
注意力机制被视为视觉Transformer成功关键,但研究质疑其必要性。通过零参数零计算的Shift操作构建ShiftViT,替代注意力层,在分类、检测和分割等任务中表现媲美甚至优于Swin Transformer,表明注意力机制或非ViT成功关键,未来应关注其剩余部分。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

ShiftViT:采用简单高效的移位操作证明Attention是否必要
摘要
注意力机制被广泛认为是视觉Transformer成功的关键,因为它提供了一种灵活而强大的方式来建模空间关系。然而,注意力机制真的是ViT不可或缺的一部分吗?它能被其他替代品取代吗?为了揭开注意力机制的神秘面纱,我们将其简化为一个极其简单的例子:ZERO FLOP和ZERO parameter。具体来说,我们要重新审视Shift操作。它不包含任何参数或算术计算。唯一的操作是在相邻特性之间交换一小部分通道。基于这个简单的操作,我们构建了一个新的骨干网络,即ShiftViT,其中的注意层被Shift操作所取代。令人惊讶的是,ShiftViT在几个主流任务中工作得相当好,例如,分类,检测和分割。性能与强大的基线Swin Transformer相当,甚至更好。这些结果表明,注意力机制可能不是使ViT成功的关键因素。它甚至可以被零参数操作取代。在今后的工作中,我们应该更多地关注ViT的剩余部分。
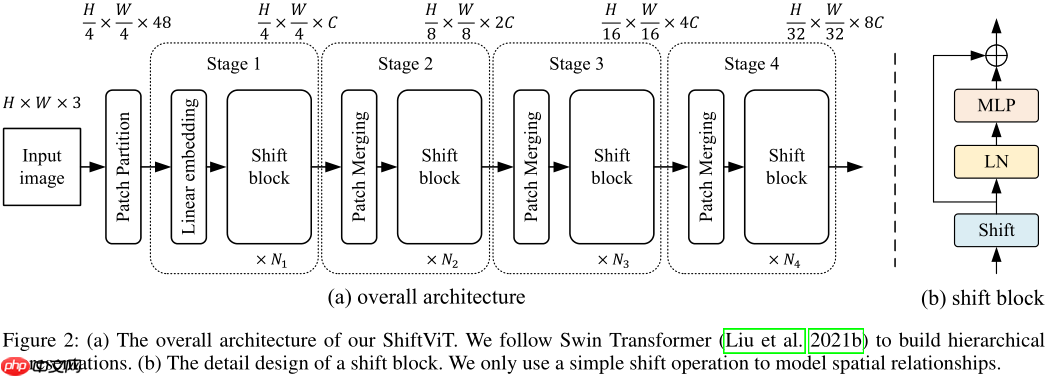
1. ShiftViT
为验证Transformer中的Attention机制是否是必要的,ShiftViT采用一个简单高效的Shift操作来代替Attention机制,Shift操作是沿上下左右对Shift部分进行偏移操作(与S2MLP特别相似,不同的是S2MLP将所有都采用Shift操作,而ShiftViT仅对一部分使用Shift操作):
z^[0:H,1:W,0:γC]←z[0:H,0:W−1,0:γC]z^[0:H,0:W−1,γC:2γC]←z[0:H,1:W,γC:2γC]z^[0:H−1,0:W,2γC:3γC]←z[1:H,0:W,2γC:3γC]z^[1:H,0:W,3γC:4γC]←z[0:H−1,0:W,3γC:4γC]z^[0:H,0:W,4γC:C]←z[0:H,0:W,4γC:C]z^[0:H,1:W,0:γC]z^[0:H,0:W−1,γC:2γC]z^[0:H−1,0:W,2γC:3γC]z^[1:H,0:W,3γC:4γC]z^[0:H,0:W,4γC:C]←z[0:H,0:W−1,0:γC]←z[0:H,1:W,γC:2γC]←z[1:H,0:W,2γC:3γC]←z[0:H−1,0:W,3γC:4γC]←z[0:H,0:W,4γC:C]
2. 代码复现
2.1 下载并导入所需的库
In [ ]
!pip install einops-0.3.0-py3-none-any.whl
In [ ]
%matplotlib inlineimport paddleimport numpy as npimport matplotlib.pyplot as pltfrom paddle.vision.datasets import Cifar10from paddle.vision.transforms import Transposefrom paddle.io import Dataset, DataLoaderfrom paddle import nnimport paddle.nn.functional as Fimport paddle.vision.transforms as transformsimport osimport matplotlib.pyplot as pltfrom matplotlib.pyplot import figurefrom einops.layers.paddle import Rearrange, Reducefrom einops import rearrange
2.2 创建数据集
In [16]
train_tfm = transforms.Compose([ transforms.Resize((230, 230)), transforms.ColorJitter(brightness=0.2,contrast=0.2, saturation=0.2), transforms.RandomResizedCrop(224, scale=(0.6, 1.0)), transforms.RandomHorizontalFlip(0.5), transforms.RandomRotation(20), transforms.ToTensor(), transforms.Normalize(mean=(0.485, 0.456, 0.406), std=(0.229, 0.224, 0.225)),])test_tfm = transforms.Compose([ transforms.Resize((224, 224)), transforms.ToTensor(), transforms.Normalize(mean=(0.485, 0.456, 0.406), std=(0.229, 0.224, 0.225)),])
In [17]
paddle.vision.set_image_backend('cv2')# 使用Cifar10数据集train_dataset = Cifar10(data_file='data/data152754/cifar-10-python.tar.gz', mode='train', transform = train_tfm, )val_dataset = Cifar10(data_file='data/data152754/cifar-10-python.tar.gz', mode='test',transform = test_tfm)print("train_dataset: %d" % len(train_dataset))print("val_dataset: %d" % len(val_dataset))
train_dataset: 50000val_dataset: 10000
In [18]
batch_size=128
