
本文介绍了图像去雾顶尖模型FFA-Net,其以雾化图片为输入,经初步卷积后进入由Group大模块和Block小模块构成的主结构,融合各Group输出,再经通道和像素注意力块处理,叠加输入得去雾图。模型用L1和感知损失,Adam优化器,余弦退火降学习率。训练时裁剪图像省显存,复现需大量迭代,复现精度接近论文水平。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

1. 模型简介
论文: FFA-Net: Feature Fusion Attention Network for Single Image Dehazing
参考项目: https://github.com/zhilin007/FFA-Net
该模型是图像去雾领域的一个顶尖模型之一。该模型要实现的目标是图像去雾。我将从模型的总体结构、特殊模块、损失函数,优化器及学习率下降策略、数据预处理和训练细节这几个方面,来对模型进行介绍。
1.1 总体结构
模型的总体结构如下图所示。模型的输入是雾化图片。经过初步卷积后,进入模型的主要结构,由多个Group大模块构成。每个Group大型模块包含多个Block小模块。这里的大模块个数及每个大模块数包含的小模块个数都是可调参数,作者训练的模型的Group数为3,Block数为19。经过了Group大型模块后,将每个Group模块的输出用concat层相叠加,就得到了模型关键的中间输出。该中间输出经过该模型设计的特殊模块——通道注意力块 CA 和像素注意力块 PA 再进行处理后,经过两层简单的卷积层,就得到了该图像的修正图。修正图与输入图相加就得到了输出的去雾图像。
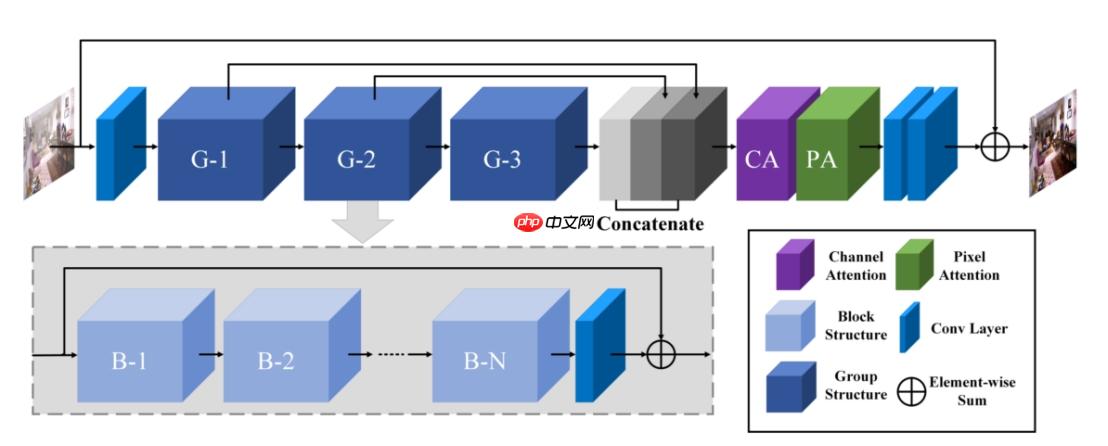
1.2 特殊模块——注意力模块
该模型最大的特点就是以下这两种基于注意力块的卷积块结构:
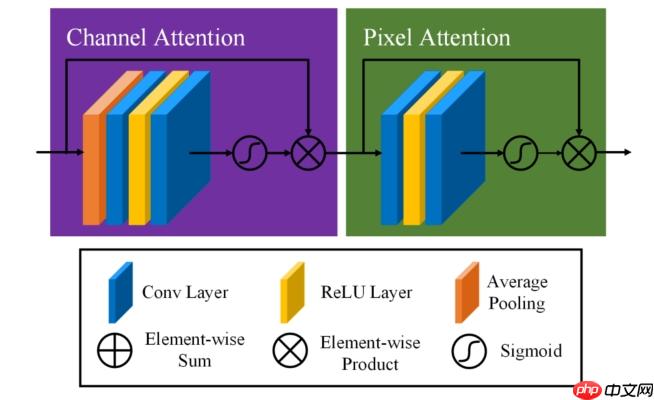
作者使用了两种注意力块,达到两种不同的目的。一种是通道注意力块,如上图左侧所示,假设该注意力块输入特征层尺寸为(1,64,256,256),经过层池化、卷积等操作,最后进行Sigmoid激活,输出一个尺寸为(1,64,1,1)的中间结果,之后与输入相乘,得到该注意力块的输出,这样就对每个通道乘以了不同的权重(0-1之间),产生了注意力效果。
另一种是像素注意力块,如上图右侧所示。假设该注意力块输入特征层尺寸为(1,64,256,256),与通道注意力块不同,没有经过层池化,并且输中间结果的通道数为1,(1,1,256,256),之后与输入相乘,得到该注意力块的输出,这样就对输入的每一个像素乘以不同的权重,产生了注意力效果。
将这两个块与卷积操作组合,就得到了模型的一个基本单元Block。添加多个Block,并在最后添加一个卷积层,就组合成了模型中一个较大的单元Group。具体Block和Group的结构可查看本文档 4.3 部分。
1.3 损失函数
作者在论文中提到该模型使用L1-loss效果比L2-loss好,所以使用真实无雾图像和经过模型去雾后的输出图像之间的L1-loss作为模型损失函数。论文中的具体公式如下图所示:
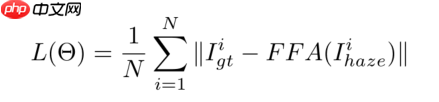
但是在查看作者提供的代码时发现,作者除了使用L1-loss外,还使用了感知损失(perceptual loss)作为模型的损失函数,所以在本项目中也对该per-loss进行了实现,具体代码可查看本文档的 4.4 部分。对感知损失的介绍可查看以下链接。
1.4 优化器及学习率下降策略
该模型使用Adam优化器, 初始学习率设置为0.0001,优化器的其他参数采用默认值。在训练过程中,学习率采用 cosine decay 方式下降。具体公式如下图所示:
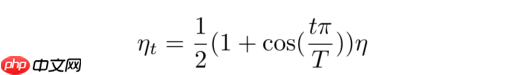
其中t代表当前训练的 iter 数, T代表训练的最大iter数。η代表初始学习率,ηt代表第t个iter时的学习率。以上叙述中的iter数表示的是训练过程中迭代的次数,每迭代一个batch的数据就经过了一个iter。
1.5 数据预处理
模型的数据预处理主要分为以下几个步骤:
从带雾图路径读取带雾图像,并根据带雾图像的文件名得到无雾图像的文件名并读取无雾图像。这是因为带雾图像是无雾图像叠加不同浓度的雾生成的,一张无雾图像会生成十几张带雾图像,且文件名存在联系,所以可以根据带雾图像的文件名得到对应无雾图像的文件名。
将无雾图像的边缘进行裁剪。这是因为无雾图像的数据有问题,边缘存在一圈无用的白圈,裁剪完后的像素才与带雾图像对应。
(训练独有步骤)对两张图像都进行随机裁剪操作,注意这里要先生成随机裁剪因子,再将该因子应用到两张图像上,才能保证两张图像裁剪的位置是一致的,步骤4也是如此。这里裁剪的原因在1.6中进行了详细解释。该模型进行测试时无此步骤。
(训练独有步骤)对两张图像进行相同的随机翻转、旋转操作,相当于进行数据增强。
对带雾图像的像素值进行标准化,保证模型输入数据的分布一致。
经过以上步骤,就得到了一组图片,其中经过处理的带雾图像为模型的输入数据,无雾图像为模型期望的输出数据。
1.6 训练细节
