
Gomoku游戏比围棋或象棋简单得多,因此我们可以专注于AlphaZero的训练,在一台PC机上几个小时内就可以获得一个让你不可大意的AI模型——因为一不留心,AI就可能战胜了你。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

用飞桨框架2.0造一个会下五子棋的AI模型——从小白到高手的训练之旅
还记得令职业棋手都闻风丧胆的“阿尔法狗”么?这里有“阿尔法狗”的小兄弟——AlphaZero-Gomoku-PaddlePaddle,即我用飞桨框架2.0从零开始训练自己的AI模型,开启五子棋小游戏。

五子棋游戏简介
五子棋是一种两人对弈的纯策略型棋类游戏,通常双方分别使用黑白两色的棋子,轮流下在棋盘竖线与横线的交叉点上,先形成五子连线者获胜。五子棋容易上手,老少皆宜,而且趣味横生,引人入胜。
本项目简介
本项目是AlphaZero算法的一个实现(使用PaddlePaddle框架),用于玩简单的棋盘游戏Gomoku(也称为五子棋),使用纯粹的自我博弈的方式开始训练。Gomoku游戏比围棋或象棋简单得多,因此我们可以专注于AlphaZero的训练,在一台PC机上几个小时内就可以获得一个让你不可忽视的AI模型——因为一不留心,AI就可能战胜了你。因为和围棋相比,五子棋的规则较为简单,落子空间也比较小,因此没有用到AlphaGo Zero中大量使用的残差网络,只使用了卷积层和全连接层,也正是因为网络结构简单,所以用AIstudio的cpu环境也可以运行(建议使用GPU环境,程序会自动检测环境是否包含GPU,无需手动设置);本项目之前是用Paddle1.84版本写的,现在升级到paddle2.0版本。AlphaZero是MuZero的“前辈”,了解AlphaZero有助于理解MuZero算法的来龙去脉。开始训练自己的AI模型,请运行“python train.py”;开始人机对战或者AI互搏,请运行“python human_play.py”,15×15棋盘左上角9×9范围下棋的效果展示:
让我们用飞桨框架2.0打造一个会下五子棋的AI模型
首先,让我们开始定义策略价值网络的结构,网络比较简单,由公共网络层、行动策略网络层和状态价值网络层构成。在定义好策略和价值网络的基础上,接下来实现PolicyValueNet类,该类主要定义:policy_value_fn()方法,主要用于蒙特卡洛树搜索时评估叶子节点对应局面评分、该局所有可行动作及对应概率,后面会详细介绍蒙特卡洛树搜索;另一个方法train_step(),主要用于更新自我对弈收集数据上策略价值网络的参数。在训练神经网络阶段,我们使用自我对战学习阶段得到的样本集合(s,π,z),训练我们神经网络的模型参数。训练的目的是对于每个输入s, 神经网络输出的p,v和我们训练样本中的π,z差距尽可能的少。损失函数由三部分组成,第一部分是均方误差损失函数,用于评估神经网络预测的胜负结果和真实结果之间的差异。第二部分是交叉熵损失函数,用于评估神经网络的输出策略和我们MCTS输出的策略的差异。第三部分是L2正则化项。In [ ]
%%writefile AlphaZero_Gomoku_PaddlePaddle/policy_value_net_paddlepaddle.pyimport paddleimport numpy as npimport paddle.nn as nn import paddle.nn.functional as Fclass Net(paddle.nn.Layer): def __init__(self,board_width, board_height): super(Net, self).__init__() self.board_width = board_width self.board_height = board_height # 公共网络层 self.conv1 = nn.Conv2D(in_channels=4,out_channels=32,kernel_size=3,padding=1) self.conv2 = nn.Conv2D(in_channels=32,out_channels=64,kernel_size=3,padding=1) self.conv3 = nn.Conv2D(in_channels=64,out_channels=128,kernel_size=3,padding=1) # 行动策略网络层 self.act_conv1 = nn.Conv2D(in_channels=128,out_channels=4,kernel_size=1,padding=0) self.act_fc1 = nn.Linear(4*self.board_width*self.board_height, self.board_width*self.board_height) self.val_conv1 = nn.Conv2D(in_channels=128,out_channels=2,kernel_size=1,padding=0) self.val_fc1 = nn.Linear(2*self.board_width*self.board_height, 64) self.val_fc2 = nn.Linear(64, 1) def forward(self, inputs): # 公共网络层 x = F.relu(self.conv1(inputs)) x = F.relu(self.conv2(x)) x = F.relu(self.conv3(x)) # 行动策略网络层 x_act = F.relu(self.act_conv1(x)) x_act = paddle.reshape( x_act, [-1, 4 * self.board_height * self.board_width]) x_act = F.log_softmax(self.act_fc1(x_act)) # 状态价值网络层 x_val = F.relu(self.val_conv1(x)) x_val = paddle.reshape( x_val, [-1, 2 * self.board_height * self.board_width]) x_val = F.relu(self.val_fc1(x_val)) x_val = F.tanh(self.val_fc2(x_val)) return x_act,x_valclass PolicyValueNet(): """策略&值网络 """ def __init__(self, board_width, board_height, model_file=None, use_gpu=True): self.use_gpu = use_gpu self.board_width = board_width self.board_height = board_height self.l2_const = 1e-3 # coef of l2 penalty self.policy_value_net = Net(self.board_width, self.board_height) self.optimizer = paddle.optimizer.Adam(learning_rate=0.02, parameters=self.policy_value_net.parameters(), weight_decay=self.l2_const) if model_file: net_params = paddle.load(model_file) self.policy_value_net.set_state_dict(net_params) def policy_value(self, state_batch): """ input: a batch of states output: a batch of action probabilities and state values """ # state_batch = paddle.to_tensor(np.ndarray(state_batch)) state_batch = paddle.to_tensor(state_batch) log_act_probs, value = self.policy_value_net(state_batch) act_probs = np.exp(log_act_probs.numpy()) return act_probs, value.numpy() def policy_value_fn(self, board): """ input: board output: a list of (action, probability) tuples for each available action and the score of the board state """ legal_positions = board.availables current_state = np.ascontiguousarray(board.current_state().reshape( -1, 4, self.board_width, self.board_height)).astype("float32") # print(current_state.shape) current_state = paddle.to_tensor(current_state) log_act_probs, value = self.policy_value_net(current_state) act_probs = np.exp(log_act_probs.numpy().flatten()) act_probs = zip(legal_positions, act_probs[legal_positions]) # value = value.numpy() return act_probs, value.numpy() def train_step(self, state_batch, mcts_probs, winner_batch, lr=0.002): """perform a training step""" # wrap in Variable state_batch = paddle.to_tensor(state_batch) mcts_probs = paddle.to_tensor(mcts_probs) winner_batch = paddle.to_tensor(winner_batch) # zero the parameter gradients self.optimizer.clear_gradients() # set learning rate self.optimizer.set_lr(lr) # forward log_act_probs, value = self.policy_value_net(state_batch) # define the loss = (z - v)^2 - pi^T * log(p) + c||theta||^2 # Note: the L2 penalty is incorporated in optimizer value = paddle.reshape(x=value, shape=[-1]) value_loss = F.mse_loss(input=value, label=winner_batch) policy_loss = -paddle.mean(paddle.sum(mcts_probs*log_act_probs, axis=1)) loss = value_loss + policy_loss # backward and optimize loss.backward() self.optimizer.minimize(loss) # calc policy entropy, for monitoring only entropy = -paddle.mean( paddle.sum(paddle.exp(log_act_probs) * log_act_probs, axis=1) ) return loss.numpy(), entropy.numpy()[0] def get_policy_param(self): net_params = self.policy_value_net.state_dict() return net_params def save_model(self, model_file): """ save model params to file """ net_params = self.get_policy_param() # get model params paddle.save(net_params, model_file)
Overwriting AlphaZero_Gomoku_PaddlePaddle/policy_value_net_paddlepaddle.py
为什么用MCTS?