In [19]
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True, drop_last=True, num_workers=4)val_loader = DataLoader(val_dataset, batch_size=batch_size, shuffle=False, drop_last=False, num_workers=4)
2.3 模型的创建
2.3.1 标签平滑
In [8]
class LabelSmoothingCrossEntropy(nn.Layer): def __init__(self, smoothing=0.1): super().__init__() self.smoothing = smoothing def forward(self, pred, target): confidence = 1. - self.smoothing log_probs = F.log_softmax(pred, axis=-1) idx = paddle.stack([paddle.arange(log_probs.shape[0]), target], axis=1) nll_loss = paddle.gather_nd(-log_probs, index=idx) smooth_loss = paddle.mean(-log_probs, axis=-1) loss = confidence * nll_loss + self.smoothing * smooth_loss return loss.mean()
2.3.2 DropPath
In [8]
def drop_path(x, drop_prob=0.0, training=False): """ Drop paths (Stochastic Depth) per sample (when applied in main path of residual blocks). the original name is misleading as 'Drop Connect' is a different form of dropout in a separate paper... See discussion: https://github.com/tensorflow/tpu/issues/494#issuecomment-532968956 ... """ if drop_prob == 0.0 or not training: return x keep_prob = paddle.to_tensor(1 - drop_prob) shape = (paddle.shape(x)[0],) + (1,) * (x.ndim - 1) random_tensor = keep_prob + paddle.rand(shape, dtype=x.dtype) random_tensor = paddle.floor(random_tensor) # binarize output = x.divide(keep_prob) * random_tensor return outputclass DropPath(nn.Layer): def __init__(self, drop_prob=None): super(DropPath, self).__init__() self.drop_prob = drop_prob def forward(self, x): return drop_path(x, self.drop_prob, self.training)
2.3.3 ShiftViT模型的创建
In [9]
class MLP(nn.Layer): def __init__(self, in_features, hidden_features=None, out_features=None,act_layer=nn.GELU, drop=0.): super().__init__() out_features = out_features or in_features hidden_features = hidden_features or in_features self.fc1 = nn.Conv2D(in_features, hidden_features, 1) self.act = act_layer() self.fc2 = nn.Conv2D(hidden_features, out_features, 1) self.drop = nn.Dropout(drop) def forward(self, x): x = self.fc1(x) x = self.act(x) x = self.drop(x) x = self.fc2(x) x = self.drop(x) return x
In [10]
class Shift(nn.Layer): def __init__(self, n_div): super().__init__() self.n_div = n_div def forward(self, x): B, C, H, W = x.shape g = C // self.n_div # out = paddle.zeros_like(x) x[:, g * 0:g * 1, :, :-1] = x[:, g * 0:g * 1, :, 1:] # shift left x[:, g * 1:g * 2, :, 1:] = x[:, g * 1:g * 2, :, :-1] # shift right x[:, g * 2:g * 3, :-1, :] = x[:, g * 2:g * 3, 1:, :] # shift up x[:, g * 3:g * 4, 1:, :] = x[:, g * 3:g * 4, :-1, :] # shift down x[:, g * 4:, :, :] = x[:, g * 4:, :, :] # no shift return x
In [11]