该模型默认的设置产生的网络结构复杂,训练过程中耗费的显存资源较大。为了节省资源,该模型在训练时,对输入数据的尺寸进行了裁剪,裁剪成了240 x 240的小图片后再输入网络进行训练。但即使如此,在Group数为3,block数为19,batchsize设置为1的情况下就需要耗费8G以上的显存。如在AI Studio中运行,使用V100 16G的环境,只能将batchsize设置为1,如使用32G的环境可将batchsize设置为2。进行测试时,该模型对显存的耗费明显减小,可以对整张大型图像进行去雾,无需进行裁剪。更多对输入数据的处理可以查看本文档的 4.2 部分。
模型要从零训练到复现精度需要较长时间,经过测试,在batchsize为2的情况下,至少需要训练40万个批次才能达到复现精度,可能需要耗费几天的时间。如要尝试从零训练该模型,请耐心等待。
1.7 结果展示
以下展示的是该模型的部分去雾效果。展示图片的生成过程参照本文档的 3.5 部分实现。


2. 项目介绍
本项目基于paddlepaddle深度学习框架复现,我们将提供更加细节的训练流程,帮助有需要的人完成该模型的复现。
在这里我们提供了两种训练和测试模型的方式。在第三部分,我们将介绍基于PaddleVideo套件来复现模型的具体操作流程。在第四部分中,我们将提供在notebook中进行模型复现的全部代码,帮助读者理解模型构建和训练的流程。
本项目复现精度如下表所示,且仍可以通过更多的训练次数来获得更好的效果。
论文ITS: 13990SOTS/indoor: 5000.988636.39复现ITS: 13990SOTS/indoor: 5000.988535.42
本项目中已加载了室内去雾相关的数据集,并基于室内数据集对室内去雾模型进行复现。如有需要,可查阅以下文档,自行基于PaddleVideo套件或本项目第四部分提供的代码进行更多的复现操作。
说明文档链接:https://github.com/bitcjm/PaddleVideo/blob/new_branch/docs/zh-CN/model_zoo/estimation/ffa_ch.md
准备工作
为了使用该项目,你需要先在控制台输入以下命令将数据集解压出来。
 可图大模型
可图大模型
可图大模型(Kolors)是快手大模型团队自研打造的文生图AI大模型
 32 查看详情
32 查看详情 
unzip -oq /home/aistudio/data/data141970/indoor.zipunzip -oq /home/aistudio/data/data141952/clear.zipunzip -oq /home/aistudio/data/data141952/hazy.zip
注意: 第三部分和第四部分的模型的参数名是不同的,无法直接加载对方生成的模型参数。
3. 基于PaddleVideo套件进行复现
该部分我们将介绍基于PaddleVideo套件进行模型复现的详细流程。
PaddleVideo套件基于模块化的设计,提供丰富的视频算法实现、产业级的视频算法优化与应用,包括安防、体育、互联网、媒体等行业的动作定位与识别、行为分析、智能封面、视频标注、视频打标签等,涵盖动作识别与视频分类、动作定位、动作检测、多模态文本视频检索等技术。
github地址:https://github.com/PaddlePaddle/PaddleVideo
3.1 下载PaddleVideo套件
输入以下命令,从github上clone项目文件,转移到套件目录,切换分支。每次重启AI Studio环境都需要再输入下面两条命令来转移到套件目录并切换分支。
git clone https://github.com/bitcjm/PaddleVideo.gitcd PaddleVideogit checkout new_branch
3.2 环境配置
为了使用PaddleVideo套件,你需要在控制台输入以下命令来下载一些依赖。每次重启AI Studio环境都需要再次输入以下命令。
pip install avpip install decord
在configs/estimation/adds/FFA_cfg.yaml 中修改参数,在这里必须修改训练集/验证集和测试集的路径,
DATASET/train/file_path -> ‘/home/aistudio’
DATASET/valid/file_path -> ‘/home/aistudio/indoor’
DATASET/test/file_path -> ‘/home/aistudio/indoor’
3.3 输入以下命令开始训练
python main.py -c configs/estimation/adds/FFA_cfg.yaml --validate
如提示显存不足,可以更改aistudio的运行环境,使用更大显存的GPU,或在configs/estimation/adds/FFA_cfg.yaml 中修改batch_size参数为1
3.4 模型测试
对模型进行评估时,在控制台输入以下代码,下面代码中使用预训练模型的模型参数,也可以自行更改为训练过程中保存的模型参数:
python main.py --test -c configs/estimation/adds/FFA_cfg.yaml -w ../work/ITS_3_19_400000_transform.pdparams
3.5 使用TIPC框架进行小批量测试
在控制台按以下流程输入命令,即可在控制台看到预期的输出结果,可前往PaddleVideo/data/FFA/目录下的1440_6_dehazed.png查看去雾结果图。
