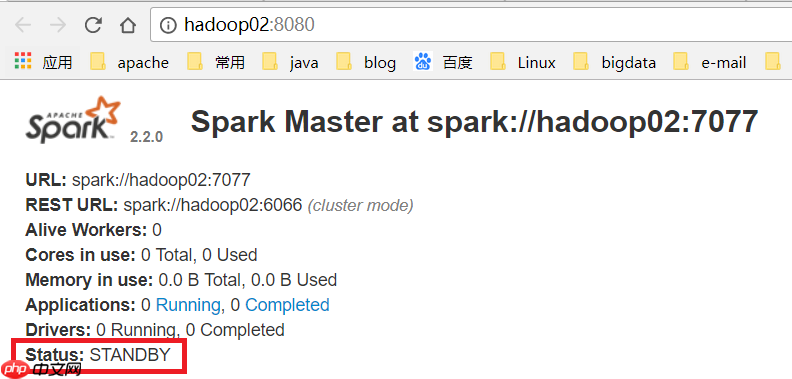
(11) 在ALIVE MASTER节点启动全部的Worker节点
[hadoop@hadoop01 ~]$ start-slaves.sh
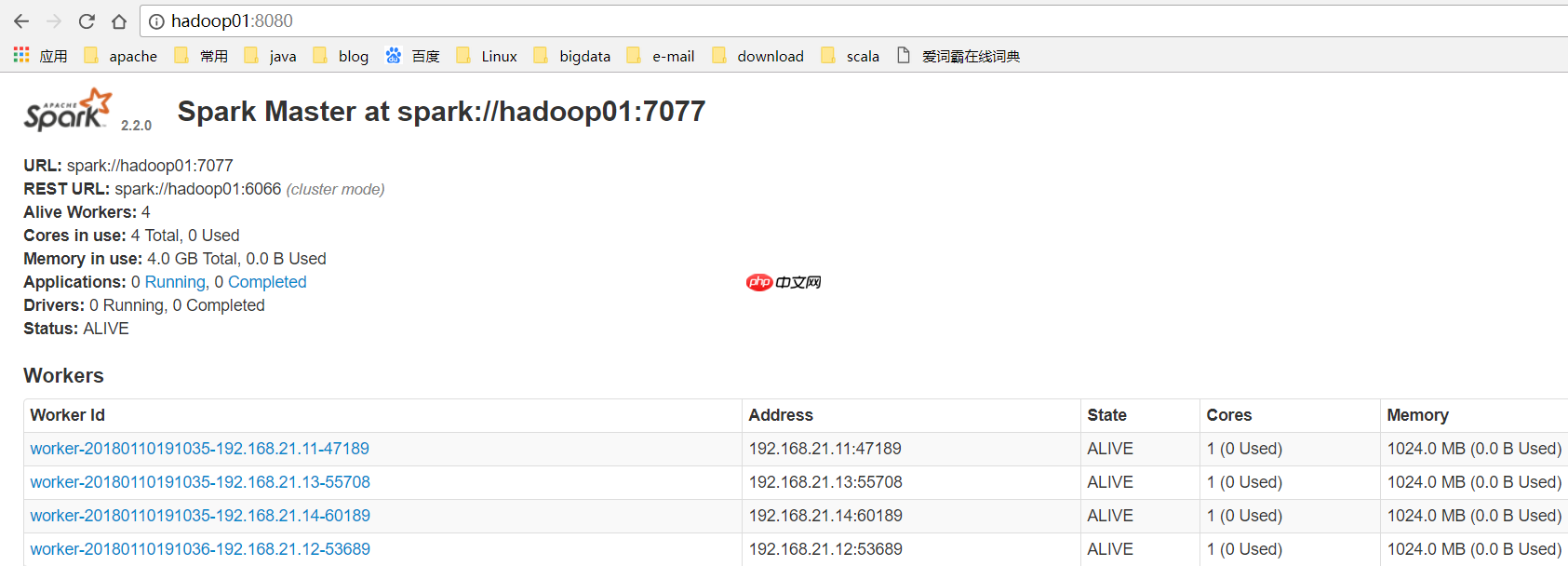
(12) 验证集群高可用正常的进程显示:
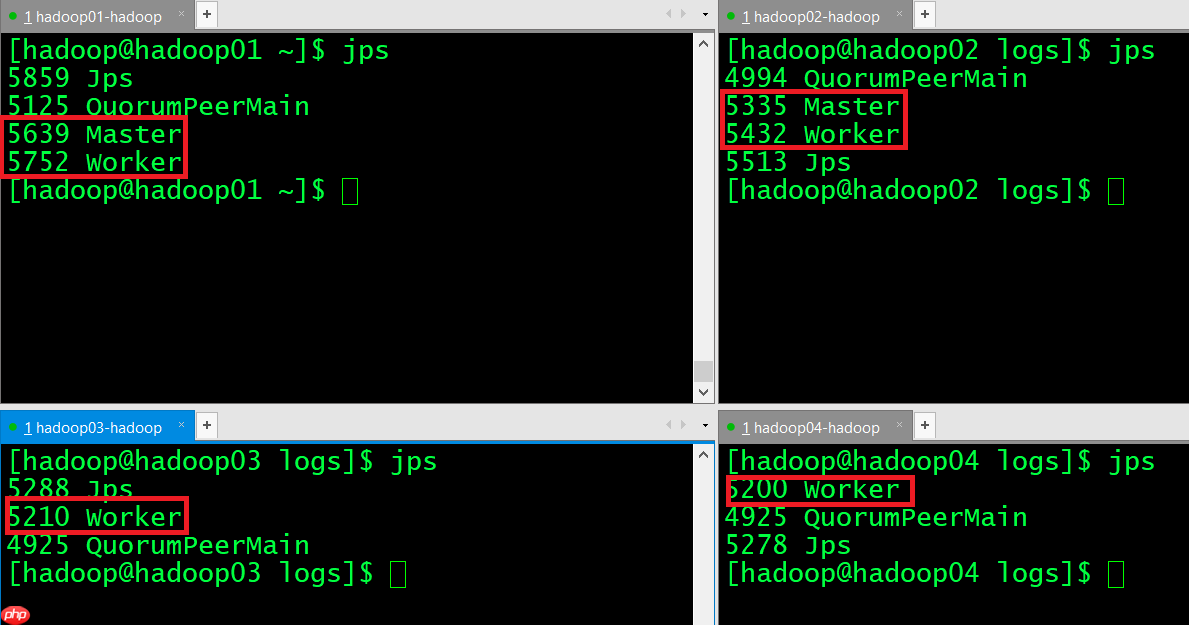
挂掉Active Master