class ShiftViTBlock(nn.Layer): def __init__(self, dim, n_div=12, mlp_ratio=4., drop=0., drop_path=0., act_layer=nn.GELU, norm_layer=nn.LayerNorm, input_resolution=None): super().__init__() self.input_resolution = input_resolution self.mlp_ratio = mlp_ratio self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity() self.norm = norm_layer(dim) mlp_hidden_dim = int(dim * mlp_ratio) self.mlp = MLP(in_features=dim, hidden_features=mlp_hidden_dim, act_layer=act_layer, drop=drop) self.n_div = n_div self.shift = Shift(n_div) def forward(self, x): x = self.shift(x) shortcut = x x = shortcut + self.drop_path(self.mlp(self.norm(x.transpose([0, 2, 3, 1])).transpose([0, 3, 1, 2]))) return x
In [12]
class BasicLayer(nn.Layer): def __init__(self, dim, input_resolution, depth, n_div=12, mlp_ratio=4., drop=0., drop_path=None, norm_layer=None, downsample=True, act_layer=nn.GELU): super(BasicLayer, self).__init__() self.dim = dim self.input_resolution = input_resolution self.depth = depth # build blocks self.blocks = nn.LayerList([ ShiftViTBlock(dim=dim, n_div=n_div, mlp_ratio=mlp_ratio, drop=drop, drop_path=drop_path[i], norm_layer=norm_layer, act_layer=act_layer, input_resolution=input_resolution) for i in range(depth) ]) # patch merging layer if downsample: self.downsample = nn.Sequential( nn.GroupNorm(num_groups=1, num_channels=dim), nn.Conv2D(dim, dim * 2, kernel_size=2, stride=2,bias_attr=False) ) else: self.downsample = None def forward(self, x): for blk in self.blocks: x = blk(x) if self.downsample is not None: x = self.downsample(x) return x
In [13]
class ShiftViT(nn.Layer): def __init__(self,n_div=12, img_size=224, patch_size=4, in_chans=3, num_classes=1000, embed_dim=96, depths=(2, 2, 6, 2), mlp_ratio=2., drop_rate=0., drop_path_rate=0.1, patch_norm=True, **kwargs): super().__init__() norm_layer = nn.LayerNorm act_layer = nn.GELU self.num_classes = num_classes self.num_layers = len(depths) self.embed_dim = embed_dim self.patch_norm = patch_norm self.num_features = int(embed_dim * 2 ** (self.num_layers - 1)) self.mlp_ratio = mlp_ratio # split image into non-overlapping patches self.patch_embed = nn.Sequential( nn.Conv2D(in_chans, embed_dim, kernel_size=patch_size, stride=patch_size), Rearrange('b c h w->b h w c'), nn.LayerNorm(embed_dim) if self.patch_norm else nn.Identity(), Rearrange('b h w c->b c h w') ) # num_patches = self.patch_embed.num_patches patches_resolution = [img_size // patch_size, img_size // patch_size] self.patches_resolution = patches_resolution self.pos_drop = nn.Dropout(p=drop_rate) # stochastic depth decay rule dpr = [x.item() for x in paddle.linspace(0, drop_path_rate, sum(depths))] # build layers self.layers = nn.LayerList() for i_layer in range(self.num_layers): layer = BasicLayer(dim=int(embed_dim * 2 ** i_layer), n_div=n_div, input_resolution=(patches_resolution[0] // (2 ** i_layer), patches_resolution[1] // (2 ** i_layer)), depth=depths[i_layer], mlp_ratio=self.mlp_ratio, drop=drop_rate, drop_path=dpr[sum(depths[:i_layer]):sum(depths[:i_layer + 1])], norm_layer=norm_layer, downsample=(i_layer 0 else nn.Identity() self.apply(self._init_weights) def _init_weights(self, m): tn = nn.initializer.TruncatedNormal(std=.02) zeros = nn.initializer.Constant(0.) ones = nn.initializer.Constant(1.) if isinstance(m, nn.Linear): tn(m.weight) if isinstance(m, nn.Linear) and m.bias is not None: zeros(m.bias) elif isinstance(m, (nn.Conv1D, nn.Conv2D)): tn(m.weight) if m.bias is not None: zeros(m.bias) elif isinstance(m, (nn.LayerNorm, nn.GroupNorm)): zeros(m.bias) ones(m.weight) def forward_features(self, x): x = self.patch_embed(x) x = self.pos_drop(x) for layer in self.layers: x = layer(x) x = self.norm(x.transpose([0, 2, 3, 1])).transpose([0, 3, 1, 2]) x = self.avgpool(x) x = paddle.flatten(x, 1) return x def forward(self, x): x = self.forward_features(x) x = self.head(x) return x
2.3.4 模型的参数
In [ ]
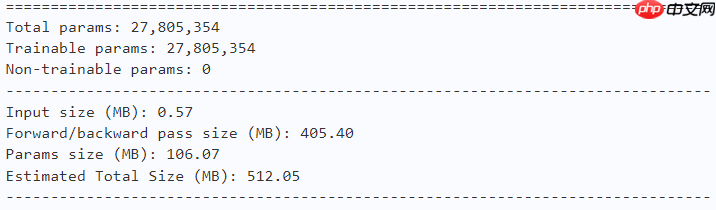
# Shift-Tmodel = ShiftViT(n_div=12, embed_dim=96, depths=(6, 8, 18, 6), num_classes=10)paddle.summary(model, (1, 3, 224, 224))
In [ ]
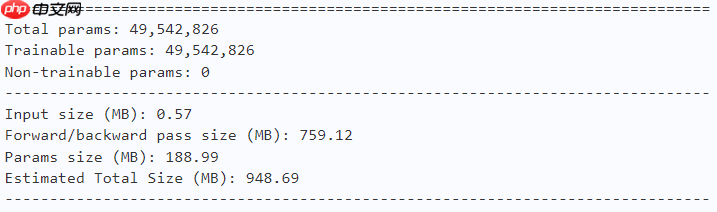
# Shift-Smodel = ShiftViT(n_div=12, embed_dim=96, depths=(10, 18, 36, 10), num_classes=10)paddle.summary(model, (1, 3, 224, 224))
In [ ]
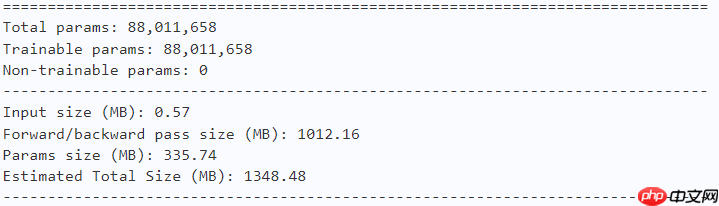
# Shift-Bmodel = ShiftViT(n_div=16, embed_dim=128, depths=(10, 18, 36, 10), num_classes=10)paddle.summary(model, (1, 3, 224, 224))
 YOO必优科技-AI写作
YOO必优科技-AI写作
智能图文创作平台,让内容创作更简单
 14 查看详情
14 查看详情  In [ ]
In [ ]
# Shift-oursmodel = ShiftViT(n_div=12, embed_dim=96, depths=(3, 4, 9, 3), num_classes=10)paddle.summary(model, (1, 3, 224, 224))
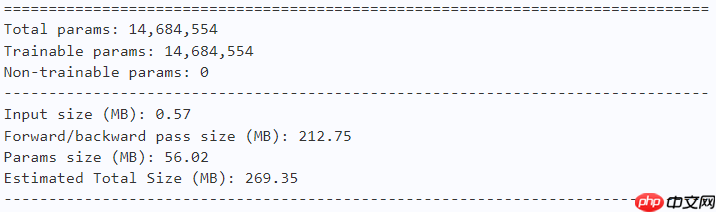
2.4 训练
In [19]
learning_rate = 0.001n_epochs = 100paddle.seed(42)np.random.seed(42)
In [ ]
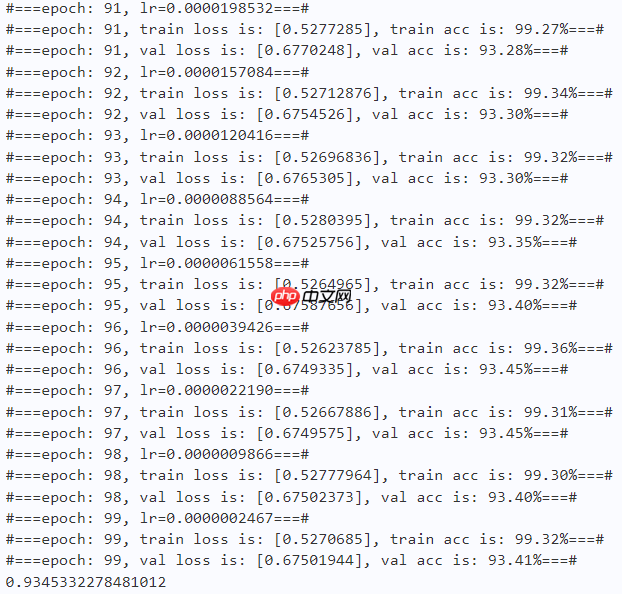
work_path = 'work/model'# Shift-oursmodel = ShiftViT(n_div=12, embed_dim=96, depths=(3, 4, 9, 3), num_classes=10)criterion = LabelSmoothingCrossEntropy()scheduler = paddle.optimizer.lr.CosineAnnealingDecay(learning_rate=learning_rate, T_max=50000 // batch_size * n_epochs, verbose=False)optimizer = paddle.optimizer.Adam(parameters=model.parameters(), learning_rate=scheduler, weight_decay=1e-5)gate = 0.0threshold = 0.0best_acc = 0.0val_acc = 0.0loss_record = {'train': {'loss': [], 'iter': []}, 'val': {'loss': [], 'iter': []}} # for recording lossacc_record = {'train': {'acc': [], 'iter': []}, 'val': {'acc': [], 'iter': []}} # for recording accuracyloss_iter = 0acc_iter = 0for epoch in range(n_epochs): # ---------- Training ---------- model.train() train_num = 0.0 