
PaddleSeg是%ignore_a_1%基于自家的PaddlePaddle开发的端到端图像分割开发套件。包含多种主流的分割网络。PaddleSeg采用模块化的方式设计,可以通过配置文件方式进行模型组合,帮助开发者在不需要深入了解图像分割原理的情况,实现方便快捷的完成模型的训练与部署。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

PaddleSeg 代码解读-训练、配置与数据集模块解读
PaddleSeg是百度基于自家的PaddlePaddle开发的端到端图像分割开发套件。包含多种主流的分割网络。PaddleSeg采用模块化的方式设计,可以通过配置文件方式进行模型组合,帮助开发者在不需要深入了解图像分割原理的情况,实现方便快捷的完成模型的训练与部署。 但是在对需要对模型进行修改优化的时候,还是需要对图像分割原理以及PaddleSeg套件有进一步了解,本文的主要内容就是对PaddleSeg进行代码解读,帮助开发者进一步了解图像分割原理以及PaddleSeg的实现方法。本文只要介绍PaddleSeg的动态图的实现方法。
本代码解读基于PaddleSeg动态图版本V2.0.0-rc。 PaddleSeg套件的源代码可以从GitHub上进行下载,命令如下:
In [ ]
!git clone https://github.com/PaddlePaddle/PaddleSeg.git
PaddleSeg包含下几个目录:
configs:保存不同神经网络的配置文件。
contrib:真实案例相关配置与数据
legacy:静态图版本代码,只维护,不更新新功能
docs:文档
paddleseg:PaddleSeg核心代码,包含训练、评估、推理等文件。
tools:工具脚本
train.py:训练入口文件
val.py:评估模型文件
predict.py:预测文件
由于篇幅过长,本文分为三个部分:
第一部分包含:
1.train.py代码解读:这里主要讲解paddleseg训练入口文件的代码。该文件里描述了参数的解析,训练的启动方法,以及为训练准备的资源等。
2.Config代码解读:这里主要讲解了Config类的代码,config类由train.py实例化,通过运行train.py时指定的配置文件生成config对象。
3.DataSet代码解读:这里主要讲解了Dataset类,对每一种数据集都抽象为一个类,通过继承Dataset类,实现匿名协议,构建文件列表,供训练使用。
第二部分包含:
1.数据增强代码解读:这里主要讲解了数据处理与增强的一些常用算法。
2.模型与Backbone代码解读:这里主要讲解常用的模型以及backbone的网络与算法。
第三部分包含:
1.损失函数代码解读:这里主要讲解常用的损失函数的代码与算法。
2.评估模型代码解读:这里讲解评估模型性能的代码与评估方法。
3.预测代码解读: 这里解读使用模型生成预测结果的方法。
1.train.py代码解读
神经网络模型训练需要使用train.py来完成。是PaddleSeg中核心代码。
我们先结合下图,来了解一下训练之前的准备工作。
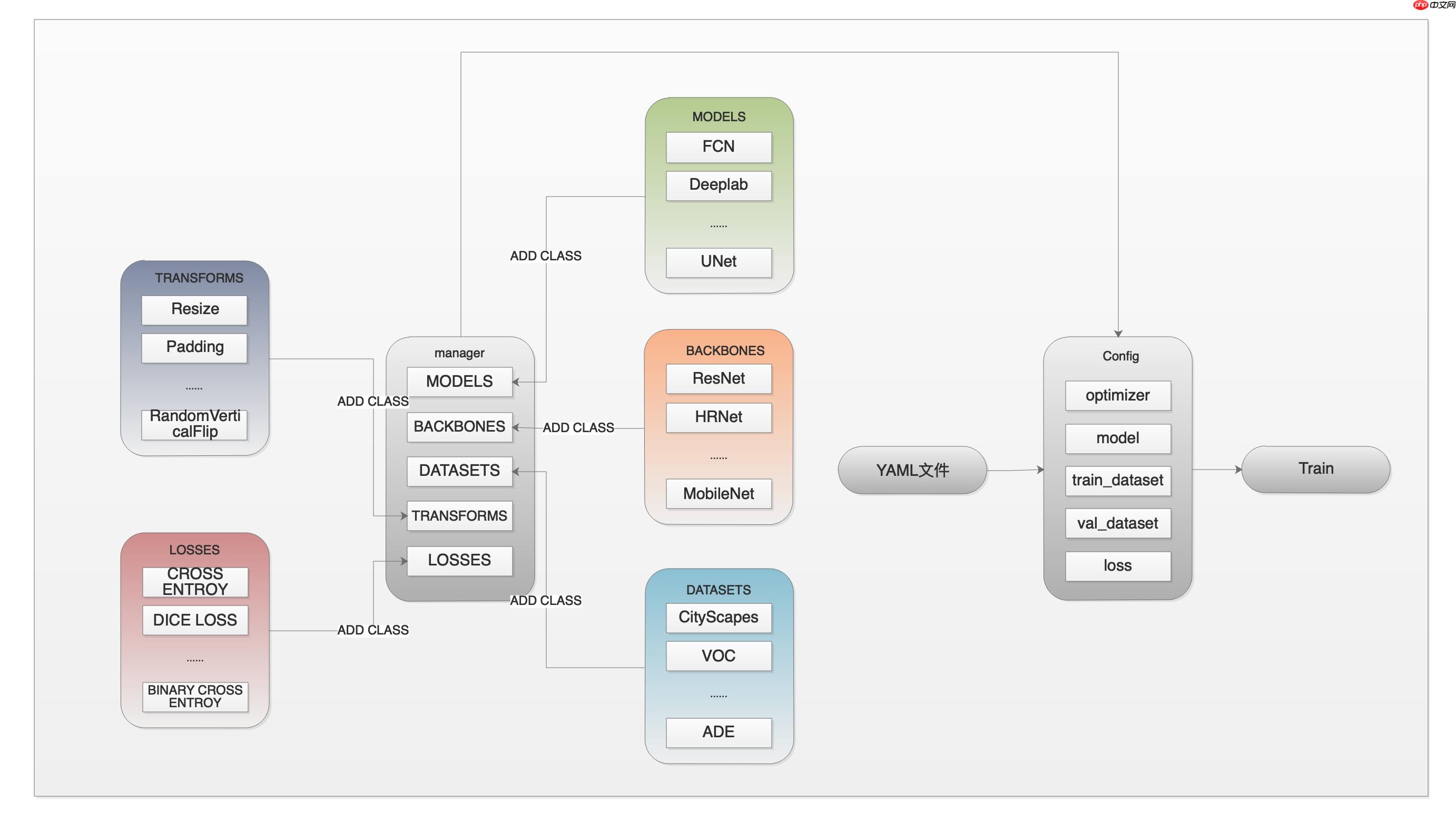
可以通过以下命令快速开始一个训练任务。
python train.py --config configs/quick_start/bisenet_optic_disc_512x512_1k.yml
命令中的–config参数指定本次训练的配置文件,配置文件的详细介绍可以参见后面的第二节。
在执行train.py脚本的最开始会导入一些包,如下:
from paddleseg.cvlibs import manager, Configfrom paddleseg.utils import get_sys_env, loggerfrom paddleseg.core import train
在导入manager模块时会创建图中左侧manage方框中的5个ComponentManager对象,他们分别是MODELS、BACKBONES、DATASETS、TRANSFORMS和LOSSES。这5个ComponentManager类似字典,用来维护套件中所有对应的类,比如FCN类、ResNet类等,通过类的名称就可以找到对应的类。在train.py运行时,会创建config对象。
cfg = Config( args.cfg, learning_rate=args.learning_rate, iters=args.iters, batch_size=args.batch_size)
在创建config对象时,会通过manager获取到配置文件中指定的类,并实例化对象,比如model和loss等。
train.py调用train函数,将config作为实参传入。train函数获取config中的成员来完成训练工作。
下面我们来详细解读一下train.py,首先我们从train.py的入口代码开始:
if __name__ == '__main__': # 处理运行train.py传入的参数 args = parse_args() #调用主函数。 main(args)
首先看一下第一行代码
 晓象AI资讯阅读神器
晓象AI资讯阅读神器
晓象-AI时代的资讯阅读神器
 25 查看详情
25 查看详情 
args = parse_args()
parse_args()的实现如下:
#配置文件路径parser.add_argument( "--config", dest="cfg", help="The config file.", default=None, type=str) #总训练迭代次数 parser.add_argument( '--iters', dest='iters', help='iters for training', type=int, default=None) #batchsize大小 parser.add_argument( '--batch_size', dest='batch_size', help='Mini batch size of one gpu or cpu', type=int, default=None) #学习率 parser.add_argument( '--learning_rate', dest='learning_rate', help='Learning rate', type=float, default=None) #保存模型间隔 