样例图片和对应的预测(去雾)图已在第一部分中展示。
导出inference模型
python tools/export_model.py -c configs/estimation/adds/FFA_cfg.yaml -p ../work/ITS_3_19_400000_transform.pdparams -o inference/FFA
使用预测引擎推理
python tools/predict.py --input_file data/FFA/infer_example/ --config configs/estimation/adds/FFA_cfg.yaml --model_file inference/FFA/FFA.pdmodel --params_file inference/FFA/FFA.pdiparams --use_gpu=True --use_tensorrt=False
推理结束会默认保存下模型生成的去雾图像,并输出测试得到的ssim和psnr值。
预期的控制台输出:
pred dehazed image saved to: data/FFA/1440_6_dehazed.png ssim: 0.9845477287740326 psnr: 33.88653138903176
4. 基于notebook 进行模型复现
该部分我们将提供基于notebook进行FFA-Net模型复现的详细代码。所有用到的自己编写的代码都在notebook中,没有其他.py文件。
In [ ]
import paddlefrom paddle import nnimport paddle.nn.functional as Ffrom paddle.vision.models import vgg16import paddle.distributed as distimport numpy as npimport cv2from PIL import Imageimport matplotlib.pyplot as pltfrom scipy.signal import convolve2dimport mathimport randomimport timeimport os,syssys.path.append('.')sys.path.append('..')
In [ ]
paddle.device.set_device('gpu:0')print(paddle.device.get_device())
In [ ]
#创建ckpts文件夹ckpts = "./trained_models/"os.makedirs(ckpts, exist_ok=True)
4.1 定义评价函数
该部分,我们定义了psnr和ssim两种评价指标的计算方式
In [ ]
def matlab_style_gauss2D(shape=(3, 3), sigma=0.5): """ 2D gaussian mask - should give the same result as MATLAB's fspecial('gaussian',[shape],[sigma]) """ m, n = [(ss - 1.) / 2. for ss in shape] y, x = np.ogrid[-m:m + 1, -n:n + 1] h = np.exp(-(x * x + y * y) / (2. * sigma * sigma)) h[h 2: raise ValueError("Please input the images with 1 channel") im1 = np.clip(im1, 0, 1) im2 = np.clip(im2, 0, 1) im1 = np.around(im1, decimals=4) im2 = np.around(im2, decimals=4) M, N = im1.shape C1 = (k1 * L) ** 2 C2 = (k2 * L) ** 2 window = matlab_style_gauss2D(shape=(win_size, win_size), sigma=1.5) window = window / np.sum(np.sum(window)) if im1.dtype == np.uint8: im1 = np.double(im1) if im2.dtype == np.uint8: im2 = np.double(im2) mu1 = filter2(im1, window, 'same') mu2 = filter2(im2, window, 'same') mu1_sq = mu1 * mu1 mu2_sq = mu2 * mu2 mu1_mu2 = mu1 * mu2 sigma1_sq = filter2(im1 * im1, window, 'same') - mu1_sq sigma2_sq = filter2(im2 * im2, window, 'same') - mu2_sq sigmal2 = filter2(im1 * im2, window, 'same') - mu1_mu2 ssim_map = ((2 * mu1_mu2 + C1) * (2 * sigmal2 + C2)) / ((mu1_sq + mu2_sq + C1) * (sigma1_sq + sigma2_sq + C2)) return np.mean(ssim_map)# 评价函数