train_loss = 0.0 val_num = 0.0 val_loss = 0.0 accuracy_manager = paddle.metric.Accuracy() val_accuracy_manager = paddle.metric.Accuracy() print("#===epoch: {}, lr={:.10f}===#".format(epoch, optimizer.get_lr())) for batch_id, data in enumerate(train_loader): x_data, y_data = data labels = paddle.unsqueeze(y_data, axis=1) logits = model(x_data) loss = criterion(logits, y_data) acc = accuracy_manager.compute(logits, labels) accuracy_manager.update(acc) if batch_id % 10 == 0: loss_record['train']['loss'].append(loss.numpy()) loss_record['train']['iter'].append(loss_iter) loss_iter += 1 loss.backward() optimizer.step() scheduler.step() optimizer.clear_grad() train_loss += loss train_num += len(y_data) total_train_loss = (train_loss / train_num) * batch_size train_acc = accuracy_manager.accumulate() acc_record['train']['acc'].append(train_acc) acc_record['train']['iter'].append(acc_iter) acc_iter += 1 # Print the information. print("#===epoch: {}, train loss is: {}, train acc is: {:2.2f}%===#".format(epoch, total_train_loss.numpy(), train_acc*100)) # ---------- Validation ---------- model.eval() for batch_id, data in enumerate(val_loader): x_data, y_data = data labels = paddle.unsqueeze(y_data, axis=1) with paddle.no_grad(): logits = model(x_data) loss = criterion(logits, y_data) acc = val_accuracy_manager.compute(logits, labels) val_accuracy_manager.update(acc) val_loss += loss val_num += len(y_data) total_val_loss = (val_loss / val_num) * batch_size loss_record['val']['loss'].append(total_val_loss.numpy()) loss_record['val']['iter'].append(loss_iter) val_acc = val_accuracy_manager.accumulate() acc_record['val']['acc'].append(val_acc) acc_record['val']['iter'].append(acc_iter) print("#===epoch: {}, val loss is: {}, val acc is: {:2.2f}%===#".format(epoch, total_val_loss.numpy(), val_acc*100)) # ===================save==================== if val_acc > best_acc: best_acc = val_acc paddle.save(model.state_dict(), os.path.join(work_path, 'best_model.pdparams')) paddle.save(optimizer.state_dict(), os.path.join(work_path, 'best_optimizer.pdopt'))print(best_acc)paddle.save(model.state_dict(), os.path.join(work_path, 'final_model.pdparams'))paddle.save(optimizer.state_dict(), os.path.join(work_path, 'final_optimizer.pdopt'))
2.5 结果分析
In [21]
def plot_learning_curve(record, title='loss', ylabel='CE Loss'): ''' Plot learning curve of your CNN ''' maxtrain = max(map(float, record['train'][title])) maxval = max(map(float, record['val'][title])) ymax = max(maxtrain, maxval) * 1.1 mintrain = min(map(float, record['train'][title])) minval = min(map(float, record['val'][title])) ymin = min(mintrain, minval) * 0.9 total_steps = len(record['train'][title]) x_1 = list(map(int, record['train']['iter'])) x_2 = list(map(int, record['val']['iter'])) figure(figsize=(10, 6)) plt.plot(x_1, record['train'][title], c='tab:red', label='train') plt.plot(x_2, record['val'][title], c='tab:cyan', label='val') plt.ylim(ymin, ymax) plt.xlabel('Training steps') plt.ylabel(ylabel) plt.title('Learning curve of {}'.format(title)) plt.legend() plt.show()