parser.add_argument( '--save_interval', dest='save_interval', help='How many iters to save a model snapshot once during training.', type=int, default=1000) #如果需要恢复训练,指定恢复训练模型路径 parser.add_argument( '--resume_model', dest='resume_model', help='The path of resume model', type=str, default=None) #模型保存路径 parser.add_argument( '--save_dir', dest='save_dir', help='The directory for saving the model snapshot', type=str, default='./output') #数据读取器线程数量,目前在AI Studio建议设置为0. parser.add_argument( '--num_workers', dest='num_workers', help='Num workers for data loader', type=int, default=0) #在训练过程中进行模型评估 parser.add_argument( '--do_eval', dest='do_eval', help='Eval while training', action='store_true') #日志打印间隔 parser.add_argument( '--log_iters', dest='log_iters', help='Display logging information at every log_iters', default=10, type=int) #开启可视化训练 parser.add_argument( '--use_vdl', dest='use_vdl', help='Whether to record the data to VisualDL during training', action='store_true')
然后看下一行代码:
main(args)
main 的代码如下:
def main(args): #获取环境信息,比如操作系统类型、python版本号、Paddle版本、GPU数量、Opencv版本、gcc版本等内容 env_info = get_environ_info() #打印环境信息 info = ['{}: {}'.format(k, v) for k, v in env_info.items()] info = ''.join(['', format('Environment Information', '-^48s')] + info + ['-' * 48]) logger.info(info) #确定是否使用GPU place = 'gpu' if env_info['Paddle compiled with cuda'] and env_info[ 'GPUs used'] else 'cpu' #设置使用GPU或者CPU paddle.set_device(place) #如果没有指定配置文件这抛出异常。 if not args.cfg: raise RuntimeError('No configuration file specified.') #构建cfg对象,该对象包含数据集、图像增强、模型结构、损失函数等设置 #该对象基于命令行传入参数以及yaml配置文件构建 cfg = Config( args.cfg, learning_rate=args.learning_rate, iters=args.iters, batch_size=args.batch_size)#从Config对象中获取train_data对象。train_data为迭代器 train_dataset = cfg.train_dataset #如果没有设置训练集,抛出异常 if not train_dataset: raise RuntimeError( 'The training dataset is not specified in the configuration file.') #如果需要在训练中进行模型评估,则需要获取到验证集 val_dataset = cfg.val_dataset if args.do_eval else None #获取损失函数 losses = cfg.loss msg = '---------------Config Information---------------' msg += str(cfg) msg += '------------------------------------------------' #打印出详细设置。 logger.info(msg) #调用core/train.py中train函数进行训练 train( cfg.model, train_dataset, val_dataset=val_dataset, optimizer=cfg.optimizer, save_dir=args.save_dir, iters=cfg.iters, batch_size=cfg.batch_size, resume_model=args.resume_model, save_interval=args.save_interval, log_iters=args.log_iters, num_workers=args.num_workers, use_vdl=args.use_vdl, losses=losses)
在train.py脚本中,除了调用config对配置文件进行解析,就是调用core/train.py中的train函数完成训练工作。下面我先看一下train函数的工作流程。
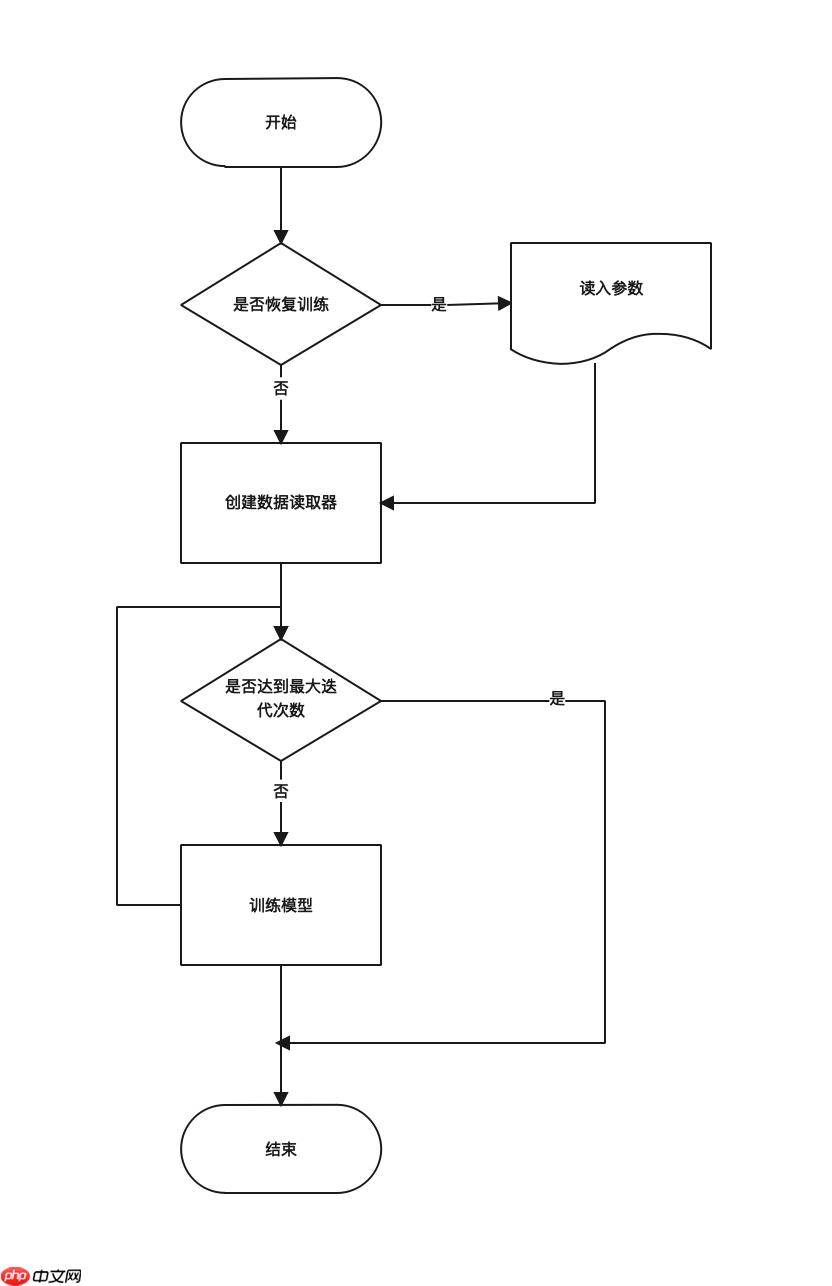
从图中看出,整个训练过程由两个循环组成,最外层循环由总迭代次数控制,需要在yaml文件中配置,如下代码:
iters: 80000
内层循环由数据读取器控制,循环会遍历数据读取器中所有的数据,直至全部读取完毕跳出循环,这个过程通常也被叫做一个epoch。
下面我们详细解析一下core/train.py中train函数的代码。
首先看一下train函数的代码概要。