In [ ]
def psnr(pred, gt): pred = paddle.clip(pred, min=0, max=1) gt = paddle.clip(gt, min=0, max=1) imdff = np.asarray(pred - gt) rmse = math.sqrt(np.mean(imdff ** 2)) if rmse == 0: return 100 return 20 * math.log10( 1.0 / rmse)
In [ ]
4.2 数据输入模块
该部分我们定义了RESIDE_Dataset类,并基于Paddle的API创建了数据集对象。
In [ ]
from paddle.vision.transforms import RandomHorizontalFlip,rotate,ToTensor,Normalize,CenterCrop,RandomCrop,cropcrop_size=240class RESIDE_Dataset(paddle.io.Dataset): def __init__(self,path,train,size=crop_size,format='.png'): super(RESIDE_Dataset,self).__init__() self.size=size print('crop size',size) self.train=train self.format=format self.haze_imgs_dir=os.listdir(os.path.join(path,'hazy')) self.haze_imgs=[os.path.join(path,'hazy',img) for img in self.haze_imgs_dir] self.clear_dir=os.path.join(path,'clear') def __getitem__(self, index): path = self.haze_imgs[index] haze=Image.open(path) if isinstance(self.size,int): while haze.size[0]<self.size or haze.size[1]<self.size : index=random.randint(0,2000) haze=Image.open(self.haze_imgs[index]) img = path if sys.platform == 'win32': id=img.split('')[-1].split('_')[0] else: id=img.split('/')[-1].split('_')[0] clear_name=id+self.format clear=Image.open(os.path.join(self.clear_dir,clear_name)) clear = CenterCrop(haze.size[::-1])(clear) if not isinstance(self.size,str): transform = RandomCrop(self.size) i,j,h,w=transform._get_param(haze,output_size=(self.size,self.size)) haze = np.array(haze)[i:i+h,j:j+w,:] clear = np.array(clear)[i:i+h,j:j+w,:] haze, clear = self.augData(haze, clear) return np.array(haze).astype('float32'),np.array(clear).astype('float32') def augData(self,data,target): if self.train: rand_hor=random.randint(0,1) rand_rot=random.randint(0,3) data=RandomHorizontalFlip(rand_hor)(data) target=RandomHorizontalFlip(rand_hor)(target) if rand_rot: data=rotate(data,90*rand_rot) target=rotate(target,90*rand_rot) data=ToTensor()(data) data=Normalize(mean=[0.64, 0.6, 0.58],std=[0.14,0.15, 0.152])(data) target=ToTensor()(target) return data ,target def __len__(self): return len(self.haze_imgs)
In [ ]
