
一、问题引入
例如当前存在一张表test_user,然后往这个表里面插入3百万的数据:
CREATE TABLE `test_user` ( `id` int(11) NOT NULL AUTO_INCREMENT COMMENT '主键id', `user_id` varchar(36) NOT NULL COMMENT '用户id', `user_name` varchar(30) NOT NULL COMMENT '用户名称', `phone` varchar(20) NOT NULL COMMENT '手机号码', `lan_id` int(9) NOT NULL COMMENT '本地网', `region_id` int(9) NOT NULL COMMENT '区域', `create_time` datetime NOT NULL COMMENT '创建时间', PRIMARY KEY (`id`), KEY `idx_user_id` (`user_id`)) ENGINE=InnoDB AUTO_INCREMENT;
在数据库开发过程中我们经常会使用分页,核心技术是使用用 limit start, count 分页语句进行数据的读取。
我们分别看下从0、10000、100000、500000、1000000、1800000开始分页的执行时长(每页取100条)。
SELECT * FROM test_user LIMIT 0,100; # 0.031SELECT * FROM test_user LIMIT 10000,100; # 0.047SELECT * FROM test_user LIMIT 100000,100; # 0.109SELECT * FROM test_user LIMIT 500000,100; # 0.219SELECT * FROM test_user LIMIT 1000000,100; # 0.547sSELECT * FROM test_user LIMIT 1800000,100; # 1.625s
我们已经看出随着起始记录的增加,时间也随着增大。改变起始记录为290万后,我们可以看到分页语句中的limit和起始页码之间存在很大的关联
SELECT * FROM test_user LIMIT 2900000,100; # 3.062s
我们惊讶的发现MySQL在数据量大的情况下分页起点越大,查询速度越慢!
那么为什么会出现上述这种情况呢?
答案: 因为 limit 2900000,100 的语法实际上是mysql扫描到前2900100条数据,之后丢弃前面的3000000行,这个步骤其实是浪费掉的。
从中我们也能总结出以下两件事情:
limit语句的查询时间与起始记录的位置成正比。mysql的limit语句是很方便,但是对记录很多的表并不适合直接使用。
二、MySQL中的limit用法
limit子句可以被用于强制select语句返回指定的记录数,其语法格式如下:
SELECT * FROM 表名 limit m,n;SELECT * FROM table LIMIT [offset,] rows;
limit接受一个或两个数字参数,参数必须是一个整数常量,如果给定两个参数:
第一个参数指定第一个返回记录行的偏移量
第二个参数指定返回记录行的最大数目
2.1 m代表从m+1条记录行开始检索,n代表取出n条数据。(m可设为0)
SELECT * FROM 表名 limit 6,5;
上述SQL表示从第7条记录行开始算,取出5条数据
2.2 值得注意的是,n可以被设置为-1,当n为-1时,表示从m+1行开始检索,直到取出最后一条数据
SELECT * FROM 表名 limit 6,-1;
上述SQL表示取出第6条记录行以后的所有数据
2.3 若只给出m,则表示从第1条记录行开始算一共取出m条
SELECT * FROM 表名 limit 6;
2.4 以年龄倒序后取出前3行
select * from student order by age desc limit 3;
2.5 跳过前3行后再2取行
select * from student order by age desc limit 3,2;
三、深度分页优化策略
方法一:用主键id或者唯一索引优化
即先找到上次分页的最大id,然后利用id上的索引来查询:
SELECT * FROM test_user WHERE id>1000000 LIMIT 100; # 0.047秒
使用此优化SQL相比于前面的查询速度已经快了11倍。除了使用主键ID,还可以运用唯一索引来快速定位特定数据,从而避免全表扫描。以下是相应的SQL优化代码,读取唯一键(pk)在1000至1019范围内的数据:
SELECT * FROM 表名称 WHERE pk>=1000 ORDER BY pk ASC LIMIT 0,20
原因:索引扫描,速度会很快。
适用场景:如果数据查询出来是按照pk或者id进行排序,并且全部数据没有缺失的话则可以这样优化,否则分页操作会漏数据。
方法二:利用索引覆盖优化
我们都知道,利用了索引查询的语句中如果只包含了那个索引列(也就是索引覆盖),那么这种情况会查询很快。
为什么索引覆盖查询会很快呢?