然后我们再看一下详细的代码解读,
def train(model, #模型对象 train_dataset, #训练集对象 val_dataset=None, #验证集对象,如果训练过程不需要验证,可以为None optimizer=None, #优化器对象 save_dir='output', #模型输出路径 iters=10000, #训练最大迭代次数 batch_size=2, #batch size大学 resume_model=None, # 是否需要恢复训练,如果需要指定恢复训练模型权重路径 save_interval=1000, # 模型保存间隔 log_iters=10, # 设置日志输出间隔 num_workers=0, #设置数据读取器线程数,0为不开启多进程 use_vdl=False, #是否使用vdl losses=None): # 损失函数系数,当使用多个损失函数时,需要指定各个损失函数的系数。 #为了兼容多卡训练,这里需要获取显卡数量。 nranks = paddle.distributed.ParallelEnv().nranks #在分布式训练中,每个显卡都会执行本程序,所以需要在程序里获取本显卡的序列号。 local_rank = paddle.distributed.ParallelEnv().local_rank #循环起始的迭代数。如果是恢复训练的话,从恢复训练中获得起始的迭代数。 #比如,在2000次迭代的时候保存了中间训练过程,通过resume恢复训练,那么start_iter则为2000。 start_iter = 0 if resume_model is not None: start_iter = resume(model, optimizer, resume_model) #创建保存输出模型文件的目录。 if not os.path.isdir(save_dir): if os.path.exists(save_dir): os.remove(save_dir) os.makedirs(save_dir) #如果是多卡训练,则需要初始化多卡训练环境。 if nranks > 1: # Initialize parallel training environment. paddle.distributed.init_parallel_env() strategy = paddle.distributed.prepare_context() ddp_model = paddle.DataParallel(model, strategy)#创建一个批量采样器,这里指定数据集,通过批量采样器组成一个batch。这里需要指定batch size,是否随机打乱,是否丢弃末尾不能组成一个batch的数据等参数。 batch_sampler = paddle.io.DistributedBatchSampler( train_dataset, batch_size=batch_size, shuffle=True, drop_last=True) #通过数据集参数和批量采样器等参数构建一个数据读取器。可以通过num_works设置多进程,这里的多进程通过共享内存通信, #如果共享内存过小可能会报错,如果报错可以尝将num_workers设置为0,则不开启多进程。 loader = paddle.io.DataLoader( train_dataset, batch_sampler=batch_sampler, num_workers=num_workers, return_list=True, ) if use_vdl: from visualdl import LogWriter log_writer = LogWriter(save_dir) #开启定时器 timer = Timer() avg_loss = 0.0 iters_per_epoch = len(batch_sampler) best_mean_iou = -1.0 best_model_iter = -1 train_reader_cost = 0.0 train_batch_cost = 0.0 timer.start() iter = start_iter #开始循环,通过迭代次数控制最外层循环。 while iter iters: break #记录读取器时间 train_reader_cost += timer.elapsed_time() #保存样本 images = data[0] #保存样本标签 labels = data[1].astype('int64') #供BCELoss使用 edges = None if len(data) == 3: edges = data[2].astype('int64') #如果有多张显卡,则开启分布式训练,如果只有一张显卡则直接调用模型对象进行训练。 if nranks > 1: #通过模型前向运算获得预测结果 logits_list = ddp_model(images) else: #通过模型前向运算获得预测结果 logits_list = model(images) #通过标签计算损失 loss = loss_computation( logits_list=logits_list, labels=labels, losses=losses, edges=edges) #计算模型参数的梯度 loss.backward() #执行一次优化器并进行参数更新 optimizer.step() #获取当前优化器的学习率。 