TRAINDIR = '/home/aistudio'TESTDIR = '/home/aistudio/indoor'# 创建数据读取类train_dataset = RESIDE_Dataset(TRAINDIR,train=True,size=240)test_dataset = RESIDE_Dataset(TESTDIR,train=False,size='whole img')# 使用paddle.io.DataLoader创建数据读取器,并设置batchsize,进程数量num_workers等参数train_loader = paddle.io.DataLoader(train_dataset, batch_size=2, shuffle=True, num_workers=0)test_loader = paddle.io.DataLoader(test_dataset, batch_size=1, shuffle=False, num_workers=0)
In [ ]
4.3 定义模型的网络结构
这部分可以参照第一部分模型简介进行理解
In [ ]
weight_ins = paddle.ParamAttr(initializer=paddle.nn.initializer.Normal(0., 0.02),trainable=True)bias_ins = paddle.ParamAttr(initializer=paddle.nn.initializer.Constant(0.0),trainable=True)
In [ ]
def default_conv(in_channels, out_channels, kernel_size, bias=True): return nn.Conv2D(in_channels, out_channels, kernel_size,padding=(kernel_size//2),weight_attr=weight_ins,bias_attr=bias_ins)
In [ ]
class PALayer(paddle.nn.Layer): def __init__(self, channel): super(PALayer, self).__init__() self.pa = nn.Sequential( nn.Conv2D(channel, channel // 8, 1, padding=0, weight_attr=weight_ins, bias_attr=bias_ins), nn.ReLU(), nn.Conv2D(channel // 8, 1, 1, padding=0, weight_attr=weight_ins, bias_attr=bias_ins), nn.Sigmoid() ) def forward(self, x): y = self.pa(x) return x * y
In [ ]
class CALayer(paddle.nn.Layer): def __init__(self, channel): super(CALayer, self).__init__() self.avg_pool = nn.AdaptiveAvgPool2D(1) self.ca = nn.Sequential( nn.Conv2D(channel, channel // 8, 1, padding=0, weight_attr=weight_ins, bias_attr=bias_ins), nn.ReLU(), nn.Conv2D(channel // 8, channel, 1, padding=0, weight_attr=weight_ins, bias_attr=bias_ins), nn.Sigmoid() ) def forward(self, x): y = self.avg_pool(x) y = self.ca(y) return x * y
In [ ]
class Block(paddle.nn.Layer): def __init__(self,conv, dim, kernel_size): super(Block, self).__init__() self.conv1=conv(dim, dim, kernel_size) self.act1=nn.ReLU() self.conv2=conv(dim,dim,kernel_size) self.calayer=CALayer(dim) self.palayer=PALayer(dim) def forward(self, x): res=self.act1(self.conv1(x)) res=res+x res=self.conv2(res) res=self.calayer(res) res=self.palayer(res) res += x return res
In [ ]
class Group(paddle.nn.Layer): def __init__(self, conv,dim, kernel_size, blocks): super(Group, self).__init__() modules = [Block(conv, dim, kernel_size) for _ in range(blocks)] modules.append(conv(dim, dim, kernel_size)) self.gp = paddle.nn.Sequential(*modules) def forward(self, x): res = self.gp(x) res += x return res
In [ ]