2.5.1 loss和acc曲线
In [22]
plot_learning_curve(loss_record, title='loss', ylabel='CE Loss')
In [23]
plot_learning_curve(acc_record, title='acc', ylabel='Accuracy')
In [24]
import timework_path = 'work/model'model = ShiftViT(n_div=12, embed_dim=96, depths=(3, 4, 9, 3), num_classes=10)model_state_dict = paddle.load(os.path.join(work_path, 'best_model.pdparams'))model.set_state_dict(model_state_dict)model.eval()aa = time.time()for batch_id, data in enumerate(val_loader): x_data, y_data = data labels = paddle.unsqueeze(y_data, axis=1) with paddle.no_grad(): logits = model(x_data)bb = time.time()print("Throughout:{}".format(int(len(val_dataset)//(bb - aa))))
Throughout:794
2.5.2 预测与真实标签比较
In [25]
def get_cifar10_labels(labels): """返回CIFAR10数据集的文本标签。""" text_labels = [ 'airplane', 'automobile', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck'] return [text_labels[int(i)] for i in labels]
In [26]
def show_images(imgs, num_rows, num_cols, pred=None, gt=None, scale=1.5): """Plot a list of images.""" figsize = (num_cols * scale, num_rows * scale) _, axes = plt.subplots(num_rows, num_cols, figsize=figsize) axes = axes.flatten() for i, (ax, img) in enumerate(zip(axes, imgs)): if paddle.is_tensor(img): ax.imshow(img.numpy()) else: ax.imshow(img) ax.axes.get_xaxis().set_visible(False) ax.axes.get_yaxis().set_visible(False) if pred or gt: ax.set_title("pt: " + pred[i] + "ngt: " + gt[i]) return axes
In [27]
work_path = 'work/model'X, y = next(iter(DataLoader(val_dataset, batch_size=18)))model = ShiftViT(n_div=12, embed_dim=96, depths=(3, 4, 9, 3), num_classes=10)model_state_dict = paddle.load(os.path.join(work_path, 'best_model.pdparams'))model.set_state_dict(model_state_dict)model.eval()logits = model(X)y_pred = paddle.argmax(logits, -1)X = paddle.transpose(X, [0, 2, 3, 1])axes = show_images(X.reshape((18, 224, 224, 3)), 1, 18, pred=get_cifar10_labels(y_pred), gt=get_cifar10_labels(y))plt.show()
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
3. 对比实验
ShiftViT146845540.93453Swin145415000.86659
注:Swin代码来自浅析 Swin Transformer,实验结果在main-Copy2.ipynb
总结
本文用了一个简单的Shift操作证明了Vision Transformer中的Attention不是必要的,与Swin在参数可比的情况下精度高了0.06794(小数据集如CIFAR10上ShiftViT比Swin优势明显,在大数据集上ShiftViT与Swin性能差不多)

以上就是ShiftViT:采用简单高效的移位操作证明Attention是否必要的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/319801.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 

