lr = optimizer.get_lr() if isinstance(optimizer._learning_rate, paddle.optimizer.lr.LRScheduler): optimizer._learning_rate.step() #清除模型中的梯度 model.clear_gradients() #计算平均损失值 avg_loss += loss.numpy()[0] train_batch_cost += timer.elapsed_time() #根据配置中的log_iters打印训练日志 if (iter) % log_iters == 0 and local_rank == 0: avg_loss /= log_iters avg_train_reader_cost = train_reader_cost / log_iters avg_train_batch_cost = train_batch_cost / log_iters train_reader_cost = 0.0 train_batch_cost = 0.0 remain_iters = iters - iter eta = calculate_eta(remain_iters, avg_train_batch_cost) logger.info( "[TRAIN] epoch={}, iter={}/{}, loss={:.4f}, lr={:.6f}, batch_cost={:.4f}, reader_cost={:.4f} | ETA {}" .format((iter - 1) // iters_per_epoch + 1, iter, iters, avg_loss, lr, avg_train_batch_cost, avg_train_reader_cost, eta)) if use_vdl: log_writer.add_scalar('Train/loss', avg_loss, iter) log_writer.add_scalar('Train/lr', lr, iter) log_writer.add_scalar('Train/batch_cost', avg_train_batch_cost, iter) log_writer.add_scalar('Train/reader_cost', avg_train_reader_cost, iter) avg_loss = 0.0 #根据配置中的save_interval判断是否需要对当前模型进行评估。 if (iter % save_interval == 0 or iter == iters) and (val_dataset is not None): num_workers = 1 if num_workers > 0 else 0 mean_iou, acc = evaluate( model, val_dataset, num_workers=num_workers) #评估后需要将模型训练模式,该模式影响dropout和batchnorm层 model.train()#根据配置中的save_interval判断是否需要保存当前模型。 if (iter % save_interval == 0 or iter == iters) and local_rank == 0: current_save_dir = os.path.join(save_dir, "iter_{}".format(iter)) #如果输出路径不存在,需要创建目录。 if not os.path.isdir(current_save_dir): os.makedirs(current_save_dir) #保存模型权重 paddle.save(model.state_dict(), os.path.join(current_save_dir, 'model.pdparams')) #保存优化器权重,恢复训练会用到。 paddle.save(optimizer.state_dict(), os.path.join(current_save_dir, 'model.pdopt'))#保存最佳模型。 if val_dataset is not None: if mean_iou > best_mean_iou: best_mean_iou = mean_iou best_model_iter = iter best_model_dir = os.path.join(save_dir, "best_model") paddle.save( model.state_dict(), os.path.join(best_model_dir, 'model.pdparams')) logger.info( '[EVAL] The model with the best validation mIoU ({:.4f}) was saved at iter {}.' .format(best_mean_iou, best_model_iter)) if use_vdl: log_writer.add_scalar('Evaluate/mIoU', mean_iou, iter) log_writer.add_scalar('Evaluate/Acc', acc, iter) #重置定时器 timer.restart() # Sleep for half a second to let dataloader release resources. time.sleep(0.5) if use_vdl: log_writer.close()
2.Config代码解读
Config类定义在paddleseg/cvlibs/config.py文件中。它保存了数据集配置、模型配置、主干网络的配置、损失函数配置等所有的超参数。
在PaddleSeg中,通过使用YAML文件的方式保存配置。该方法的好处是,只需要对YAML进行修改,或者创建新的YAML文件就可以新建一个训练任务。
YAML的语法比较简单,文件结构也很方便阅读,下面我们从图像分割最基础的FCN网络的配置文件开始了解一下如何从YAML文件生成Config对象。
举个例子,看一下dygraph/configs/fcn/fcn_hrnetw18_cityscapes_1024x512_80k.yml文件内容:
# _base_ 不是必须的,其作用更像基类。# _base_指定的文件可以保存通用的配置,避免相同配置重复书写。若存在相同配置,会覆盖_base_指定yml文件的配置。_base_: '../_base_/cityscapes.yml'#模型信息model: #模型的类型FCN type: FCN #使用的主干网络为HRNet backbone: type: HRNet_W18 #主干网络的预训练模型的下载地址。 pretrained: https://bj.bcebos.com/paddleseg/dygraph/hrnet_w18_ssld.tar.gz #模型分类数为19,可根据实际情况修改 num_classes: 19 #模型的预训练地址,这里为空 pretrained: Null #这个是创建模型时需要传入的参数,该参数可以根据具体模型情况进行自定义设置,这个结合模型在具体讲解。 backbone_indices: [-1]#优化器设置,这里只设置了正则化的衰减系数,原因是因为在base里面已经设置了优化器的名称和学习率。optimizer: weight_decay: 0.0005#总迭代次数为80000次。iters: 80000
下面在看一下cityscape.yml文件内容:
#如果fcn的配置文件,配置了相同内容会覆盖本配置内容。batch_size: 4#迭代次数iters: 80000#训练集配置train_dataset: #类型为Cityscapes,这里的type对应的值会在Config类中实例化具体的对象,所以名字要跟类名一致。 #Citycapes类保存在dygraph/paddleseg/datasets/cityscapes.py文件中 type: Cityscapes #指定数据集的根目录,这里没有指定具体的文件List,是因为list是在Cityscape类中生成的。 dataset_root: data/cityscapes #数据增强操作 transforms: #每一个type 则代表了一个数据增强操作对应的类名。下面的值则为创建对象需要传递的参数。 - type: ResizeStepScaling min_scale_factor: 0.5 max_scale_factor: 2.0 scale_step_size: 0.25 - type: RandomPaddingCrop crop_size: [1024, 512] - type: RandomHorizontalFlip - type: Normalize #模式为训练模式 mode: train#验证集配置val_dataset: type: Cityscapes dataset_root: data/cityscapes transforms: - type: Normalize #模式为验证集模式 mode: val#优化器设置。optimizer: #优化器为SGG type: sgd #动量 momentum: 0.9 #正则化 weight_decay: 4.0e-5#学习率设置learning_rate: #学习率 value: 0.01 #学习率衰减策略 decay: type: poly power: 0.9 end_lr: 0.0#损失函数设置loss: types: #支持多种损失函数 - type: CrossEntropyLoss #损失权重,若包含多个损失函数,可以在此处设置权重,权重数量需要与损失函数数量一致。 coef: [1]
上面介绍了yml配置文件的内容,下面解读Config类如何将yml文件转换为对象。Config代码比较长,下面截取重要的方法进行解读。
Config类的构造方法:
def __init__(self, path: str, learning_rate: float = None, batch_size: int = None, iters: int = None): #path为yml文件的路径,若果没有指定路径则抛出异常。 if not path: raise ValueError('Please specify the configuration file path.') #还需要判断路径是否存在,如果不存在则抛出异常。 if not os.path.exists(path): raise FileNotFoundError('File {} does not exist'.format(path)) #初始化成员变量,模型对象和损失函数对象。 self._model = None self._losses = None #判断配置文件类型是否为YAML。 if path.endswith('yml') or path.endswith('yaml'): #如果文件类型正确,则通过_parse_from_yaml方法将文件内容保存到字典中。 self.dic = self._parse_from_yaml(path) else: raise RuntimeError('Config file should in yaml format!') #更新配置中的learning_rate、batch_size和iters三个参数,这个三个参数是通过命令行传递过来的, #优先级高于yaml配置,会覆盖配置文件中的配置。 self.update( learning_rate=learning_rate, batch_size=batch_size, iters=iters)
下面看一下在构造函数中遇到的_parse_from_yaml方法的源代码:
def _parse_from_yaml(self, path: str): '''Parse a yaml file and build config''' #首先打开配置文件,通过yaml库中的load方法转换为字典。yaml为第三方库,可以同pip安装。具体使用方法参考yaml相关文档。 with codecs.open(path, 'r', 'utf-8') as file: dic = yaml.load(file, Loader=yaml.FullLoader)#判断_base_是否在字典中,本次使用的FCN的配置文件是包含的也就是上面讲解的cityscape.yml文件。 if '_base_' in dic: #同样获取cityscape.yml的路径然后通过本方法获取base配置的字典。 cfg_dir = os.path.dirname(path) base_path = dic.pop('_base_') base_path = os.path.join(cfg_dir, base_path) #递归调用,因为cityscape.yml中并不包含_base_,所以下面的方法就不会执行到现在这部分代码。 base_dic = self._parse_from_yaml(base_path) #更新dic字典中的内容。 dic = self._update_dic(dic, base_dic) return dic
下面在讲解一下构造函数中的update方法,这个方法比较简单就是更新learning rate、batch size和iters。
def update(self, learning_rate: float = None, batch_size: int = None, iters: int = None): '''Update config''' #如果learning_rate存在,更新字典中的值。 if learning_rate: self.dic['learning_rate']['value'] = learning_rate #更新batch_size if batch_size: self.dic['batch_size'] = batch_size #更新iters。 if iters: self.dic['iters'] = iters
