
腾讯优图实验室近日宣布开源 youtu-embedding,这是一款专为企业级场景设计的通用文本表示模型,具备强大的多任务处理能力,可广泛应用于文本检索、意图识别、语义相似度计算、文本分类与聚类等六大核心自然语言处理任务。该模型在信息检索(ir)、语义匹配(sts)、重排序、聚类分析及文本分类等多个关键nlp领域均表现出色,展现出领先的综合性能。
目前,模型权重、推理代码以及完整的训练框架已全面开放,首个版本已在 HuggingFace 平台正式发布。该版本为参数量达20亿(2B)的高性能通用语义嵌入模型,致力于为工业界和学术界提供高质量的中文语义理解工具。

Youtu-Embedding 的主要技术亮点包括:
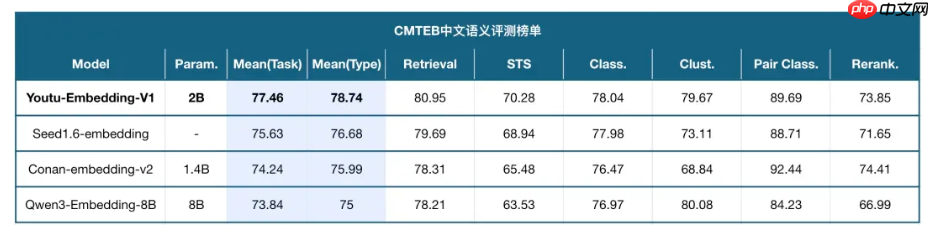
在权威中文文本嵌入评测榜单 CMTEB 上,Youtu-Embedding 以 77.46 的优异成绩位居榜首(截至2025年09月),彰显其在中文语义表示方面的领先地位。
采用创新的三阶段训练范式:通过“LLM 预训练 → 弱监督对齐 → 协同-判别式微调”的递进式流程,有效将大模型的知识迁移至嵌入任务中,显著提升模型的判别力与泛化性。构建高效的统一微调框架:引入标准化数据格式、任务定制化损失函数与动态单任务采样机制,成功缓解多任务学习中的“负迁移”问题,确保各任务间稳定协同优化。该框架已在多种主流编码器结构上验证,具备良好的适配性与扩展性。实施精细化的数据构建策略:融合基于大模型的高质量数据生成技术与高效的难负例挖掘方法,为模型训练提供了丰富且高信噪比的训练样本,夯实模型性能基础。
源码地址:点击下载
以上就是腾讯优图实验室开源 Youtu-Embedding的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/21649.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 




