class FFA(paddle.nn.Layer): def __init__(self,gps,blocks,conv=default_conv): super(FFA, self).__init__() self.gps=gps self.dim=64 kernel_size=3 pre_process = [conv(3, self.dim, kernel_size)] assert self.gps==3 self.g1= Group(conv, self.dim, kernel_size,blocks=blocks) self.g2= Group(conv, self.dim, kernel_size,blocks=blocks) self.g3= Group(conv, self.dim, kernel_size,blocks=blocks) self.ca=nn.Sequential(*[ nn.AdaptiveAvgPool2D(1), nn.Conv2D(self.dim*self.gps,self.dim//16,1,padding=0, weight_attr=weight_ins, bias_attr=bias_ins), nn.ReLU(), nn.Conv2D(self.dim//16, self.dim*self.gps, 1, padding=0, weight_attr=weight_ins, bias_attr=bias_ins), nn.Sigmoid() ]) self.palayer=PALayer(self.dim) post_precess = [ conv(self.dim, self.dim, kernel_size), conv(self.dim, 3, kernel_size)] self.pre = nn.Sequential(*pre_process) self.post = nn.Sequential(*post_precess) def forward(self, x1): x = self.pre(x1) res1=self.g1(x) res2=self.g2(res1) res3=self.g3(res2) w=self.ca(paddle.concat([res1,res2,res3],axis=1)) w = paddle.reshape(w, [-1, self.gps, self.dim,1,1]) out=w[:,0,::]*res1+w[:,1,::]*res2+w[:,2,::]*res3 out=self.palayer(out) x=self.post(out) return x + x1
In [ ]
4.4 定义损失函数
损失函数默认只使用L1损失,如要使用feature_loss 则将F_loss的值改为True
In [ ]
F_loss = False
In [ ]
class LossNetwork(paddle.nn.Layer): def __init__(self, vgg_model): super(LossNetwork, self).__init__() self.vgg_layers = vgg_model self.layer_name_mapping = { '3': "relu1_2", '8': "relu2_2", '15': "relu3_3" } def output_features(self, x): output = {} for name in range(len(self.vgg_layers)): x = self.vgg_layers[name](x) if str(name) in self.layer_name_mapping: output[self.layer_name_mapping[str(name)]] = x return list(output.values()) def forward(self, dehaze, gt): loss = [] dehaze_features = self.output_features(dehaze) gt_features = self.output_features(gt) for dehaze_feature, gt_feature in zip(dehaze_features, gt_features): loss.append(F.mse_loss(dehaze_feature, gt_feature)) return sum(loss)/len(loss)criterion = []criterion.append(nn.L1Loss(reduction='mean'))if F_loss: #特征损失选项,默认为False,要起作用除了这里改为True,在下面的train函数里也要将相应选项改为True vgg_model = paddle.vision.models.vgg16(pretrained=False) path_state_dict = 'data/data141970/vgg16_pretrained_weight.pdparams' load_state_dict = paddle.load(path_state_dict) vgg_model.load_dict({k.replace('module.',''):v for k,v in load_state_dict.items()}) vgg_model = vgg_model.features[:16] for param in vgg_model.parameters(): param.requires_grad = False criterion.append(LossNetwork(vgg_model))