在_parse_from_yaml中调用_update_dic方法更新字典参数,我们看一下与上面update的区别。
def _update_dic(self, dic, base_dic): """ Update config from dic based base_dic """ #首先复制一个basc_dic base_dic = base_dic.copy() #遍历dic中的键值对。 for key, val in dic.items(): #如果dic中的值的类型为字典,同时这个键在base_dic中存在,则需要使用base_dic中值进行更新。 #递归调用本方法进行更新,直到val类型是基本类型。 if isinstance(val, dict) and key in base_dic: base_dic[key] = self._update_dic(val, base_dic[key]) #如果是基本类型则直接更新,上面递归到此处会停止,在下面return处直接返回。 else: base_dic[key] = val dic = base_dic return dic
Config类中还包含了很多以@property为注解的方法,对应了yaml配置文件中的train_dataset、val_dataset、model、loss等配置。前面提到过在这些配置中都会包含一个名字是type的键,它对应的值为类的名字。以property为注解的方法则会通过类的名字创建该对象,并将该对象返回给用户,此处使用的是懒加载的方式,只有当被调用的时候才会去创建。下面我们举例model属性来讲解一下,其他属性工作流程类似。
@property def model(self) -> paddle.nn.Layer: #从Config的配置字典中获取model的配置内容对应yaml文件中的部分如下: #model: #type: FCN #backbone: #type: HRNet_W18 #pretrained: https://bj.bcebos.com/paddleseg/dygraph/hrnet_w18_ssld.tar.gz #num_classes: 19 #pretrained: Null #backbone_indices: [-1] model_cfg = self.dic.get('model').copy() #使用train_dataset配置中的类别数量覆盖model中的配置 model_cfg['num_classes'] = self.train_dataset.num_classes #如果model_cfg 不存在则抛出异常 if not model_cfg: raise RuntimeError('No model specified in the configuration file.') #在构造函数中_model配置为None,这里只创建一次模型对象。 if not self._model: #创建模型对象。下面会继续解读_load_object方法。 self._model = self._load_object(model_cfg) return self._model
_load_object方法解读:
def _load_object(self, cfg: dict) -> Any: #拷贝一份配置,因为需要通过type的值创建对象,所以如果cfg中不包含type键则会抛出异常。 cfg = cfg.copy() if 'type' not in cfg: raise RuntimeError('No object information in {}.'.format(cfg)) #通过_load_component方法根据type的值获取类组件,这里的组件都是在定义各个类的时候通过 #装饰器添加到manager维护的List中的,所以这里可以直接获取。至于如何加入list会在第3节接触到。 component = self._load_component(cfg.pop('type'))#此处获取创建对象需要传递的参数,保存在params中。 params = {} #遍历cfg中的键值对。 for key, val in cfg.items(): #这里使用_is_meta_type方法来判断val是字典同时也包含type值,如果包含的的话说明val对应的也是一个对象, #需要使用递归的方式获取到,直到参数类型为简单对象。 if self._is_meta_type(val): params[key] = self._load_object(val) #如果参数是一个列表,则需要遍历列表中的内容,判断是否需要递归创建对象。 elif isinstance(val, list): params[key] = [ self._load_object(item) if self._is_meta_type(item) else item for item in val ] #遇到基本类型,保存参数。 else: params[key] = val#遍历借宿创建对象。 return component(**params)
至此Config类代码就解读完毕。
3.DataSet代码解读
在yaml配置文件中,我们配置的train_dataset的type为Cityscapes类型。通过以上Config代码的解读,我们知道了在第一次调用Config对象的train_dataset属性时会懒加载创建Cityscapes对象。 Cityscapes类的位置在paddleseg/datasets/cityscapes.py,Cityscapes的父类为Dataset,位于同目录下的dataset.py文件中,所以我先从Dataset类开始解读。
首先从Dataset的构造函数开始,构造函数比较长,里面包含了一些判断逻辑去初始化成员变量:
def __init__(self, transforms,#图像的transform dataset_root,#dataset的路劲 num_classes, #类别数量 mode='train', # 训练模式,train、val和test train_path=None, #训练列表文件路径,文件中每一行第一个是样本文件,第二个是标注文件。image1.jpg ground_truth1.png val_path=None, #验证列表文件路径,与训练文件一致。 test_path=None,#与训练文件一致,其中标注文件不是必须的。 separator=' ', #指定列表文件中样本文件和训练文件的分隔符,默认是空格 ignore_index=255, #需要忽略的类别id edge=False): #是否在训练时计算边缘 #保存数据的路径 self.dataset_root = dataset_root #构建数据增强对象 self.transforms = Compose(transforms) #新建一个保存文件路径的空列表 self.file_list = list() #将模式类型字符串转换为小写并保存为成员变量 mode = mode.lower() self.mode = mode #保存类别数 self.num_classes = num_classes #保存需要忽略的类别编号,一般都是255 self.ignore_index = ignore_index #保存edge self.edge = edge #如果mode不在trainalest中,需要抛出异常。 if mode.lower() not in ['train', 'val', 'test']: raise ValueError( "mode should be 'train', 'val' or 'test', but got {}.".format( mode)) #数据增强对象必须指定,如果未设置,抛出异常。 if self.transforms is None: raise ValueError("`transforms` is necessary, but it is None.") #如果数据集路径不存在则抛出异常。 self.dataset_root = dataset_root if not os.path.exists(self.dataset_root): raise FileNotFoundError('there is not `dataset_root`: {}.'.format( self.dataset_root)) #判断各个类型的文件列表是否存在,不存在抛出异常,存在则保存到file_path变量中。 if mode == 'train': if train_path is None: raise ValueError( 'When `mode` is "train", `train_path` is necessary, but it is None.' ) elif not os.path.exists(train_path): raise FileNotFoundError( '`train_path` is not found: {}'.format(train_path)) else: file_path = train_path elif mode == 'val': if val_path is None: raise ValueError( 'When `mode` is "val", `val_path` is necessary, but it is None.' ) elif not os.path.exists(val_path): raise FileNotFoundError( '`val_path` is not found: {}'.format(val_path)) else: file_path = val_path else: if test_path is None: raise ValueError( 'When `mode` is "test", `test_path` is necessary, but it is None.' ) elif not os.path.exists(test_path): raise FileNotFoundError( '`test_path` is not found: {}'.format(test_path)) else: file_path = test_path #打开列表文件,文件包含若干行,数量与数据集样本数量相同,训练集(train)和验证集(val)列表包含样本路径和标签文件路径。 #测试集则只包含样本路径。 with open(file_path, 'r') as f: #遍历列表文件中的每一行。 for line in f: #分离样本路径和标签路径。 items = line.strip().split(separator) #如果在训练集和验证集不包含样本路径和标签路径则抛出异常。 if len(items) != 2: if mode == 'train' or mode == 'val': raise ValueError( "File list format incorrect! In training or evaluation task it should be" " image_name{}label_namen".format(separator)) image_path = os.path.join(self.dataset_root, items[0]) label_path = None else: #拼接样本完整路径和标签完整路径 image_path = os.path.join(self.dataset_root, items[0]) label_path = os.path.join(self.dataset_root, items[1]) #将样本路径和标签路径保存在列表中。 self.file_list.append([image_path, label_path])
凡是在类中定义了这个__getitem__ 方法,那么它的实例对象(假定为p),可以像这样p[key] 取值,当实例对象做p[key] 运算时,会调用类中的方法__getitem__。 这样对象就可通过下标进行查找对象。对象就可以成为一个可迭代对象。
下面解读在Dataset类中,如何通过file_list返回样本和标签。