[hadoop@hadoop01 ~]$ jps5873 Jps5125 QuorumPeerMain5639 Master5752 Worker[hadoop@hadoop01 ~]$ kill -9 5639
hadoop01已经不能访问了:
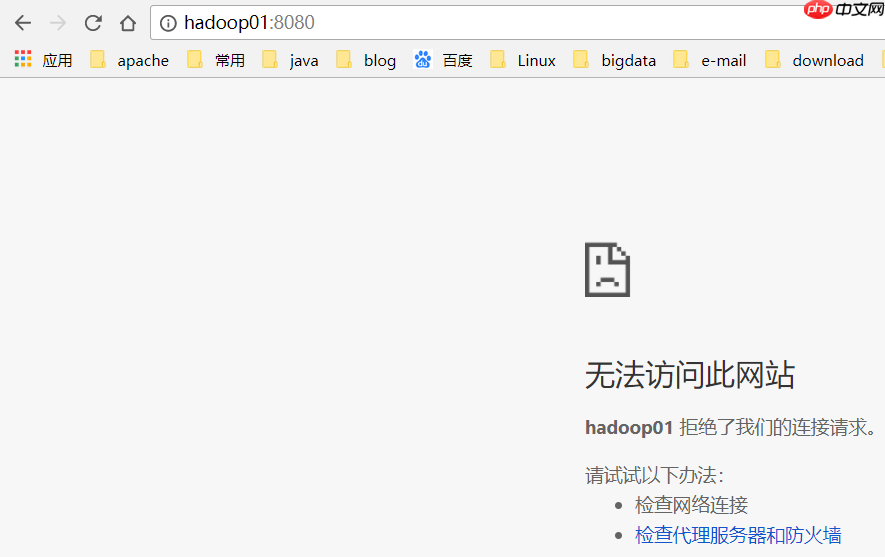
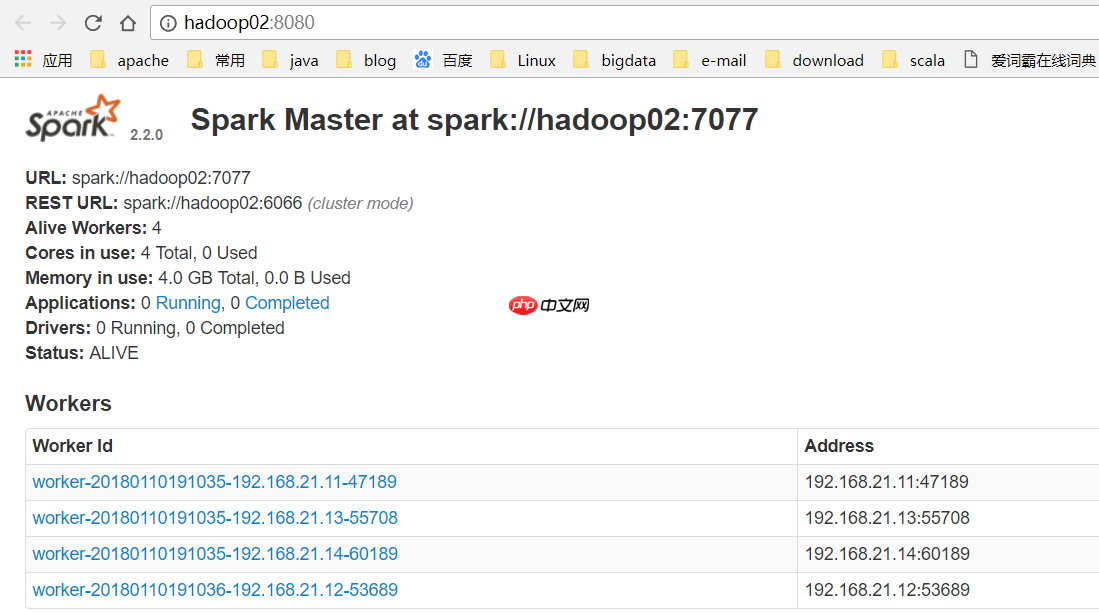
hadoop02变成了Active Master
启动hadoop01的master进程
[hadoop@hadoop01 ~]$ start-master.sh