答案:因为利用索引查找有优化算法,且数据就在查询索引上面,不用再去找相关的数据地址了,这样节省了很多时间。当并发量较高时,Mysql还提供了与索引相关联的缓存,充分利用此缓存可以获得更佳的效果。
由于在我们的测试表test_user中,id字段是主键,因此默认包含了主键索引。现在让我们看看利用覆盖索引的查询效果如何。
这次我们查询第1000001到1000100行的数据(利用覆盖索引,只包含id列):
SELECT id FROM test_user LIMIT 1000000,100; # 0.843秒
从这个结果中发现查询速度比全表扫描速度还要慢(当然在重复执行这条SQL,多次查询之后速度还是变快了很多,几乎省了一半时间,这是由于缓存的原因), 接着使用explain命令来查看该SQL的执行计划,发现该SQL执行采用的普通索引 idx_user_id:
EXPLAIN SELECT id FROM test_user LIMIT 1000000,100;
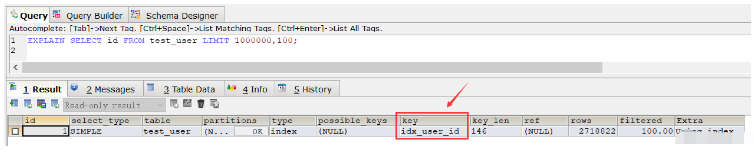
如果我们删除普通索引,则执行上述SQL时会使用主键索引。那如果不删除普通索引的话,针对这种情况,我们要让上述SQL走主键索引的话,则可以使用order by语句:
SELECT id FROM test_user ORDER BY id ASC LIMIT 1000000,100; # 0.250秒
那么如果我们也要查询所有列,有两种方法,一种是id>=的形式,另一种就是利用join。
第一种写法:
SELECT * FROM test_user WHERE ID >= (SELECT id FROM test_user ORDER BY id ASC LIMIT 1000000,1) LIMIT 100;
上述SQL查询时间为0.281秒
第二种写法:
SELECT * FROM (SELECT id FROM test_user ORDER BY id ASC LIMIT 1000000,100) a LEFT JOIN test_user b ON a.id = b.id;
上述SQL查询时间为0.252秒
方法三:基于索引再排序
其中pageNum表示页码,其取值从0开始;pageSize表示指的是每页多少条数据。
SELECT * FROM 表名称 WHERE id_pk > (pageNum*pageSize) ORDER BY id_pk ASC LIMIT pageSize;
适应场景:
 AI建筑知识问答
AI建筑知识问答
用人工智能ChatGPT帮你解答所有建筑问题
 22 查看详情
22 查看详情 
适用于数据量多的情况
最好ORDER BY后的列对象是主键或唯一索引
id数据没有缺失,可以作为序号使用
使用ORDER BY操作能利用索引被消除,但结果集是稳定的
原因:
索引扫描,速度会很快
但MySQL的排序操作,只有ASC没有DESC。在MySQL中,索引的存储顺序是升序ASC,没有降序DESC的索引。这就是为什么默认情况下,order by 是按照升序排序的原因
方法四:基于索引使用prepare
PREPARE预编译一个SQL语句,并为其分配一个名称 stmt_name,以便以后引用该语句,预编译好的语句用EXECUTE执行。
PREPARE stmt_name FROM 'SELECT * FROM test_user WHERE id > ? ORDER BY id ASC LIMIT ?';SET @a = 1000000;SET @b = 100;EXECUTE stmt_name USING @a, @b;;

上述SQL查询时间为0.047秒。
对于定义好的PREPARE预编译语句,我们可以使用下述命令来释放该预编译语句:
DEALLOCATE PREPARE stmt_name;
原因:
索引扫描,速度会很快.
prepare语句又比一般的查询语句快一点。
方法五:利用”子查询+索引”快速定位数据
其中page表示页码,其取值从0开始;pagesize表示指的是每页多少条数据。
SELECT * FROM your_table WHERE id <= (SELECT id FROM your_table ORDER BY id DESC LIMIT ($page-1)*$pagesize ORDER BY id DESC LIMIT $pagesize);
方法六:利用复合索引进行优化
假设数据表 collect ( id, title ,info ,vtype) 就这4个字段,其中id是主键自增,title用定长,info用text, vtype是tinyint,vtype是一个普通索引。
现在往里面填充数据,填充10万条记录,数据库表占用硬1.6G。
select id,title from collect limit 1000,10;
执行上述SQL速度很快,基本上0.01秒就OK。
select id,title from collect limit 90000,10;
然后再执行上述SQL,就发现非常慢,基本上平均8~9秒完成。
这个时候如果我们执行下述,我们会发现速度又变的很快,0.04秒就OK。
select id from collect order by id limit 90000,10;
那么这个现象的原因是什么?
答案:因为用了id主键做索引, 这里实现了索引覆盖,当然快。
所以如果想一起查询其它列的话,可以按照索引覆盖进行优化,具体如下:
select id,title from collect where id >= (select id from collect order by id limit 90000,1) limit 10;
再看下面的语句,带上where 条件:
select id from collect where vtype=1 order by id limit 90000,10;
可以发现这个速度上也是很慢的,用了8~9秒!
这里有一个疑惑:vtype 做了索引了啊?怎么会慢呢?
vtype做了索引是不错,如果直接对vtype进行过滤:
select id from collect where vtype=1 limit 1000,10;
可以看到速度还是很快的,基本上0.05秒,如果从9万开始,那就是0.05*90=4.5秒的速度了。
其实加了 order by id 就不走索引,这样做还是全表扫描,解决的办法是:复合索引!
因此针对下述SQL深度分页优化时可以加一个search_index(vtype,id)复合索引:
select id from collect where vtype=1 order by id limit 90000,10;
综上:
在进行SQL查询深度分页优化时,如果对于有where条件,又想走索引用limit的,必须设计一个索引,将where放第一位,limit用到的主键放第二位,而且只能select 主键。
最后根据查询出的主键走一级索引找到对应的数据。
按这样的逻辑,百万级的limit 在0.0x秒就可以分完,完美解决了分页问题。
以上就是MySQL调优之SQL查询深度分页问题怎么解决的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/271414.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 



