def __getitem__(self, idx): #通过idx下标,在file_list里获取样本图片路径和标签图片路径。 image_path, label_path = self.file_list[idx] #如果是测试模式则返回图片ndarray类型的数据。在transforms中,包含了图片的读取和预处理,不同模式的dataset类的transforms对象是不同的。 if self.mode == 'test': im, _ = self.transforms(im=image_path) im = im[np.newaxis, ...] return im, image_path #如果是训练或者验证模式还需要返回样本图片的和标签图片的ndarray的数据类型。 elif self.mode == 'val': im, _ = self.transforms(im=image_path) label = np.asarray(Image.open(label_path)) label = label[np.newaxis, :, :] return im, label else: im, label = self.transforms(im=image_path, label=label_path) if self.edge: edge_mask = F.mask_to_binary_edge( label, radius=2, num_classes=self.num_classes) return im, label, edge_mask else: return im, label
在类中定义了__len__方法,可以使用len函数来获得长度,在Dataset类中保存文件列表,所以需要通过len函数来获取数据集中样本的数量,所以在Dataset类中还需要实现__len__方法。
def __len__(self): #该方法直接返回file_list列表的长度即可。 return len(self.file_list)
上面解读了Dataset类的实现,下面我们在来看看一个实际的数据集Cityscapes。 Cityscapes类定义dygraph/paddleseg/datasets/cityscapes.py文件中,该类是Dataset的子类。自然它继承了__getitem__和__len__方法,这两个方法 中的代码是可复用的。在__getitem__中包含了对样本图片和标签图片的预处理,这部分不论是什么数据集操作应该类似的,及时在预处理有不同的地方也可以通过传递 transforms对象来处理,所以在Cityscapes类中,我们只关心构造函数即可。
def __init__(self, transforms, dataset_root, mode='train', edge=False): #这部分与Dataset类基本一致,保存一些成员变量,不过这里面指定了该数据集共有19类,同时直接指定了ignore_index为255. self.dataset_root = dataset_root self.transforms = Compose(transforms) self.file_list = list() mode = mode.lower() self.mode = mode self.num_classes = 19 self.ignore_index = 255 self.edge = edge if mode not in ['train', 'val', 'test']: raise ValueError( "mode should be 'train', 'val' or 'test', but got {}.".format( mode)) if self.transforms is None: raise ValueError("`transforms` is necessary, but it is None.") #由于不同的数据集文件组织结构会不同,在Cityscapes数据集中样本图片和标签图片分别保存在leftImg8bit和gtFine路径下。 img_dir = os.path.join(self.dataset_root, 'leftImg8bit') label_dir = os.path.join(self.dataset_root, 'gtFine') if self.dataset_root is None or not os.path.isdir( self.dataset_root) or not os.path.isdir( img_dir) or not os.path.isdir(label_dir): raise ValueError( "The dataset is not Found or the folder structure is nonconfoumance." ) #这里没有使用读取列表文件的方式获取样本图片列表和标签图片列表,而是通过glob方法使用正则化的方法匹配对应的文件来获取标签图片路径。 label_files = sorted( glob.glob( os.path.join(label_dir, mode, '*', '*_gtFine_labelTrainIds.png'))) #跟上面一样获取样本图片路径列表。 img_files = sorted( glob.glob(os.path.join(img_dir, mode, '*', '*_leftImg8bit.png'))) #构建文件列表,每一个元素,是包含两个元素的列表,形式为[样本图片路径,标签图片路径],供父类的__getitem__调用去预处理图片数据。 self.file_list = [[ img_path, label_path ] for img_path, label_path in zip(img_files, label_files)]
数据集部分的主要代码基本解读完毕,这里我们了解到在PaddleSeg套件中已经提供了Dataset类作为基类,所以如果我们想添加新的数据集则可以继承 Dataset类,然后自己实现__init__构造方法即可,可参考Cityscapes类实现。
以上就是PaddleSeg代码解读的第一部分。
以上就是PaddleSeg代码解读-训练、配置与数据集模块解读的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/317242.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 





