hadoop01变成了Standby Master:
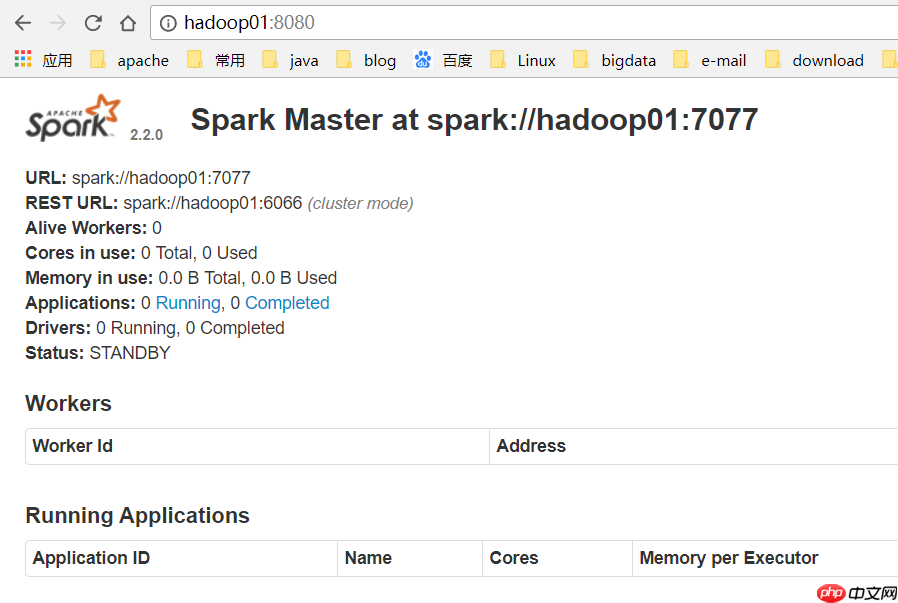
spark HA集群搭建成功!
以上就是Spark HA集群搭建的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/168228.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 



