In [ ]
#展示损失函数包含哪些criterion
4.5 定义训练和测试的主函数train和test
In [ ]
#学习率下降策略def lr_schedule_cosdecay(t,T,init_lr=0.0001): lr=0.5*(1+math.cos(t*math.pi/T))*init_lr return lr
In [ ]
global_lr = 0.0001max_ssim = 0max_psnr = 0def train(net, loader_train, loader_test, optim, criterion, start_step, end_step, lr_input=0.0001): start_time = time.time() losses = [] global max_ssim global max_psnr ssims = [] psnrs = [] print(f'start_step:{start_step} start training ---') step = start_step -1 T = end_step for epoch in range(50000000): if step > end_step: break for i, (x, y) in enumerate(loader_train): step += 1 if step > end_step: break else: net.train() lr = lr_input if True: lr = lr_schedule_cosdecay(step, T, lr_input) optim.set_lr(lr) x = paddle.to_tensor(x) y = paddle.to_tensor(y) out = net(x) loss = criterion[0](out, y) if F_loss: # 特征损失选项,默认为False,要起作用除了这里改为True,在上面构建损失函数时也要将相应选项改为True loss2 = criterion[1](out, y) loss = loss + 0.04 * loss2 loss.backward() optim.step() optim.clear_grad() print( f'step :{step}/{end_step}| train loss : {loss.item():.5f}| lr : {lr:.7f}| time_used :{(time.time() - start_time) / 60 :.1f}min', end='', flush=True) if step % 5000 == 0 or step == 20 or step == 200 or step == 500 or step == 1000 or end_step - step == 1000 or end_step - step == 200 or end_step - step == 500: # opt.eval_step with paddle.no_grad(): ssim_eval, psnr_eval, loss_eval = test(net, loader_test, 50) print(f'step :{step}/{end_step}| eval loss:{loss_eval:.4f} |ssim:{ssim_eval:.4f}| psnr:{psnr_eval:.4f}') ssims.append(ssim_eval) psnrs.append(psnr_eval) model_name = 'ITS' + '_' + '3' + '_' + '19_'+ str(step) + '_step1' model_dir = ckpts + model_name + '.pdparams' if ssim_eval > max_ssim and psnr_eval > max_psnr: paddle.save({ 'step': step, 'ssims': ssim_eval, 'psnrs': psnr_eval, 'losses': losses, 'model': net.state_dict() }, model_dir) print(f'model saved at step :{step}|ssim:{ssim_eval:.4f}| psnr:{psnr_eval:.4f}') max_ssim = max(max_ssim, ssim_eval) max_psnr = max(max_psnr, psnr_eval) if i == len(loader_train)-1: breakdef test(net,loader_test,step): net.eval() ssims=[] psnrs=[] losses = [] print('testing:',end='') for i ,(inputs,targets) in enumerate(loader_test): if i % 10 == 0: print('.',end='') inputs = paddle.to_tensor(inputs) targets = paddle.to_tensor(targets) pred=net(inputs) targets.stop_gradient=True pred.stop_gradient=True loss=criterion[0](pred,targets) losses.append(loss.cpu().numpy()) ssim1=0 if not(inputs.shape==targets.shape): continue for j in range(3): ssim1 += compute_ssim(np.transpose(np.squeeze(pred.cpu().numpy(), 0), (1, 2, 0))[:, :, j], np.transpose(np.squeeze(targets.cpu().numpy(), 0), (1, 2, 0))[:, :, j]).item() ssim1 /= 3 psnr1=psnr(pred,targets) ssims.append(ssim1) psnrs.append(psnr1) if i == step: break return np.mean(ssims) ,np.mean(psnrs), np.mean(losses)
In [ ]
4.6 开始训练和测试
In [ ]
loader_train=train_loaderloader_test=test_loader
In [ ]
net=FFA(gps=3,blocks=19)
4.6.1 加载预训练模型的模型参数进行测试
In [ ]
path_state_dict = 'work/ITS_weight_notebook.pdparams'load_state_dict = paddle.load(path_state_dict)net.load_dict({k.replace('module.',''):v for k,v in load_state_dict.items()})
In [ ]
#为了节约时间,这里和train()函数中调用test()函数的地方都默认只测试50张图片,也可以修改该参数,修改范围为1-500 #建议在训练初期采用默认值,训练后期为了保存最优的模型,将该值修改为500,进行更全面地评估 with paddle.no_grad(): ssim_eval, psnr_eval, loss_eval = test(net, loader_test, 50)print(f'step :0 | eval loss:{loss_eval:.4f} |ssim:{ssim_eval:.4f}| psnr:{psnr_eval:.4f}')
预期测试结果:
testing:……
step :0 | eval loss:0.0099 |ssim:0.9888| psnr:36.7091
4.6.2 从头开始训练
In [ ]
In [ ]
#重新创建模型net=FFA(gps=3,blocks=19)
In [ ]
#创建优化器optimizer = paddle.optimizer.Adam(parameters=net.parameters(),learning_rate=0.0001, beta1=0.9, beta2=0.999,epsilon=1e-08)optimizer.clear_grad()
In [33]
#开始训练train(net,loader_train,loader_test,optimizer,criterion,1,500000,lr_input=0.0001)
代码解释
4.6.3 对自己当前训练的最终模型进行测试
In [ ]
with paddle.no_grad(): ssim_eval, psnr_eval, loss_eval = test(net, loader_test, 500)print(f'step :0 | eval loss:{loss_eval:.4f} |ssim:{ssim_eval:.4f}| psnr:{psnr_eval:.4f}')
4.6.4 加载训练过程中保存的模型参数进行测试
In [ ]
path_state_dict = 'trained_models/your_weight.pdparams'load_state_dict = paddle.load(path_state_dict)net.load_dict(load_state_dict)
In [ ]
with paddle.no_grad(): ssim_eval, psnr_eval, loss_eval = test(net, loader_test, 500)print(f'step :0 | eval loss:{loss_eval:.4f} |ssim:{ssim_eval:.4f}| psnr:{psnr_eval:.4f}')
In [ ]
以上就是【第六届论文复现赛104题】FFA-NET图像去雾模型 paddle复现的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/318597.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 

