在棋盘游戏中(现实生活中也是),玩家在决定下一步怎么走的时候往往会“多想几步”。AlphaGoZero也一样。我们用神经网络来选择最佳的下一步走法后,其余低概率的位置就被忽略掉了。像Minimax这一类传统的AI博弈树搜索算法效率都很低,因为这些算法在做出最终选择前需要穷尽每一种走法。即使是带有较少分支因子的游戏也会使其博弈搜索空间变得像是脱缰的野马似的难以驾驭。分支因子就是所有可能的走法的数量。这个数量会随着游戏的进行不断变化。因此,你可以试着计算一个平均分支因子数,国际象棋的平均分支因子是35,而围棋则是250。这意味着,在国际象棋中,仅走两步就有1,225(35²)种可能的棋面,而在围棋中,这个数字会变成62,500(250²)。现在,时代变了,神经网络将指导并告诉我们哪些博弈路径值得探索,从而避免被许多无用的搜索路径所淹没。接着,蒙特卡洛树搜索算法就将登场啦!
棋类游戏的蒙特卡洛树搜索(MCTS)
使用MCTS的具体做法是这样的,给定一个棋面,MCTS共进行N次模拟。主要的搜索阶段有4个:选择,扩展,仿真和回溯
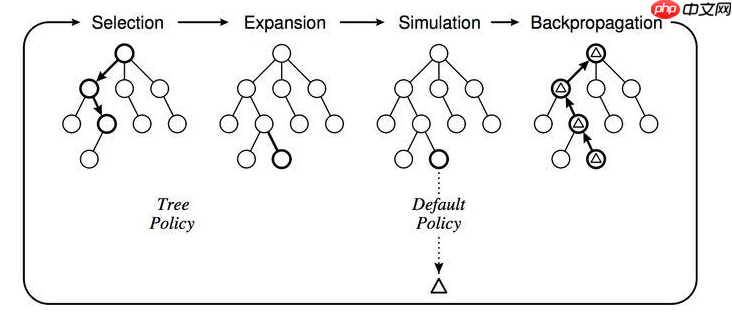
第一步是选择(Selection):这一步会从根节点开始,每次都选一个“最值得搜索的子节点”,一般使用UCT选择分数最高的节点,直到来到一个“存在未扩展的子节点”的节点
第二步是扩展(Expansion),在这个搜索到的存在未扩展的子节点,加上一个没有历史记录的子节点,初始化子节点
第三步是仿真(simulation),从上面这个没有试过的着法开始,用一个简单策略比如快速走子策略(Rollout policy)走到底,得到一个胜负结果。快速走子策略一般适合选择走子很快可能不是很精确的策略。因为如果这个策略走得慢,结果虽然会更准确,但由于耗时多了,在单位时间内的模拟次数就少了,所以不一定会棋力更强,有可能会更弱。这也是为什么我们一般只模拟一次,因为如果模拟多次,虽然更准确,但更慢。
第四步是回溯(backpropagation), 将我们最后得到的胜负结果回溯加到MCTS树结构上。注意除了之前的MCTS树要回溯外,新加入的节点也要加上一次胜负历史记录。
 文心大模型
文心大模型
百度飞桨-文心大模型 ERNIE 3.0 文本理解与创作
 56 查看详情
56 查看详情 
以上就是MCTS搜索的整个过程。这4步一般是通用的,但是MCTS树结构上保存的内容而一般根据要解决的问题和建模的复杂度而不同。
基于神经网络的蒙特卡洛树搜索(MCTS)
N(s,a) :记录边的访问次数; W(s,a): 合计行动价值; Q(s,a) :平均行动价值; P(s,a) :选择该条边的先验概率;
首先是选择(Selection):在MCTS内部,出现过的局面,我们会使用UCT选择子分支。最终我们会选择Q+U最大的子分支作为搜索分支,一直走到棋局结束,或者走到了没有到终局MCTS的叶子节点。cpuctcpuct是决定探索程度的一个系数

然后是扩展(Expansion)&&仿真(simulation),对于叶子节点状态s,会利用神经网络对叶子节点做预测,得到当前叶子节点的各个可能的子节点位置sL落子的概率p和对应的价值v,对于这些可能的新节点我们在MCTS中创建出来,初始化其分支上保存的信息为
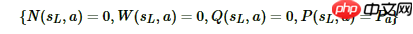
最后是回溯(backpropagation), 将新叶子节点分支的信息回溯累加到祖先节点分支上去。这个回溯的逻辑也是很简单的,从每个叶子节点L依次向根节点回溯,并依次更新上层分支数据结构如下:
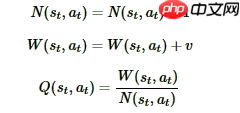
MCTS搜索完毕后,模型就可以在MCTS的根节点s基于以下公式选择行棋的MCTS分支了: 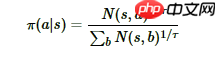
τ是用来控制探索的程度,τ的取值介于(0,1]之间,当τ越接近于1时,神经网络的采样越接近于MCTS的原始采样,当τ越接近于0时,神经网络的采样越接近于贪婪策略,即选择最大访问次数N所对应的动作。 因为在τ很小的情况下,直接计算访问次数N的τ次方根可能会导致数值异常,为了避免这种情况,在计算行动概率时,先将访问次数N加上一个非常小的数值(本项目是1e-10),取自然对数后乘上1/τ,再用一个简化的softmax函数将输出还原为概率,这和原始公式在数学上基本上是等效的。softmax()方法和get_move_probs()方法的代码分别如下:
def softmax(x):probs = np.exp(x - np.max(x)) probs /= np.sum(probs)return probsdef get_move_probs(self, state, temp=1e-3): """按顺序运行所有播出并返回可用的操作及其相应的概率。 state: 当前游戏的状态 temp: 介于(0,1]之间的临时参数控制探索的概率 """ for n in range(self._n_playout): state_copy = copy.deepcopy(state) self._playout(state_copy) # 根据根节点处的访问计数来计算移动概率 act_visits = [(act, node._n_visits) for act, node in self._root._children.items()] acts, visits = zip(*act_visits) act_probs = softmax(1.0/temp * np.log(np.array(visits) + 1e-10)) return acts, act_probs
关键点是什么?
通过每一次模拟,MCTS依靠神经网络, 使用累计价值(Q)、神经网络给出的走法先验概率(P)以及访问对应节点的频率这些数字的组合,沿着最有希望获胜的路径(换句话说,也就是具有最高置信区间上界的路径)进行探索。在每一次模拟中,MCTS会尽可能向纵深进行探索直至遇到它从未见过的盘面状态,在这种情况下,它会通过神经网络来评估该盘面状态的优劣巧妙了使用MCTS搜索树和神经网络一起,通过MCTS搜索树优化神经网络参数,反过来又通过优化的神经网络指导MCTS搜索。
具体代码可以自行查看项目文件
训练算法流程
AlphaZero的算法流程,概括来说就是通过自我对弈收集数据,并用于更新策略价值网络,更新后的策略价值网络又会被用于后续的自我对弈过程中,从而产生高质量的自我对弈数据,这样相互促进、不断迭代,实现稳定的学习和提升。我们将训练流程定义为run(),会循环执行self.collect_selfplay_data()方法,从而收集自我对弈的数据,收集到的数据多于self.batch_size时,我们就调用self.policy_update()来更新策略价值网络。
训练的主文件train.py,可以调整各种超参数
In [ ]
%%writefile AlphaZero_Gomoku_PaddlePaddle/train.py#!/usr/bin/env python# -*- coding: utf-8 -*-# 对于五子棋的AlphaZero的训练的实现from __future__ import print_functionimport randomimport numpy as npimport osfrom collections import defaultdict, dequefrom game import Board, Game_UIfrom mcts_pure import MCTSPlayer as MCTS_Purefrom mcts_alphaGoZero import MCTSPlayerfrom policy_value_net_paddlepaddle import PolicyValueNet # paddlepaddleimport paddleclass TrainPipeline(): def __init__(self, init_model=None, is_shown = 0): # 五子棋逻辑和棋盘UI的参数 self.board_width = 9 ###为了更快的验证算法,可以调整棋盘大小为(8x8) ,(6x6) self.board_height = 9 self.n_in_row = 5 self.board = Board(width=self.board_width, height=self.board_height, n_in_row=self.n_in_row) self.is_shown = is_shown self.game = Game_UI(self.board, is_shown) # 训练参数 self.learn_rate = 2e-3 self.lr_multiplier = 1.0 # 基于KL自适应地调整学习率 self.temp = 1.0 # 临时变量 self.n_playout = 400 # 每次移动的模拟次数 self.c_puct = 5 self.buffer_size = 10000 #经验池大小 10000 self.batch_size = 512 # 训练的mini-batch大小 512 self.data_buffer = deque(maxlen=self.buffer_size) self.play_batch_size = 1 self.epochs = 5 # 每次更新的train_steps数量 self.kl_targ = 0.02 self.check_freq = 100 #评估模型的频率,可以设置大一些比如500 self.game_batch_num = 1500 self.best_win_ratio = 0.0 # 用于纯粹的mcts的模拟数量,用作评估训练策略的对手 self.pure_mcts_playout_num = 1000 if init_model: # 从初始的策略价值网开始训练 self.policy_value_net = PolicyValueNet(self.board_width, self.board_height, model_file=init_model) else: # 从新的策略价值网络开始训练 self.policy_value_net = PolicyValueNet(self.board_width, self.board_height) # 定义训练机器人 self.mcts_player = MCTSPlayer(self.policy_value_net.policy_value_fn, c_puct=self.c_puct, n_playout=self.n_playout, is_selfplay=1) def get_equi_data(self, play_data): """通过旋转和翻转来增加数据集 play_data: [(state, mcts_prob, winner_z), ..., ...] """ extend_data = [] for state, mcts_porb, winner in play_data: for i in [1, 2, 3, 4]: # 逆时针旋转 equi_state = np.array([np.rot90(s, i) for s in state]) equi_mcts_prob = np.rot90(np.flipud( mcts_porb.reshape(self.board_height, self.board_width)), i) extend_data.append((equi_state, np.flipud(equi_mcts_prob).flatten(), winner)) # 水平翻转 equi_state = np.array([np.fliplr(s) for s in equi_state]) equi_mcts_prob = np.fliplr(equi_mcts_prob) extend_data.append((equi_state, np.flipud(equi_mcts_prob).flatten(), winner)) return extend_data def collect_selfplay_data(self, n_games=1): """收集自我博弈数据进行训练""" for i in range(n_games): winner, play_data = self.game.start_self_play(self.mcts_player, temp=self.temp) play_data = list(play_data)[:] self.episode_len = len(play_data) # 增加数据 play_data = self.get_equi_data(play_data) self.data_buffer.extend(play_data) def policy_update(self): """更新策略价值网络""" mini_batch = random.sample(self.data_buffer, self.batch_size) state_batch = [data[0] for data in mini_batch] # print(np.array( state_batch).shape ) state_batch= np.array( state_batch).astype("float32") mcts_probs_batch = [data[1] for data in mini_batch] mcts_probs_batch= np.array( mcts_probs_batch).astype("float32") winner_batch = [data[2] for data in mini_batch] winner_batch= np.array( winner_batch).astype("float32") old_probs, old_v = self.policy_value_net.policy_value(state_batch) for i in range(self.epochs): loss, entropy = self.policy_value_net.train_step( state_batch, mcts_probs_batch, winner_batch, self.learn_rate * self.lr_multiplier) new_probs, new_v = self.policy_value_net.policy_value(state_batch) kl = np.mean(np.sum(old_probs * ( np.log(old_probs + 1e-10) - np.log(new_probs + 1e-10)), axis=1) ) if kl > self.kl_targ * 4: # early stopping if D_KL diverges badly break # 自适应调节学习率 if kl > self.kl_targ * 2 and self.lr_multiplier > 0.1: self.lr_multiplier /= 1.5 elif kl < self.kl_targ / 2 and self.lr_multiplier self.batch_size: loss, entropy = self.policy_update() print("loss :{}, entropy:{}".format(loss, entropy)) if (i + 1) % 50 == 0: self.policy_value_net.save_model(os.path.join(dst_path, 'current_policy_step.model')) # 检查当前模型的性能,保存模型的参数 if (i + 1) % self.check_freq == 0: print("current self-play batch: {}".format(i + 1)) win_ratio = self.policy_evaluate() self.policy_value_net.save_model(os.path.join(dst_path, 'current_policy.model')) if win_ratio > self.best_win_ratio: print("New best policy!!!!!!!!") self.best_win_ratio = win_ratio # 更新最好的策略 self.policy_value_net.save_model(os.path.join(dst_path, 'best_policy.model')) if (self.best_win_ratio == 1.0 and self.pure_mcts_playout_num < 8000): self.pure_mcts_playout_num += 1000 self.best_win_ratio = 0.0 except KeyboardInterrupt: print('nrquit')if __name__ == '__main__': device = paddle.get_device() paddle.set_device(device) is_shown = 0 # model_path = 'dist/best_policy.model' model_path = 'dist/current_policy.model' training_pipeline = TrainPipeline(model_path, is_shown) # training_pipeline = TrainPipeline(None, is_shown) training_pipeline.run()
Overwriting AlphaZero_Gomoku_PaddlePaddle/train.py
开始训练和评估:
In [ ]
!pip install pygame%cd AlphaZero_Gomoku_PaddlePaddle !python train.py
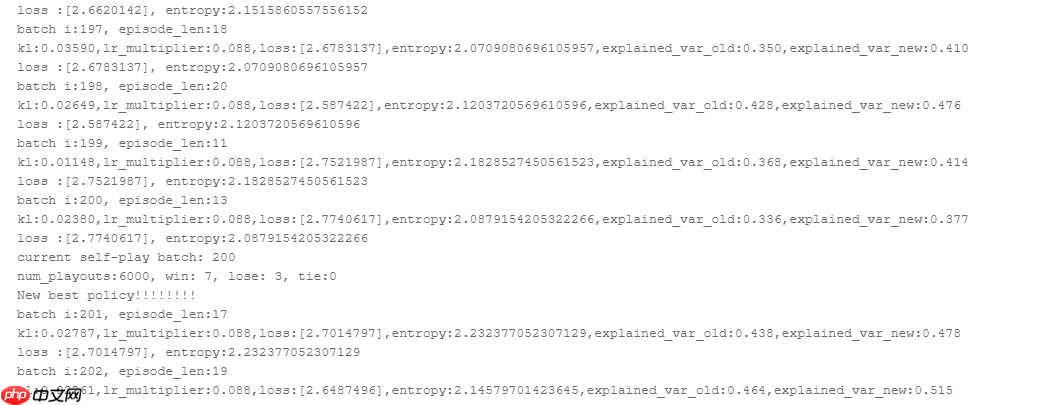
训练的截图,每隔一定步数会进行自博弈,评估网络并保留参数(这是加载过之前训练的参数的):
最后再介绍下MuZero
MuZero是AlphaZero的后继者。与AlphaGo和AlphaZero相似,MuZero也使用MCTS汇总神经网络预测,并选择适合当前环境的动作。但MuZero不需要提供规则手册,只需通过自我试验,便能学会象棋围棋游戏和各种Atari游戏。除此以外,它还能通过考虑游戏环境的各个方面来评估局面是否有利以及策略是否有效,并可通过复盘游戏在自身错误中学习。
以上就是用飞桨框架2.0造一个会下五子棋的AI模型的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/317168.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 

























